
思考支援:雑誌連載の内容:第4回 |
データ構造の基本部分を、前々回と前回の2回で解説した。今回は、このようなデータ構造を利用してつくる、新しいコンピュータの機能と操作環境についての概要を紹介する。知識ベースと表現ルール集を内蔵することで、まったく新しいシステムを実現する。現在のコンピュータと比べて、格段に使いやすいものになり、本来の目的に集中できる環境が整う。
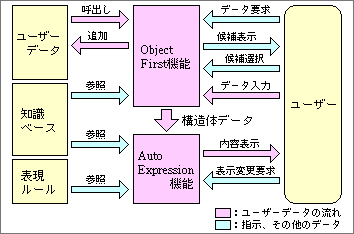
KIOSM-2では、Object First機能とAuto Expression機能を実現するために、知識ベースと表現ルール集が大きな役割を果たす(図1)。既存のシステムのように、アプリケーションを基本としてはおらず、2つの基本機能と対話しながら作業を進める。
図1、KIOSM-2の基本構造には、知識ベースと表現ルールが含まれる。ユーザーとのあいだにObject First機能とAuto Expression機能が入って、全体の動きを制御する
このシステムの特徴を理解してもらうために、まずは作業の進め方から紹介しよう。基本となる作業ステップは5つだ(図2)。一番最初は、ユーザーが得たいデータを指定する。次に、システム側では、指定されたデータを求めるための処理方法を、知識ベースから検索する。複数見つかれば全部を表示して、ユーザーに選ばせる。
図2、ユーザーの操作は、5つのステップが1つの単位となる。この流れで、1種類のデータが得られる

必要な処理方法が決まったら、結果を求めるために必要な元データのタイプが自動的に求められる。知識ベースに情報が入っているからだ。システム側では、元データの条件に該当するデータをユーザーデータの中から検索し、それを一覧表形式で提示する。ユーザーは、その中から正しいデータを選ぶ。するとシステム側では、処理を実行して結果データを生成する。ここまでがObject First機能の役割だ。
次にシステム側では、結果データをAuto Expression機能に渡し、適切な表現ルールを通してデータを表示する。もしユーザーが表示方法を気に入らなければ、別な表現ルールを適用させるように指示して、表示方式を修正する。
簡単に説明すればこのような流れになるが、こんな短い解説ではよくわからないと思う。より正確にイメージが伝わるよう、ステップごとに説明しよう。
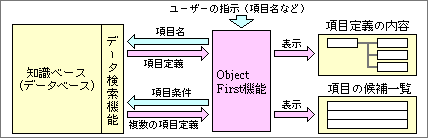
最初に決めるのは、最終的に得たいデータの名前だ(図3)。これを「目的項目名」と呼び、大きく分けて4種類の指定方法がある。1つは、単独のデータで、肥満率などの数値が相当する。2つめは、貸借対照表や組織図といった決まった構造のデータ群だ。構造体に属していて、複数のデータが含まれる。3つめは、モーフィングのように処理を直接していたりする場合だ。本来の形式なら「モーフィングした動画」となるところだが、処理名である「モーフィング」を指定するほうが自然で使いやすい。4つめは、「比較」のように目的自体を直接指定する場合だ。
図3、ユーザーは、最終的に得たいデータを最初に指示する。得たいデータの名前が明確でないときは、その条件を指示して、知識ベースから目的の項目名を探し出す。知識ベースは、複数の検索キーを持つデータベースである
このように、得たいデータといっても、いろいろなケースがあり、それら全部に対応しなければならない。より自然な情報処理を実現するためには、実際の情報処理に合わせたシステムが必要だからだ。
得たいデータを最初に指定するといっても、正式なデータ名を知っているとはかぎらない。そこで、知識ベースから目的項目名を検索する機能もつける。言葉の一部を入力して検索したり、分野を絞って一覧表から選んだり、何種類かの方法を用意する。
最終的には、目的項目名が知識ベースに定義されている必要がある。知識ベースには、単位などのデータ属性も入れておき、処理の自動化に利用するからだ。もし定義されていない目的項目名を得たい場合は、最初に知識ベースに定義する必要がある。とはいうものの、一般的な内容は定義ずみであることが多く、定義データを流通させることも可能なので、ユーザー自身が定義する機会は非常に少ない。
ここで用いる知識ベースは、単純に知識を入れたデータベースだ。人工知能のように、推論する機能を支援するものではない。項目の定義や処理方法の定義など、最も低いレベルの知識を入れる。
「得たいデータといってもいろいろなケースがあり
それら全部に対応しなければならない」
