
思考支援:雑誌連載の内容:第5回 |
前回は、ユーザーとシステムのやりとりの概要を解説した。そこで登場した知識ベースは、KIOSM-2の重要な要素だ。今回は、その中に入れる内容について解説する。知識ベースには、項目や処理方法の定義を入れる。その内容がわかれば、本システムの可能性や機能が、より詳しく理解できるだろう。知識ベースの定義は、プログラミング技術がなくてもつくれるもので、定義データの大量生産も可能となる。そして、多くの分野の定義を標準装備すれば、ユーザーが定義を作成する必要もなくなる。さらには、システムを使っているうちに知識が身につく環境も実現する。
KIOSM-2では、Object First機能とAuto Expression機能を実現するために、知識ベースと表現ルール集が大きな役割を果たす。今回は、知識ベースの内容と構造について解説する。
知識ベースといっても、ごくごく基本的な知識しか持たない。それだけでも、十分に役立つからだ。
その中に入れる内容は、大きく分けて3種類ある。最初は、「身長」や「肥満率」といった個別の項目定義。次は、複数の項目定義を集めてリンクし、1つの独立した意味を持たせた構造体定義だ。「人物」とか「企業」とか形あるものだけでなく、「貸借対照表」のようなデータの集まりも対象となる。3つめは、データを加工するための処理方法を記述した処理定義だ。「肥満率計算」などの特定用途のものや、「平均」や「合計」などの汎用的な内容もある。また、「モーフィング」などの画像処理も含まれる。これらの内容と構造を、順番に解説しよう。
知識ベースの基礎となるのは、個々の項目の定義だ。本連載の第2回で解説したように、入力した各データは、種類や単位などの属性を持っている。それぞれの項目でどんな属性を持つかを定義するのが、項目定義だ。
たとえば、「身長」の項目定義なら、タイプが数値のデータで、通常用いる単位がcm、1番目の種類は「長さ」となる(図1)。この項目の場合は、種類が2段階しかないので、2番目の種類が「身長」となり、実際のデータの中に保存するために用意する。
図1、項目定義の例。1つの項目がいろいろな構造体で使用されるため、最低限の内容しか含めないのが基本だ
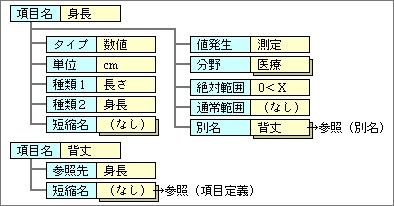
そのほかには、項目が属する分野も必要で、1つの項目が複数の分野に属することもある。分野は何段階かのレベルに分かれているが、図では省略して描いた。絶対範囲は、特に数値データに重要で、値がとりうる範囲を規定する。身長の場合は、ゼロより大きい値に設定する。最大値を規定しないのは、人間以外の身長も考えられるからだ。通常範囲は、実際のデータがとりうる値を規定するもので、データ入力時のチェックに用い、絶対範囲よりも狭い範囲となることが多い。この例では、範囲を絞ることができないため、使っていない。
短縮名は、項目名を短縮した言葉を登録する。Auto Expression機能で使用し、一定範囲内に多くのデータを表示したいときに使われる。何種類かの短縮名を登録しておき、表示できるスペースと照らし合わせながら、その範囲内で一番長い名前を選ぶ。たとえば、表形式の表示で、セル内の1項目だけに長い文字列があると、セル幅が全体的に広くなってしまう。その1項目を短縮名に置き換えれば、セル幅が狭くなって、より多くのデータを表示できるようになる。このような短縮名への置き換えは、必要なときだけAuto Expression機能が自動的に行う。勝手に短縮名をつくることも可能だが、まともなものを登録しておいたほうがよい。身長の例では必要ないが、項目名が長いときには必須だ。
別名は、1つの項目定義を、別な名前でも使えるようにする。身長の例なら、背丈などを登録する。登録した別名データは別の定義データとして保存し、もとの定義を参照する形で用いる。別名の短縮名など、一部のデータが異なるからだ。
値発生は、「測定」や「計算」などの値を持つ。「測定」とは、身長や体重のように測定して得られる生データだ。逆に「計算」は、標準体重や肥満率のように、測定したデータから計算で求める値を示す。この属性は、処理の自動化に大きく関係する。最終的に得たい項目の値発生が「測定」なら、処理をして得られるデータではないので、検索することになる。そうではなく「計算」なら、まず過去に処理したデータから検索し、次に、その値を計算するための処理方法を見つけだすことになる。処理効率を上げるためには、必須の属性だ。
