
思考支援:雑誌連載の内容:第28回 |
今回と次回の2回で、個々の項目が持つデータ属性について解説していこう。情報中心システムでは、いろいろな処理が自動化されて、非常に使いやすくなっている。これを実現するためには、知識ベースの項目定義を利用するが、それだけでは不十分だ。データの属性を適切に設定し、それを参照することで、自動化の度合いを高めるといったことも実現する。また、より適切な表現を自動生成したり、資源を有効に利用するのにも役立つ。
情報中心システムでは、多くの新機能や自動化を実現するには、情報を細かい単位で扱う必要がある。この自動化を手助けするのが、知識ベース内の項目定義や処理定義だ。しかし、これだけではまだまだ足りないことがある。より適切な処理を施したり、よりよい表現にブラッシュアップするためには、個々のデータがどうちがうのかを少しでも考慮する必要がある。
そこで登場するのが、データごとに設定が可能なデータ属性だ(図1)。既存のシステムのファイル属性を、個々の項目ごとに持てるような仕組みと考えてよい。ただし、細かなデータで個別に設定できるため、ファイルの属性とはまったく比べものにならないくらい、広い範囲で利用できる。
図1、データ属性を設定する機能の画面イメージ。設定対象の内容を確認しながら、目的の属性を変更する
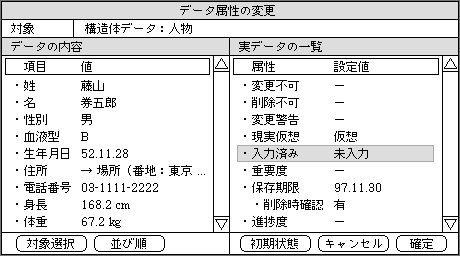
データの属性は、データの特徴や種類などを区別するための付加情報ともいえる。これを利用する機能と組み合わせることで、どんな方向にでも機能を拡張できる。どのように利用できるのか、いくつかの例を挙げてみよう。代表的な利用目的としては、以下の4つがある。
(1)処理の自動化を手助けする
(2)表現の適切さを向上させる
(3)データの正しさの確保を助ける
(4)資源を有効に利用する
もちろん、これ以外の属性も考えられる。今回は上の4つに関する属性に絞って話を進めてみよう。上で説明してきたように、データが細かい属性を持つには、情報中心のシステム上で、個々のデータを分けて扱う基本構造があるため実現する。加えて、どの項目でもすべての機能が使える仕組みがあって、個別にデータ属性を持つメリットを最大限に活かせる(表1)。
表1、OSの種類ごとに、データ属性に関する機能を比較した結果。情報中心システムにならないと、利用の大きなメリットは得られない。なお、オブジェクト指向OSは実在しないため既存OSと同じに扱ったが、上手に設計すれば、既存OSより少しはよくなる
OSの進歩 =================>
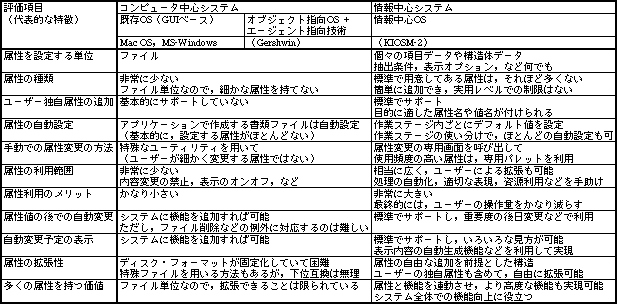
既存OSやオブジェクト指向OSでは、ファイルという単位でデータを扱うため、個々のデータごとに細かな属性を持つ機能はない。ファイル自体の属性はあるものの、原始的な項目ばかりなので、処理の自動化には役に立たない。項目ごとに属性を持つためには、アプリケーションが機能を用意するしかない。しかし、アプリケーションでは、できることに限界がある。
逆に、情報中心システムでは、いろいろな形でデータ属性のメリットを活かせる。先に挙げた4つの目的ごとに、代表的な属性を紹介しよう。
Object First機能を利用した自動処理を行うには、対象となるデータを絞り込む必要がある。通常は、人物のようなタイプで絞り込み、同じ作業ステージ内のデータが対象となる。
しかし、場合によっては、ほかの作業ステージのデータもなんらかの対象として処理することもある。そのとき困るのが、シミュレーション用に作成した架空のデータだ。もし、シミュレーションで人物データを扱うなら、実在しない人物データを入力する。これを一般の現実データと一緒に処理したら、適切な結果など得られるはずがない。
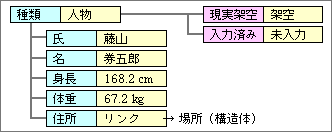
架空のデータは、どんなデータでも考えられるので、データの属性で区別するのが一番だ。現実あるいは架空の属性を用意して、一般のデータは「現実」に、シミュレーション用のデータは「架空」に設定する。通常の処理では、「現実」データだけが対象となり、シミュレーション処理では「架空」データだけが対象となる。これで、誤った処理を防ぐことができる(処理を区別する方法は、次回に解説する予定)。
