
思考支援:雑誌連載の内容:第27回 |
前回は、値の履歴を持つ機能について解説した。履歴データを有効に活用するためには、履歴の中から求める値を引き出す機能も必要だ。それも、できるだけ自動的に選択する仕組みが求められる。履歴データは、それを利用する機能と組み合わせることで、最大限にメリットを発揮する。履歴機能の利点を理解すれば、多くのデータに利用したり応用したりすることが可能だからだ。さらに、高度なシミュレーションにもつながるようになる。
ある値がなんらかの履歴を持っていても、それを上手に利用する機能がなければ宝の持ち腐れとなってしまう。履歴を持つデータを利用する場合、全体の変化を見ることよりも、一時点の値を取り出すといったケースが圧倒的に多い。たとえば、品物の単価の場合、単価の全体的な変化を見るよりも、ある一時期の単価を調べるといった使い方が中心となるだろう。
履歴を参照して、ある時点の値を取り出したいときは、値を特定するための条件を指定する必要がある。その条件がないと、システム側が履歴のどこの値をユーザーに返してよいか、決められないからだ。通常は、条件として履歴の軸の値を指定する。項目が単価である場合、日付を指定すれば、指定された日の単価を返すようにする(図1)。もし日付が発売開始日より前ならば、データなしとなる。現在の日付より後なら、前号で解説したような補間方式や軸の範囲に応じて、計算した値かデータなしになる。
図1、経歴データの処理の流れ。補間機能と参照機能が一緒に動き、参照条件に合った項目値を返す
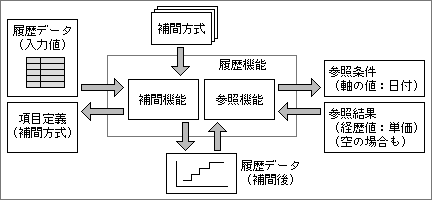
日付以外の軸や複数の軸も設定できる。この場合も、軸に合わせた値を指定することで、履歴データから1つの値を取り出す。
表1、OSの種類ごとに、値の経歴を持つ機能を比較した結果。情報中心システムでないと、経歴データを普通に扱えない
OSの進歩 =================>

なにかのデータを参照しようと思っても、ユーザーが条件を指定してやらなくてはならないのであれば、面倒だし、使いにくい。いったんそう感じ始めてしまうと、履歴機能を使わなくなるだろう。
そこで、条件を指定せずに履歴データを参照できる方法も用意する。ただし、指定しないのは見かけ上だけで、参照条件を内部で生成するようにしておく。デフォルトの参照条件を自動生成する仕組みをシステムに組み込んで、ユーザーがわざわざ指定する手間を省く。これだけでも、使い勝手は大きく向上する。
デフォルトの参照条件は、項目ごとに決まってくる。身長や単価のような項目では、参照する時点の日付と時刻を軸の値にすればよい。つまり「日付&時刻=現在」が参照条件となる。別な軸を持つ項目でも、何らかの条件を必ず設定する。参照条件のデフォルトは、項目ごとに異なるが、ユーザーによって異なるというのは、あまりないだろう。そこで、知識ベースの項目定義に、参照条件のデフォルトを最初から登録しておく。そうすれば、ユーザーが登録する手間が省けるし、履歴データを利用しやすくする。
デフォルトの参照条件を用いることで、単価の変更などの作業も簡単になる。将来の変更分を事前に入力しておいても、問題なく処理が進むからだ。事前に変更データを追加入力すれば、処理する日が単価の変更日を過ぎると、自動的に単価が切り替わる。こうなると、既存のデータベースのように、切り替え日を意識しながら登録する必要はない。単価以外の項目でも、同じような機能の特徴が役に立つ。たとえば、電子メールのアドレスや電話番号も、変更内容を事前に登録しておき、変更時期が来たら自動的に切り替わるようにする。システム上で扱う全データで同じ仕組みが使えるために使い勝手はとてもよくなる、というわけだ。
「どんな条件で値を抽出するかを考えなきゃいけないなんて
うっとおしくて、そのうち使わなくなってしまう」
経歴データを参照するのが、1つの処理とは限らない。複数の処理から別々に参照できる機能も必要だ。その際、それぞれの参照条件を設定できなければ使いづらい。また、それぞれでデフォルトの参照条件を設定できる機能も必要だ。
そこで、デフォルトの参照条件を、作業ステージごとに設定できる仕組みにする。参照条件が異なってくれば、処理の種類も異なる可能性が高いので、別々の作業ステージに分けても違和感はない。作業ステージごとに参照条件を変える場合、参照条件データも作業ステージごとに持たなくてはならない。しかしこれだと、履歴データの数に比例して、作業ステージ内の参照条件データも増えてしまう。
