
思考支援:雑誌連載の内容:第29回 |
前回に続き、個々の項目ごとに持つデータ属性について解説する。このメリットを最大限に生かすためには、属性をいかに利用するかも重要なポイントだ。今回は、もっとも特徴的な『対象データの抽出』を中心に、属性利用の仕組みと特徴について述べていく。抽出条件にデータ属性を加えておけば、関係のないデータを自動的に排除することができるし、関係のないデータをまちがって処理することも防げる。これは、簡単に使えるうえに、ユーザー独自の属性も追加できるため、多くの人が広く活用する可能性が高い。
いろいろなデータ属性は、それを利用する仕組みがあってこそ初めてメリットを生む。これがいかに便利かは、その仕組みの良し悪しで決まる。すべてのデータに関係する機能なので、システム全体の使い勝手に大きな影響を与える。より使いやすい環境を目指すためには、データ属性を利用する機能が重要だ。基本的な条件として、使い方が簡単なことと、幅広い場面で役立つことの2点を満たさなければならない。
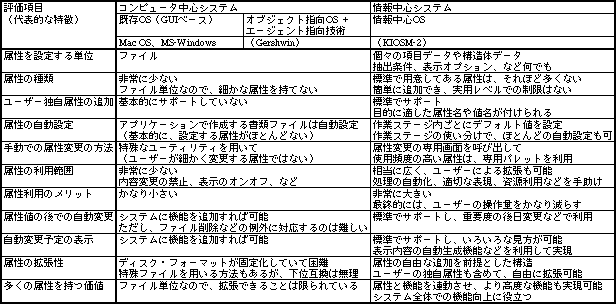
既存OSでは、ファイル単位で属性をつけるため、あまり有効には活用できない(表1)。しかし、情報中心システムでは、個々の項目に属性値を設定できるので、かなり凝った活用も可能だ。しかし、その分だけ利用機能の中身が重要となる。
表1、OSの種類ごとに、データ属性に関する機能を比較した結果。情報中心システムにならないと、利用の大きなメリットは得られない。なお、オブジェクト指向OSは実在しないため既存OSと同じに扱ったが、上手に設計すれば、既存OSより少しはよくなる
OSの進歩 =================>
前回説明したデータ属性の4つの利用目的のうち、ユーザー自身が考えて設定しながら活用できるのは、「処理の自動化を手助けする」という属性だ。現実/架空や入力ずみの区分けなどが含まれる。この種の属性は、後述するように、簡単に使えることに加え、ユーザー独自の属性を追加することも可能だ。アイデア次第で、かなり広い範囲で利用できる。データ属性の利用例としては、もっとも分かりやすいものなので、これを中心に述べよう。
データ属性を利用するにあたって、大変な作業になるのが、値を設定する手間だ。ユーザーがわざわざ指定せずにすませるためには、デフォルトの状態で、データ属性を持たせておくのがもっとも簡単である。デフォルトの値としては、2つが考えられる。
新規に項目を追加するときに用いるデフォルト新規属性と、対象データを見つけるときの条件として用いるデフォルト参照属性だ。これらは、ほとんどのケースで同じだが、別々に設定したいこともあるので分けておく。また、デフォルト参照属性は、単なる値ではなく、より複雑な抽出条件である場合もある。この点こそが、2つに分けておく大きな理由だ。
情報中心システムでは、仕事の目的ごとに作業ステージを用意する。この作業ステージごとに、デフォルトの属性値を設定しておけば、処理の自動化を助けられる。
シミュレーションのために用意した作業ステージでは、ここでは新規と参照の両方のデフォルト属性とも、現実/架空属性を「架空」に設定する。すると、追加するすべての項目が「架空」データとなる。何かの処理で対象データを選ぶ際にも、デフォルト参照属性が「架空」なので、「架空」データだけしか抽出されない。逆に、ほかの作業ステージではデフォルト属性が「現実」なので、「架空」データをまちがって処理することはない。結果として、関係のないデータまで処理してしまう、というようなミスも防げる。
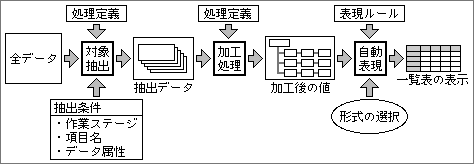
各処理での対象データの抽出方法をもう少し詳しく見てみよう。処理に必要なデータは、項目名を指定して検索する。つまり、項目名が一番の抽出条件になるわけだ。もう1つの条件は、検索範囲で、通常は処理が属する作業ステージ内に限られる。条件に該当したデータを全部処理して、結果を一覧表などの形で表示する。以上はデータ属性が関係ない場合だ。作業ステージにデフォルト参照属性を設定してあると、属性も抽出条件として加わる(図1)。現実/架空属性が「架空」なら、その属性値を持つデータしか抽出せず、それ以外である「現実」データは対象外として扱わない。
図1、情報中心システムでの代表的な処理の流れ。処理の対象データを自動抽出する部分で、データ属性もチェックする