「短縮名はAuto Expression機能で使用し
一定範囲内に多くのデータを表示したいときに使われる」
データを加工する処理方法は、処理定義として記述する。どんな処理でも入力と出力があり、複数の項目を使用する。処理定義で使用する項目は、項目定義を参照するため、必ず定義されている必要がある。
結果を求めるための処理は、項目の数だけ存在する。最も単純な例として、肥満率計算を見てみよう(図2)。肥満率は、標準体重と体重から求められる。また、肥満率と標準体重から体重を計算できる。つまり、使用する項目の数だけ、計算式があるのだ。どの方向からでも処理が使えるように、すべての項目での計算式を定義する。
図2、処理定義の例。処理の中で使用する項目ごとに、その項目を求めるための処理内容(この例では式)を記述する。複雑なプログラミングが可能な処理内容の記述方法も加えると、適用範囲はさらに広がる
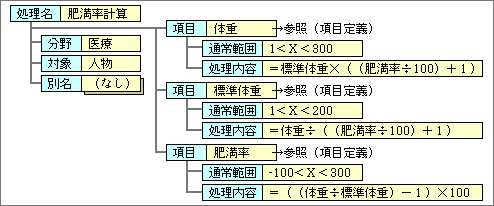
肥満率計算は、人間を対象としているもので、動物に適用することはできない。そのため、対象という属性を加えて「人物」を入れる。
人物が対象であれば、体重などの項目で通常範囲が規定できる。処理定義にも別名や分野が必要な点は、項目定義と変わりない。
肥満率計算の処理定義からわかるように、項目として「標準体重」を用いている。「標準体重」は、値発生が「計算」の項目で、「身長」から計算で求められる。そのため、「標準体重計算」という処理定義も存在する。これを組み合わせれば、身長と体重から肥満率が求められる。このように、複数の処理定義を組み合わせられることも重要で、定義の冗長性を最小限に抑えられる。
いくつの処理を組み合わせればよいかの判断には、値発生の属性が役立つ。肥満率を求めるとき、体重と標準体重が必要だとわかる。体重は値発生が「測定」なので、検索すればよい。逆に、標準体重は値発生が「計算」なので、標準体重を求めるための処理定義を探すことになり、「標準体重計算」の処理定義が見つかる。値発生が「計算」の項目をすべて消せるまで、処理定義を探せばよい。
複数の項目を集めて、その関連性や構造を記述するのが構造体定義だ。対象となるのは、「人物」や「企業」のように独立したものだけでなく、「貸借対照表」や「会員名簿」のようにデータの集まりでもよい。1つのまとまりとして扱えるものなら、何でも構造体定義の対象となる。
構造体定義では、その中で使う項目やリンク軸を含む(図3)。それぞれの項目では、項目定義を参照するとともに、通常範囲やリンク軸との関連を設定する。身長や体重は、人物という構造体の中で使われることにより、通常範囲が規定できる。リンク軸を設定した項目は、軸の値とテーブルをつくることを意味する。この図では体重の部分だけに記述してあるが、身長も同じで、測定時期ごとに複数の値を持てる。
図3、構造体定義の例。中で使用する項目のデータ構造は、グループ定義として複数持てる。また、グループ定義には、使用目的ごとに項目を選択する機能もある
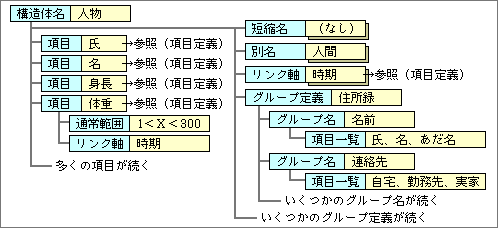
構造体定義でも、短縮名や別名が設定可能で、別名は別の定義データとして保存し、その短縮名などを含む。この部分は、項目定義と同じだ。
グループ定義は、項目全体の構造を規定するもので、複数の定義を持てる。人物データの場合、含まれる項目数はかなりの数にのぼる。どの項目が必要かは、データの使用目的によって大きく異なり、多くの場合は少数の項目しか使わない。そこで、代表的な使用目的をグループ定義として記述する。たとえば住所録なら、その目的に必要な項目だけを選んでグループ内に加える。もし健康診断が目的なら、選ばれる項目も大きく変わる。グループ定義は、必要な項目を効率よく選ぶためにも、重要な役割を果たす。
グループ定義は、使用目的ごとに作成するとともに、それぞれの中で、階層構造による項目の分類が可能だ。階層構造を複数持つのは、ユーザーの使い勝手を考えてのことだ。項目数が少ないと、階層の数を増やしても使いにくくなる。とはいうものの、最も厳密にデータを分析したときの階層構造だけは、基準データ構造としてグループ定義しておく。当然ながら、この基準グループ定義には、構造体定義の中の全項目が含まれる。