そのため、別な方法で参照条件の変更と結果的に同じになる仕組みを実現する。参照条件は、日付や時刻などシステム側の値を用いる。作業ステージごとに、これらの値を変えられれば、複数の参照条件を持つ必要がない。この方法は、別なメリットもある。作業ステージ全体で日付を変えるので、日付に関係する参照条件を持つすべての履歴データで、一斉に参照条件を変えることができる。変更の手間を考えたら、こちらのほうがはるかに使いやすい。実際の使い方を考えても、関係する全データで日付を変えてみて、値の変化を見るほうが自然だ。現実的で使いやすい方法といえる。
作業ステージ内で日付や時刻を変えるときは、扱いやすさも重要だ。専用のパレットを表示し、マウス操作だけで自由に前後する方法がよい(図2)。そこでは、日付だけでなく、時間の進み具合も変更可能にする。通常の1440倍に設定すれば、1日の動きを1分として凝縮して見ることもできる。本来の表示設定をそのままコピーし、時間だけを変化させれば、未来の動きを簡単に確かめられる。作業ステージごとに日付を変更する機能は、シミュレーション機能としてとらえられる。あまり意識しないで、シミュレーション機能を使えるような仕組みでもある。シミュレーションだと素早く気づかせなければ、一般の表示とまちがえて信用してしまうトラブルが起こる。そのため、日付などを変更した作業ステージの表示は、シミュレーションとわかるような、一般と異なるデザインの表示にする。
図2、作業ステージの日付や時刻の変更を容易にするため、専用のパレットを用いる。時間の進行を一時的に止めたり、進む速度を増減する機能も加える
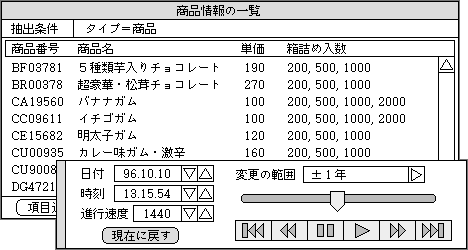
このように簡単に使えるシミュレーション機能では、普通の状態に素早く戻す機能も必要だ。専用パレットの中に、一発で戻す機能を組み込んでおく。
作業ステージごとに参照条件を変えられると、いろいろな使い方ができる。よく使われるのが、履歴データの入力が正しいかどうかの確認だ(図3)。将来の単価の変更を入力しても、そのまま参照したのでは現在の単価しか表示しない。そこで、確認用の作業ステージを別に用意し、単価を表示させる。その状態で作業ステージの日付を進めれば、ある時点で単価が切り替わるはずだ。それが正しく動かなければ、入力がまちがっていたと判断できる。
図3、将来の経歴値を先に入力しても、別な作業ステージを用意して、入力値が正しいのか確認できる。もとの処理をコピーすれるので、確認用の作業ステージを作成する手間は最小限ですむ
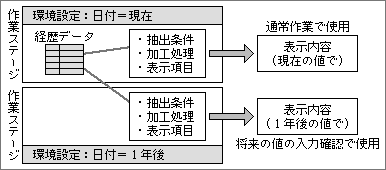
確認用として用意した作業ステージは、再び使う機会もあるので、そのまま保存する。経歴データを追加するたびに呼び出して、入力した内容が正しいか確かめることもできる。本来の機能を邪魔することがないので、共存が可能だ。また、同じ経歴データと表示方法で試すことができるため、もとと同じ環境で確認できる。もちろん、作成の手間が最小限ですむ点も大きな魅力である。
経歴データの項目を表示するだけなら、メリットは少ない。その値をもとに計算し、別な値を求めるときにこそ、確認用の作業ステージが大きく役立つ。計算のもととなる経歴データと計算結果を一緒に表示して、日付を進め、変化を見る。思ったように変わるかどうか、簡単に確かめられるわけだ。
このように簡単に使えれば、いろいろな補間方式や履歴データを試したてみたくなる。単価を変化させて売上高を予測するとか、幅広いシミュレーションにも利用できる。履歴データの参照機能は、手軽に使えるシミュレーション機能として、大きく役立つはずだ。既存のデータがそのまま使える点も、大きなメリットとなる。
「履歴は過去を振り返るためだけのものではない
高度なシミュレーションの前提となる」
前号では、値の補間方式の追加機能について述べた。この部分は、追加する補間方式によっては、応用の範囲がかなり広がる。追加する処理は、入力した値と値の間を計算するのが目的だ。だからこそ、補間方式と呼んでいる。
しかし、もっと別の処理を追加することも考えられる。値の間を補完するのではなく、入力したデータをもとに、新しい値を生成する方式だ。たとえば、複数の値を線で結ぶ代わりに、近似曲線を求める方式を追加する。近似計算の方法や何次曲線かを選ぶと、入力したデータをもとに、もっとも近い曲線を計算してくれるようにする(図4)。この曲線の値が参照したときに返され、入力データは返す値として用いない。近似曲線を求めるので、軸の値の部分に同じデータを複数入れても大丈夫だ。利用例としては、実験での測定値を入力し、それから求めた近似曲線を項目の経歴として採用する使い方が考えられる。