似たような属性として、「入力ずみ」か「未入力」かの区別も、別の場面で役立つ。たとえば、人物データを入力していて、重要な項目が不明だとする。途中まで入力した分を消さずに残しておき、あとから不足する項目を追加で入力する。それまでのあいだは、中途半端な状態なので、通常の処理対象にはしたくない。存在しないものとして扱うための「未入力」の属性を設定して、処理の対象外とする。「現実」データでも「架空」データでも「未入力」はありうるので、別な属性として用意しておく。この属性は、データを一時的に隠す機能を実現するため、もっと別な用途にも利用が可能だ。
このような属性を持たせておくと、処理対象のデータを抽出するときには、デフォルトですむようになる。その結果、ユーザーが操作する工程を減らし、処理の自動化を手助けする。なお、知識ベース内の項目定義に設定している、「数値」、「長さ」、「人物」といったデータのタイプも、広い意味ではデータ属性に含まれる。
「アプリケーションに依存しないファイル属性を持っていれば
ワガママな抽出条件も即座にこなしてくれる」
情報中心システムでは、知識ベース内の項目定義や構造体定義を参照しながら、データに適した表現内容を自動生成する。しかし、できるだけ最適な表現を求めるには、データの特徴を示す情報は多いほどよい。そこで、重要度を示すデータ属性を用意する。
最も多く使われるデータは、重要度の高いデータだろう。たとえば、他社製品より自社製品を、旧製品より新製品を高く設定する、というのも1つの方法だ。性能比較の表やグラフを生成するとき、重要度を比べて、項目の並び順を決める。また、比率を求めるときの基準として、重要度の高いデータを採用すれば、ほかのデータと比べやすい値が得られる。グラフでも、重要度の高い値を目立たせておけば、自社製品の値を読み取りやすくしておくように設計することもできる。より適切な表現を自動生成するためには、データの重要度は非常に役立つ。もちろん、上手に活用するためには、ある程度の慣れが必要だろう。
重要度は、システム内部的にみると整数の数値となるが、表面的には言葉で選ぶほうがよい。5段階や10段階の表現を言葉で用意し、その中から選ばせる。「高い」、「普通」、「低い」に加え、「やや高い」、「かなり高い」、「最高」などの言葉で段階分けを実現する。数値のほうがよければ、それを使ってもかまわない。両者を混ぜて使えるように、「普通(50)」や「低い(30)」などと、言葉と数値の両方を表示することも可能である。これなら、より細かな区分が必要となったとき、中間の重要度を簡単に設定できる。
ただし、一部の特殊な表現方式を除くと、1つの表現内容(表やグラフ)の中では、2〜3段階程度にしか、目立つランクの差をつけられない。重要度を細かく設定するのは、多くのデータの中から一部だけ抽出し、表現内容を作成するような場合に有効だからだ。ただ、細かく設定するのは面倒なので、この点を理解しながら、上手に手を抜くことも求められる。
「ユーザー自身の重要度を細かく設定し、
セキュリティをかけておけば、面倒もミスもなし」
データの正確さを保つためのデータ属性には、値の変更や削除に関するものが該当する。具体的には、変更を許さない「変更不可」、削除を許さない「削除不可」、変更時や削除時に警告を出して確認を求める「変更警告」などがある。
情報中心システムになると、扱うデータは非常に幅広い。その中には、統計や記録のデータも含まれ、いろいろな処理が参照する形で使われる。経済などの統計データや、スポーツなどの記録データで、外部からもらったものがほとんどだ。これらの値は、あとから変更する必要がないし、勝手に変更されては困る。操作ミスからデータを守るためには、「変更不可」の属性を設定したほうが安全だ。自分が作成したデータでも、アンケート結果などは、いったん集計したら直す必要がないので、同様に「変更不可」属性を設定する。
「削除不可」の属性は、ずっと使い続けるデータに設定する。住所録に含まれる人物データ、取引先や商品データなどだ。変更も削除も許さないのなら、「変更不可」と「削除不可」の両方を設定する。もし、やむをえない事情で変更や削除が必要なら、いったん属性を解除してから行う。
「変更警告」の属性は、重要な項目に設定しておく。対象となる項目の条件は、値が変わると非常に困ることと、めったに変更しないことの2点だ。変更の頻度が少ないからこそ、警告を出す設定でも不便を感じない。人物データならば、「姓」と「名」が対象となるだろう。
