
思考支援:雑誌連載の内容:第3回 |
前回は高度な機能を実現するための基礎となるデータ属性について述べた。今回は個々のデータを組み合わせて、より大きなデータ構造を柔軟に表現できるようにするための仕組みについて解説する。今回までは基本構造に関することなので、具体例には乏しいかもしれないが、次回からは新システムの便利な側面が次々と明らかになっていくので期待してほしい。
「身長」や「体重」といった個々のデータは、測定された人に属する。世の中の多くのデータは、それぞれなんらかの関連を持っているのだが、人間がコンピュータに入力するときに、個々のデータに分断されてしまう。つまり、多くの関連性を断ち切った状態で、入力されるわけだ。
このような欠点はデータの自由な関連を持てないシステム構造に起因する。また、ファイルという区分けにも関連する。ファイル単位でデータを管理するため、ファイルにまたがる関連を持つのが難しいからだ。
新しいシステムでは、この欠点を解消しなければならない。個々のデータが細かな属性を持つとともに、データ間の関連まで入れられる仕組みが必要だ。KIOSM-2では、汎用的なリンク機能で対応する。
前回の例として用いた「身長」のデータには、属性の1つとして、誰の身長であるかを示す対象を含んでいた(図1)。この例のように、データの一部として含める機能のほかに、同じ対象のデータをまとめる機能を追加する。同じ人物の「身長」や「体重」といったデータを、対象者で統合するわけだ。
図1、前回に説明した、属性を持ったデータの例

ただし、ファイルのようにまとめるわけではない。個々のデータや属性はそのままで、それらへのリンク情報を持った構造体で対応する(図2)。一番上に位置するのは、対象となるものの種類で、この例では「人物」となる。単純に考えると、「名前」が一番上に位置しそうだ。しかし、「名前」も属性の1つであり、同姓同名が考えられるので、「親」とするには適さない。一般的な種類を「親」に配置し、「名前」は属性の1つとして持つ。なお、リンクされた個々のデータでは、前回説明したように単位などの属性を持つ。
図2、人物データの構造体。図1のような個々のデータへリンクする形で、人物データを構成する。この図では、リンク先のデータを省略してある
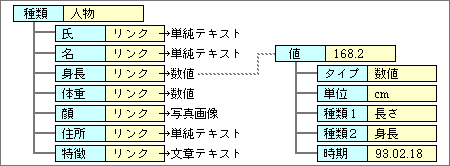
この方法では、個々のデータ側で対象属性を持つ必要がなくなり、全体として冗長性が減少する。リンクをたどることで、対象データの名前を探すことも可能だ。
「世の中の多くのデータは
それぞれなんらかの関連を持っているのだが、
人間がコンピュータに入力するときに
個々のデータに分断されてしまう」
現実のデータでは、複数のデータを組み合わせて1つのデータをつくるケースがよくある。たとえば、「氏名」データは、「氏」データと「名」データを接続してつくる。氏だけで使うことも、氏名として使うこともあり、両方とも意味があるデータだ。
この種のデータを持つとき、「氏」データと「氏名」データを別々に持ったのでは、無駄である。それよりも問題なのは、整合性が保てないケースが出てくる点だ。もし「氏」データと「氏名」データを別々に更新したら、つじつまの合わない状況も考えられる。
これを防ぐためには、データ以外に処理へリンクする機能もサポートする(図3)。リンクされる処理は、他のデータを加工してリンク側に結果を返す形式にする。氏名の例では、「氏」データと「名」データを接続した値を返す。同様に、「年齢」のデータは「誕生日」データと今日の日付から年数を計算する処理へリンクする。
図3、構造体では、処理へのリンクも可能にする。処理が返す値は他のデータを加工した結果だ
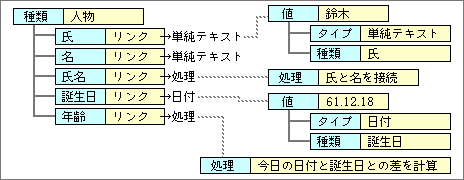
処理へのリンク機能を加えることで、データの整合性を確保できるだけでなく、システム全体の柔軟性を向上できる。