図4、入力した値をそのまま使わず、近似曲線を計算で求め、それを経歴データとして用いる。測定誤差が含まれる実験結果を、経歴データとして用いるときに役立つ
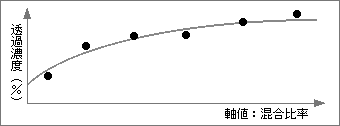
こうなってくると、値を補完するという意味を超えているため、もう補間方式とは呼べない。また、内部のインタフェースも補間方式とは異なる。しかし、応用できる範囲が広がるので、あると便利な機能だ。もっと凝った方式を加えることで、さらなる拡張も可能といえる。機能の名前は、本来の意味が補間であるため、最初の機能は補間方式と呼ぶべきだろう。そのうえで、補間の枠を超えた追加機能については、補間拡張機能として特別な扱いにする。補間とそうでないものを明確に分けることは、誤った使い方を防止する意味からも必要だ。
補間拡張方式も、補間方式の1つとして組み込むため、補間拡張方式と補間方式を切り換えて使うことが可能だ。一時的に別な補間方法に切り替え、値のちがいを観察する使い方も考えられる。
もっと凝った補間拡張方式も加えられるが、別な面で考慮すべき点がある。どんな機能でも、本来の目的から外れる形で組み込んではならない、ということだ。ユーザーの混乱を招く要因となり、システム全体が理解しにくくなってしまうからだ。
情報中心システムの基本精神に照らし合わせるなら、情報が持つ目的に合わせて全部の機能を加える。凝った補間拡張機能は、もっと違う形で組み込むべきだろう。どんな機能であっても、情報の意味を理解しながら使えることを重要視する。
逆に既存OS上では、本来の目的から外れた使い方が一般的であり、ユーザーの工夫が求められる。構造上の制約が多いことに加え、提供される機能が原始的なためだ。目的から必要な処理を導き出し、用意された基本処理の組み合せに置き換える。この過程も含めて手作業が多いため、凝ったことをするためには手間がかかる。また、プログラムをつくらなければ実現できないことも多い。全体として見れば、本来の目的から遠い機能を組み合わせるため、何をしているのか把握しづらい仕組みになっている。ユーザーが混乱するのも無理はない。
情報システムならば、情報そのものを直接扱う仕組みなので、履歴機能も自然な形で実現できる。その結果、違和感なく使えるシステムに仕上がる。
「補間方式の追加で補間以上の機能も実現できるが、
無用な拡張はかえって混乱のもとなので注意すべし」
以上のように、値の履歴を持つ機能は、入力から参照まで総合的にサポートする。それによって、より使いやすい履歴機能が実現できる。履歴機能の利用が当たり前になってくると、広い範囲で履歴データを用いることになる。たとえば、会長や社長のような役職の項目では、日付を軸とした履歴データとして、時期ごとに異なる人物データへのリンクをつくる。また、履歴書の構造体データでは、勤務先や職業を履歴データとして入力する。個人的なデータでも、身長や体重だけでなく、住所や電話番号まで履歴データとして扱い、過去の値も残す。使い方と利点を理解すれば、多くの項目で履歴機能を使うようになるはずだ。
履歴機能のメリットは、一般的な使い方をする場合には2つある。1つは、過去の値を消さずに変更後の新しい値を入力できる点だ。それも、いつ変わったのかも含めて残せる。もう1つは、将来の変化を事前に登録できる点だ。商品マスターなどの重要項目で利用し、何年後のデータであっても、先に入力しておける。入力値を容易に確認する機能もあるため、安心して使える点も魅力だ。
応用的な使い方でも、幅広い利用が考えられる。実験結果を履歴データとして保存すれば、それをもとにした計算が簡単になる。また、シミュレーションも適した分野の1つだ。条件を変化させたときの動きは、複数の履歴データを組み合せて計算し、結果をグラフとして表示する。何かを軸として変化するデータは、すべて履歴機能の利用対象となるので、広く活用できるはずだ。
履歴機能の追加は、現在のデータだけのサポートから、過去や未来のデータへの拡張を意味する。つまり、扱える情報の対象範囲を広げる機能なのだ。それも、現在のデータと切れ目がない方式なので、全体を自然な形で利用できるようになる。
値の履歴を扱うような機能は、情報の扱い方を重視して考えなければ出てこない。まさに情報中心システムらしい機能といえる。さらに重要なのは組み込み方だ。ほかのデータと違和感なく使え、幅広く利用できる形で実現する必要がある。履歴機能を使うことを念頭におき、発想を変えて設計すれば、コンピュータは格段に使いやすくなるのだ。
履歴を持つデータを効率よく使うためのシステムとは? |