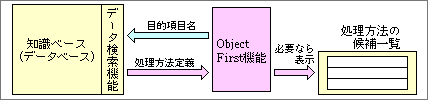
目的項目名が決まると、自動的に処理方法も求められる。それは知識ベースに入っている。求める内容によっては複数の処理方法が該当する場合もあり、そのときはユーザーに選ばせる(図4)。
図4、目的項目名が決まると、それを求めるための処理方法が求められる。複数の処理方法があるときは、全部を候補として表示し、ユーザーに選ばせる。処理内容ごとの簡単な内容説明もいっしょに表示する
ここでいう処理方法とは、計算式であったり、画像処理プログラムであったりする。また、比較といった目的に使う処理では、関連する項目を2次元のテーブルに並べる機能を持つ。
もし目的項目名が肥満率なら、肥満率を計算する処理が選ばれる。また、モーフィングの画像が得たいなら、モーフィング処理が選択される。
貸借対照表のような構造データは、複数の項目を含んでいる。そのため、利用する処理方法も複数が必要で、その全部をシステム側で検索する。つまり、表の中に含まれる項目ごとに、処理方法を見つけるわけだ。
求めるデータによっては、処理を必要としない場合もある。いってみれば単純な検索だ。たとえば、目的項目名として人物データを指示すれば、該当する処理がないので、自動的に検索モードに切り替わる。名前や住所などの条件を加えたければ、続けて入力すればよい。
実際の内部的な処理としては、目的項目名のデータがユーザーデータの中にあるかどうかを、最初に検索する。以前に処理して結果を求めてあることも十分に考えられるからだ。それが見つからない場合にだけ、処理方法の検索へと進行する。
ここで重要なのは、結果を求めるために特別な処理が必要かどうかを、システム側で判断する点だ。ユーザーに選択を求めるのは、結果を得るための処理が必要だと判断し、なおかつ複数の処理方法が候補として選ばれたときだけだ。
ユーザーから見ると、検索と処理が一体化しているため、モードを気にする必要がない。これは、手動で行う情報処理と一致する。得たいデータが作成ずみかどうかは探した時点でわかり、必要なときだけ作成処理を行うからだ。より自然な情報処理システムとして設計するなら、このような視点は重要であり、IOS(情報中心システム)の条件ともいえる。
「目的項目が決まると自動的に処理方法も求められる。
それは知識ベースに入っている」
処理方法が決まったら、処理に必要な元データを選ぶステップに移る。知識ベース内にある処理方法の定義では、元データの種類や属性も含んでいる。
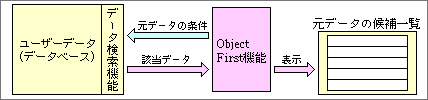
たとえば、肥満率を求める処理なら、身長と体重の2つのデータが必要で、それらがひとりの人物に属していることが条件だ。このように元データの条件さえ明らかになれば、それを満たすデータを、ユーザーデータの中から見つけだすことは簡単だ。該当データを自動的に検索し、一覧表の形で表示する(図5)。1つの該当データが1行で、該当データの数だけ行が並ぶ。ユーザーは、この中から目的のデータを選ぶわけだ。判断しやすいように、元データの値だけでなく、それが属する対象も表示する。具体的には、身長と体重のデータに加えて、属する人の名前も表示する。貸借対照表のような構造体データの場合は、対象となる組織の名前を一覧表で表示する。モーフィングでは、静止画や動画のデータを候補として挙げ、そのタイトルをいっしょに並べる。
図5、処理方法から、必要な元データの条件が決まる。その条件に適合するデータを検索し、候補として一覧表形式で表示する。ユーザーデータも、複数の検索キーを持つデータベースである
該当候補を表示しているあいだにも、システム側では処理を続ける。ただ待っていても、時間がもったいないからだ。候補となるデータを1つずつ処理方法に入力して、求める結果を計算する。ユーザーに表示した内容には、候補データの属性だけでなく、求めた結果も順番に加わっていく。そのためユーザーは、元データを指示する段階で、処理結果を見ることも可能だ。つまり、処理結果を見ながら元データを選べることにもなる。
ただし難しいのは、貸借対照表のように、処理結果が構造データである場合だ。そのときは、構造データの中で重要となる数値だけを表示させればよい。どの数値が重要かは、知識ベースの中で定義しておく。