構造体定義からは、項目だけを参照するのではなく、別な構造体定義も参照可能だ。こうすれば、単純な構造の構造体定義を組み合わせて、複雑な構造体を表現できる。
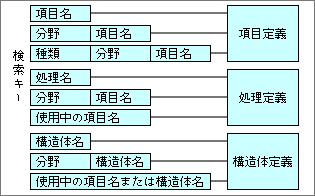
これら3種類の定義は、それぞれが関連を持っている。必要に応じて、Object First機能やAuto Expression機能から呼び出され、データ入力や表示などに利用する。関連する定義を呼び出すためには、何種類かの検索キーを持たなければならない(図4)。この検索機能があるから、知識ベースはデータベースの構造となる。
図4、各種定義は、相互の関連を検索し合いながら利用する。そのため、複数の検索キーをつけて、関連する定義を検索しやすくする。たとえば、処理定義の「使用中の項目名」キーは、求めたい項目に関連する処理定義を探し出すとき役立つ
ユーザーのデータ入力では、1つの項目ごとではなく、関連するデータの集まりを一緒に入力する。そのとき参照するが構造体定義だ。定義内のデータ構造に合わせて、入力データを保存するため、ユーザーがデータ構造を意識しなくても、きちんとした構造のデータがつくれる。知識ベースを利用する意味は、この点が大きい。きちんとしたデータ構造は、より正確で効率的な自動化処理をもたらすからだ。
「きちんとしたデータ構造は
より正確で効率的な自動化処理をもたらす」
より多くのデータ定義を効率よく集められるようにと、コンピュータの専門家でなくても定義がつくれる環境を用意する。項目定義や構造体定義は、処理が含まれないので、各分野の専門知識があれば、簡単につくれる。問題は処理定義だ。プログラミングの知識がない人でもつくれるように、カード型データベースの計算フィールドの式に似た定義ツールを用意する。ほとんどの基本的な処理は、関数としてシステム側が用意する。その中には、数値やテキスト処理の関数だけではなく、画像処理やソートなどの関数も含める。そうすれば、各分野の専門家が処理定義を増産できる。
式で表現するためには、関数に渡すパラメータを文字で表現する必要がある。難しいのは画像処理の関数だが、基本的な処理を上手に設計することで、ほとんどの部分をクリアできる。通常のソフトでスライドバーになっている部分なら数値で表現できるからだ。もちろん、モーフィングのように、個別の画像ごとにポイントを指定するような処理は、式だけで表現できない。その場合は、途中でユーザーに操作させることにして関数をつくれる。この考え方でいけば、すべての画像処理が関数化できる。
定義データが集めやすくなると、多くの定義データをシステムに標準装備することも可能だ。極端な話、この世の中で誰か一人だけが定義を入力し、他の人はそれを利用するところまで持っていく。ほとんどの処理方法は、行う人間に関係なく、決まっているのだから。
標準装備する知識ベースには、いろいろな分野の定義を網羅する。数学の公式をはじめ、物理や電気といった科学分野の定義に加えて、財務などの分野も含める。また、日常生活で役立つ人や社会に関する定義も入れる。これによって、ユーザーが自分で定義を追加する必要性は、極端に少なくなる。ユーザーの作業は、自分のデータを入力して、どの処理を加工に使うのか指示するだけだ。つまり、目的を達成するための最小限の操作ですむ。
KIOSM-2の場合、ただでさえ操作する部分が少ない。入力部分を除くと、ユーザーは最小限の操作しかせずに、待っていることが多い。しかし、安心してほしい。今回は説明できなかったが、すべての処理定義には、その処理内容の詳しい解説も含めるので、それを読みながら正しい処理がなされているかを判断することになる。もし、知らない処理が自動的に使われていても、それが何であるか勉強できる環境なのだ。システムを使うことで自分の知識が増えるという、前代未聞の環境が実現する。この点も知識ベースの重要な役割だ。
今回は、誌面スペースの関係で、知識ベースの一部しか説明できなかった。定義した知識の解説まで含められるヘルプ機能や、入力や表示をわかりやすくするフォーム機能については、次回に解説したい。
項目と処理の定義を入れる知識ベース |