現実と架空のどちらを対象とするかは、作業の種類ごとに決まるので、作業ステージごとのデフォルト設定が適している。また、システム全体でのデフォルト設定というのもあり、これを「現実」に設定する。すると、デフォルトが「現実」でよい作業ステージには、デフォルトをとくに設定しなくてもすむ。「架空」が必要な作業ステージにだけ設定するので、作業ステージへ設定する手間も最小限ですむ。「架空」データを用いるのは、シミュレーション以外に、教育用の教材、操作の練習用などが考えられる。これらは独立した作業ステージを用意して、そこにデータを入れる。
「仕事の目的ごとにデータを処理する作業ステージで
デフォルト属性値を利用し、抽出をより簡単に効率的にする」
仕事の一部として、シミュレーションが含まれることもある。データのすべてを1つの作業ステージに入れてしまうと、デフォルト設定が有効に働かない。こんなときは、作業ステージを分割するのが賢明な選択だ。ただし、まったく別な作業ステージではなく、子供にあたるサブ作業ステージを利用する。一般的には、親側の作業ステージでデフォルトを「現実」に設定し、子供側のサブ作業ステージに「架空」を設定する。当然、シミュレーション用の項目はサブ作業ステージに入力するし、シミュレーションの処理もサブ作業ステージ上で実行する。これなら、デフォルトの属性値を十分に活用できる。
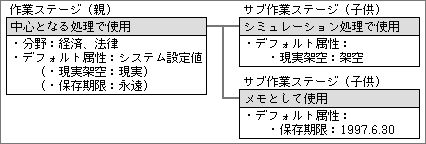
別な作業ステージではなく、サブ作業ステージを利用するのには理由がある。目的の処理や項目を素早く呼び出すために、作業ステージには、たとえば「経済」や「医学」といった分野を設定しておく。同じ仕事であれば、これらの設定も同じはずだ。サブ作業ステージとしてつくっておけば、親の作業ステージの設定をすべて継承し、ちがう部分だけを設定し直せばよい。つまり、サブ作業ステージには、デフォルトのデータ属性として「架空」を設定するだけですませられる。分野を追加したい場合でも、親の作業ステージで設定するだけでいいわけだ(図2)。
図2、中心となる作業ステージのほかに、シミュレーション用とメモ用の作業ステージを加える。メモ用は、あとで削除しても構わないデータを入れる。親の作業ステージで設定した分野や属性は、子供であるサブ作業ステージに継承される
「別の作業ステージではなく、
子供にあたるステージを用意するのがミソ。
利点は親の設定をすべて引き継げること」
対象データを抽出する際に用いるデータの属性としては、現実/架空属性のほかに、入力ずみという属性がある。一部分だけ入力したデータに対して、それが存在しないものとして扱う「未入力」と、存在するものとして扱う「入力ずみ」とを区別する属性だ。通常のデータは「入力ずみ」に設定しておく。こちらの属性は、システム全体で「入力ずみ」がデフォルトになる。一般の処理でもシミュレーションでも、「入力ずみ」データが対象となる。そのため、すべての作業ステージでは、システムのデフォルトと同じなので、デフォルトの属性としては設定しない。
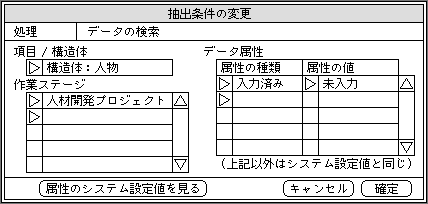
「未入力」データは、特殊なデータであり、一般的な処理の対象にはならない。それを処理したいような場合には、ユーザーが意識的に指定する必要がある。一部分だけ入力した状態のデータが残っていて、それを入力するために呼び出すときには、抽出条件として「未入力」を指定する(図3)。入力が終わったら、データの属性値を「入力ずみ」に変更し、処理の対象として選ばれる状態にする。このほか、この属性の別な使い方としては、そのデータを存在しないことにする、というのがある。そのデータだけを処理対象外としたい場合にも、抽出条件を手動で「未入力」に変更する。
図3、一部だけ入力したデータを検索するために、検索条件のデータ属性で、入力済み属性を「未入力」に設定する
以上のように、抽出条件であるデータ属性の値は、手動でなら随時変更が可能だ。もちろん、片方の値だけでなく、両方の値を対象とすることもできる。3つ以上の値を持つ属性なら、2つを指定するとか、全部を対象とするなど、自由に変えられる。全部を対象とする指定なら、内部での処理では、その属性を見ない。
ユーザーが独自に定義したデータ属性も、基本的には同じ働きをする。ただし、すべてのデータに属性値を設定するとは限らないので、属性値を持たないデータの扱いも考慮する必要がある。
作業ステージにデフォルトの属性値を設定すれば、その属性値を持つデータだけを対象とする。逆に、特定の値を持つデータだけを除外するような設定も可能だ。両者のちがいは、属性値を持っていないデータの扱いにある。除外する設定なら、属性値を持たないデータも対処となるが、逆であれば対象とならない。この部分を考慮して、デフォルト値を決める必要がある。ちなみに、除外する設定の場合には、デフォルトがたんなる値ではなく、抽出条件の形式となる。