これらの属性を適切に設定すれば、誤った変更や削除からデータを守れる。この種の操作ミスは、データの内容をチェックする機能では検出できない。両方を組み合わせることで、より多くの操作ミスからデータを守れる。
ハードディスクなどの資源を有効活用するためにもデータ属性は役立つ。コンピュータの活用分野が広がるほど、多くのデータを入力するようになる。データの中には、一時的なメモなど、一定期間だけ保存するものもある。このようなデータを自動的に削除する目的で、保存期間を指定するデータ属性も用意する。削除する日付を直接指定する方法と、保存する期間を指定する方法の2つが必要だ(図2)。
図2、保存期限の属性設定では、保存期間と保存期限のどちらでも指定できる。保存期間の場合は、基準となる日付も変更可能
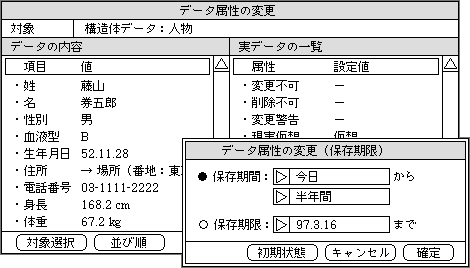
メモのように期間限定のデータは、まったく使わなくなってから削除する。しかし、不要になった時点では、内容を忘れていることが多く、どれを削除するのか選ぶのが面倒だ。このような理由から、作成した時点か使っているときに、保存期間を指定するのがベストといえる。もちろん、作業の遅れなど予定外のことも起こるので、期間は余裕を持って設定する。また、削除するときに、知らせるかどうかも指定できる必要がある。削除予定のデータを見たいこともあるので、データのタイプや削除予定日などを一覧表として表示する機能も加える。
自動的に削除したデータは、すぐに消えるわけではない。手動で削除したデータと同じように、データ復帰機能の削除ログへと移される。削除ログに残っているあいだは、通常の削除データと同じように復活させることができる。
保存期間を指定する機能は、削除を予約する機能でもある。既存のシステムでも、ファイル単位での削除なら実現可能であり、持っていて損はない。保存期間を指定して自動削除すれば、不要なデータがいつまでも残ることを防止でき、ディスクスペースの有効利用につながる。ユーザーが1つひとつ見ながら削除するのは、無駄な作業であり、扱うデータ数が膨大に増える情報中心システムには適さない。
「データ1つひとつが細かな属性を持ってはたまらない
ハードディスクが肥え太らずにすむ方法は?」
以上のデータ属性は、個々の項目ごとに設定するのが基本だ(図3)。しかし、全部の項目が属性を持つと、データの量が膨大になってしまい、ディスクの有効利用を妨げる。そのため、2つの仕組みを用意し、最小限のデータでだけ属性を設定するように改良する。まず1つは、システム全体でのデフォルト値を決め、それと異なる値のデータだけに持つ方法だ。現実架空属性なら、デフォルトを「現実」にすれば、「架空」属性のデータだけで属性値を持てばよい。同様に、重要度属性は「普通」を、入力ずみ属性は「入力ずみ」をデフォルトに設定する。
図3、データ属性は項目ごとに持つ。複数の属性を持てる構造のため、属性の数が増えても大丈夫だ
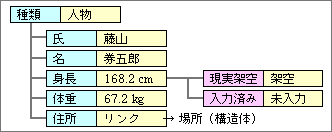
もう1つの仕組みは、構造体データ全体で属性を持つ機能だ(図4)。その構造体に含まれる全項目で同じ属性値なら、構造体に設定する。重要度属性などは、構造体に設定する場合が多い。この2つを組み合わせることで、属性のデータ量を減らせる。実際には、デフォルトですむデータのほうが多い。
図4、データ属性の量を減らすために、構造体データにまとめて設定する方法もサポートする。もし項目がデータ属性を持つ場合は、そちらを優先する
データ属性の機能では、ユーザーが定義した属性を扱える仕組みも用意する。これも、必要なデータにだけ属性値を持つので、データ量が極端に増えることはない。
代表的なデータ属性を紹介してきたが、そのメリットを理解してもらえただろうか。以上のように、データ属性は、システム全体の機能を非常に向上させてくれるものだ。データ属性でもう1つ重要なのは、設定方法である。個々のデータごとにユーザーが設定したのでは、手間ばかりかかって、使いものにならない。ほとんどのデータで自動的に設定する仕組みがなければ、本当に便利な機能とはいえない。これについては、次回に解説する予定だ。
また、データ属性を上手に利用する機能も、システムとしては重要である。すべてのデータ属性は、何らかの機能と組み合わせることで、メリットを生み出すからだ。利用機能も含めて、次回に解説しよう。
処理を向上させ、表現を豊かにしてくれるデータの属性 |