候補の対象となるデータ数が多い場合は、検索の途中で条件を指定することも可能だ。モーフィングなら、「静止画で人物が映っている」という条件を指示することで、候補の数はかなり少なくなる。条件として指定できるのは、データの属性として定義されているものだけだが、これで十分といえる。前にも説明したように、画像データなら撮影日や対象物を持てるからだ。どのような属性があるかは、知識ベースに入っているので、そこから属性の一覧を表示させ、必要な属性での条件を入力する。ユーザーが条件を記憶しておく必要はない。
一覧表形式で表示した候補を選ぶだけなので、ユーザーの操作は非常に少ない。既存のシステムのように、アプリケーションを起動したり、ディレクトリからファイルを選んだりする必要はない。このことも、本システムの重要な特徴といえる。
ただし、例外がある。処理に必要な元データが保存されていない場合だ。そのときは、入力モードに切り替えて、ユーザーが入力しなければならない。なお、入力機能に関しては、何回かあとで解説する予定だ。
もうひとつの例外は、処理方法に細かな指示が必要なケースだ。たとえば、モーフィングでは、画像の上に何個かのポイントを指定しなければならない。この種の機能を完全に自動化するのは難しい。
「既存のシステムのように、アプリケーションを起動したり
ディレクトリからファイルを選んだりする必要はない」
処理によって求めた最終結果は、表示を担当するAuto Expression機能に渡される。貸借対照表や比較結果を求めるような場合は、個別データをリンクした構造体データとなる。中に含まれるデータは、処理で求めたものだけでなく、検索して見つけ出したものもある。
データに加えて、処理の目的が何なのかもAuto Expression機能に渡す。最初に指示した内容によって、システム側で自動的に判断する。比較のような目的指示では、そのまま渡す。それ以外のケースでは、一般的なデータ表示と判断する。
Auto Expression機能では、渡されたデータの構造などを分析して、表現ルール集から最適なルールを選び出す。何種類かのルールを組み合わせて、表示内容を生成する(図6)。テーブル型のデータであれば、2次元の表として表示する。見出し部分とデータ部分を区分けするための罫線の追加も、表現ルールのひとつとして登録されているので、自動的に生成される。既存のシステムのように、表計算ソフトのセルに値を入力し、罫線を手動で加えるような手間は不要だ。おまけに罫線は、情報の構造を示すようにつけられるため、表示されたデータが読みやすくなる。また、データ数が多いときは、自動的に小さな文字に設定して、表示できる項目数を増やす機能もある。さらには、データを比較しやすいように項目の並び順を決めたり、見出し部分に単位を表示する機能もある。人間のように、単純ミスで単位をつけ忘れるようなことは起こらない。もし数値の単位が異なるときは、自動的に変換して単位を統一する。
図6、処理結果のデータは、リンクで結合された構造体データとなる。それを最適な表現ルールと組み合わせて、表示内容を生成する。表示ルールの中には、表、構成図、関連図、流れ図、グラフなどを作成する機能も含まれる
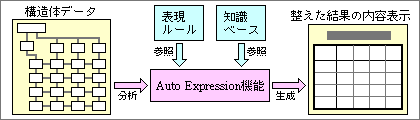
Auto Expression機能では、知識ベースにある定義を参照することもある。貸借対照表のようなデータでは、項目の並び順が決まっているので、それに従って表示内容を生成するからだ。
そのほかにも、構造図や関連図や流れ図をわかりやすく描く機能が表現ルールの中に入る。このことにより、今までドローソフトでつくっていた図の多くは、何も作業せずに得られる環境となる。
ここで紹介したステップは、数値データを求める場合にだけ応用するのではない。論文や提案書などを書く場合に適用し、全体の構成を整えながら制作することを実現する。また、シミュレーションでは、最終目的からシミュレーション環境を整える手順に変える。
このような機能の結果、ユーザーが操作する回数は、既存のシステムと比べて極端に減少する。また、表現ルールを利用するので、内容を理解しやすい表示結果が、ほとんど自動で得られる。さらに重要なことは、コンピュータの使い方を根本的に変えてしまい、本来の目的に集中できる環境が整う点だ。
もっと詳しく説明したいところだが、もう誌面を使いきってしまった。次回は、知識ベースの構造と、その中に入れる内容について解説する予定だ。今回の内容のより詳しい説明は、それ以降で段階的に紹介していきたい。
「さらに重要なことは、
コンピュータの使い方を根本的に変えてしまい、
本来の目的に集中できる環境が整う点だ」
知識ベースと表現ルール集がコンピュータを変える |