属性値を持たないデータは、独自のデータ属性を途中から定義した場合のほか、ほかの作業ステージに入っている場合が考えられる。作業ステージを生成したときに、ユーザーのデータ属性を新規デフォルトとして登録すれば、属性値を持たないデータが入ることはない。
もちろん、データ属性の使い方として、すべてのデータに設定しないでおくという方法も考えられる。たとえば、特別に抽出して処理したいデータにだけ、属性値を設定しておくケースだ。自分が個別に選んだデータのみを対象として、一部の処理を実行するときに役に立つ。このような用途では、作業ステージにデフォルトを設定するのではなく、実行する時点で抽出条件を指定する。
各人が勝手に属性をつくってしまうと、別な人のデータを一緒に処理するようなときに困るだろう。それを少しでも防ぐためには、ある程度の人が使うと思われる属性を最初に幅広く用意し、その中から選んでもらう方法がよい。属性もデータの1つと考えれば、少しは標準化が必要だ。
作業ステージに含まれるデータは、あとから変更したものを除き、デフォルト新規属性と同じ属性値を持つ。ほとんどのデータが、デフォルト値と同じだといってよいだろう。それだけに、デフォルト値の設定は重要といえる。
問題となるのは、デフォルト新規属性を変更する場合だ。深く考えないと、デフォルト値だけを変えればよいと思ってしまう。しかし、デフォルト値を変更する状況は、すでに入力ずみのデータも含めて、属性値がまちがっていたことも考えられる。その場合も考慮し、デフォルト値の変更の際には、作業ステージ内のデータの属性も一緒に変更するかを尋ねるようにしておく。もちろん、デフォルト値だけの変更も選べる。このとき変更の対象となるのは、変更前のデフォルトと同じ値を持つデータだけで、手動で属性値を変えたデータは対象外にする。
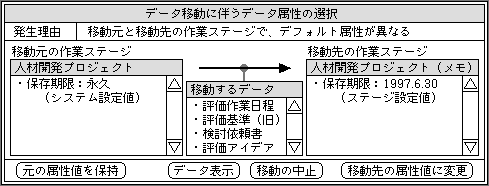
別な作業ステージにデータを移動するときにも、デフォルトのデータ属性を調べるべきだ。移動前と移動先の作業ステージで、デフォルト新規属性が異なる場合に、どうするかを尋ねる。両方の作業ステージのデフォルト値を表示し、どちらに設定するのかを選ばせる(図4)。このケースでも、データの属性値がデフォルトと異なる場合には尋ねない。ただし、データ属性が1つではないため、デフォルトと異なる属性値が1つでもあったら、選択画面を表示する。どれがデフォルトと同じで、どれが異なるのか、明確に示す必要がある。
図4、別な作業ステージへデータを移動するとき、作業ステージ間のデフォルト属性値が異なると、どちらを選ぶのか尋ねてくる
「デフォルト属性値の設定を間違っても大丈夫
あとからでもまとめて変換できる」
ここまでは対象データの抽出処理に関係するデータ属性を述べた。それ以外としては前回説明したように、適切な表現内容の生成を助ける重要度属性、データの信頼性を確保する変更禁止属性、資源の有効利用を実現する保存期限属性などがある。これらに関する利用機能は、データ抽出のように単純ではない。それぞれ専用の処理を追加する形で、属性の利用機能を実現する。表現に関する部分だけは特別で、表現内容を自動生成するAuto Expression機能の表現ルール内に埋め込まれる。表現の軸の決定と、軸上での項目の並び順を決める部分に利用される。この処理は少し難しいので、別な機会に解説したい。
内部的な話になるが、情報中心システムの基本構造は、ほとんどのソフトを部品のように組み合わせて動く。それらを管理する機能が基礎にあって、ユーザーの操作を代表とする起動トリガーにより、最初のソフトを呼び出す。そのソフトが別なソフトを呼び出す形で、加工処理や表示内容生成などが進む。起動トリガーには、データを変更したときや、日付が変わったとき(次の日に移ったとき)など、ユーザーの直接的な操作以外のものが多くある。また必要なら、ユーザーの操作を受け付けるための表示部分(既存ソフトのパレットなどに相当するもの)も一緒に追加する。
データ属性を処理する機能は、どれかの起動トリガーに割り当てる形で追加する。毎週や毎日というように定期的に起動するトリガーに割り当てることで、自動的な削除や更新ができ、ユーザーに手間をかけずにすませることも可能だ。ユーザー独自の属性は、高度なカスタマイズ機能としても利用できる。
以上のように、データ属性は情報中心システムの機能を拡大するために幅広く役立つ。既存OSとは大きく異なり、情報自体に近い部分でカスタマイズできる点も、魅力の1つである。
データに属性をうまく与えて、より広く活用するには |