数学や物理などの科学技術の分野では、処理へのリンクを多用する。たとえば、X軸とY軸のデータを個別に持ち、座標データは処理へのリンクとして定義する。その処理では、X軸とY軸のデータを組み合わせて座標データを返す。処理は、値を返す役目だけでなく、値を更新する機能も持たせる。それによって、座標データ側からX軸やY軸の値を更新することが可能となる。どちらからでもアクセスできることで、値の変換に伴う手間や混乱を軽減できるメリットが生まれる。
我々が一般に扱うデータは、よく観察すると複雑な構造を持っている。たとえば、人物データの「身長」だ。この値は、1人の人間に1つだけとはかぎらない。身長は年齢とともに変化するデータで、測定時期によって値が違う。時期をずらして何度か測定すれば、その数だけデータが増える。体重も同様で、測定時期により値が変わる。
これを整理すると、2次元の表になる(図4)。「測定時期」と「身長」と「体重」が1つのセットで、人物ごとに複数のセットを持つことになる。「身長」と「体重」の片方だけを測定するケースもあるので、一部のセルは空になる。このような構造では、縦に並んだ一連のデータが、同じ属性を持つ。「身長」ならば、種類が長さで単位がcmというようにだ。
図4、測定時期の違うデータが複数ある「身長」や「体重」データはこのようなテーブル形式で整理できる。なお、測定時期はシステム共通用語の時期として示してある
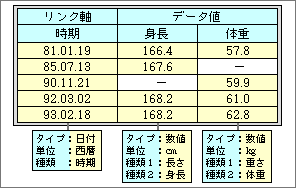
共通する属性を重複して持つのは無駄なので、まとめて持てる仕組みを用意する。この例では、「身長」と「体重」が直接のデータとなる。逆に、「測定時期」は、「身長」や「体重」の値を区別するための属性といえる。図1に示した「身長」データの単純なデータ構造を見れば、測定時期が1つの属性として含まれていることに気がつくだろう。つまり測定時期は、複数データを関連づけるための軸とみなせる。
そこで、この種のデータをリンク軸として定義する(図5)。「身長」や「体重」は、複数のデータが並んだテーブルにリンクしている。複数データの違いを区別するリンク軸として、「測定時期」を持つ。この軸も人物に関するデータの一種だが、本来のデータとは違うものだ。そこで、別にリンク軸用のデータとして親へ接続する。もちろん、リンク軸用データも値を持つので、属性データを含んでいる。この例では、タイプが「日付」のデータだ。
図5、図4のテーブル形式を含んだデータ構造。共通の属性データを経由して、テーブル形式のデータへリンクしている
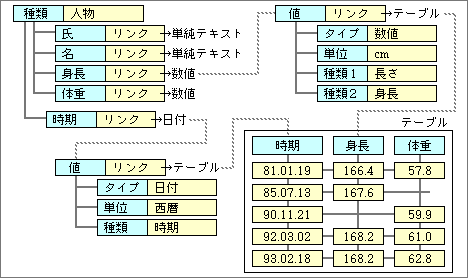
テーブル形式のデータへのアクセスでは、時期を意識しない方法も考慮する必要がある。考え方は単純で、時期データが最も新しいデータを返すようにすればよいだけだ。
テーブルデータの持ち方を工夫すれば、柔軟性をさらに向上できる。テーブル内の個々のデータは単独で保存し、テーブル構造からリンクする形式でつくるのだ。個々のデータは通常は値だけしか持っておらず、上位の属性を利用する。そのうえで、個々のデータにも属性を持てる構造にする。身長の例なら、ほとんどがcm単位のデータで、1つだけインチ単位の数値があり、そのデータだけ単位の属性を加えるのだ。この仕組みなら、テーブル内には属性の少し異なるデータも含めることが可能となり、テーブル機能の柔軟性が向上する。
テーブル形式でデータを持てることは、ほかの一般的なデータにも応用できる。2次元だけでなく3次元以上のデータにも対応させることになる。
テーブル形式で整理するデータには、複数の軸がある。販売計画実績のテーブルなら、「製品の種類」で1軸、「計画と実績」で1軸、「年度」で1軸、「販売地区」で1軸といった具合にだ。このような軸も、リンク軸としてそれぞれに属性を持つ。「年度」なら、年としての属性が入るし、「地区」なら場所に関する属性を含む。また、テーブル内のデータは「計画額」と「実績額」で、金額を表す数値データの属性を持つ。
このテーブルも、データの構造は「身長」と「体重」の例と同じだ。各リンク軸ごとに属性を持ち、テーブル内のデータ用の属性も別に持つ。その結果、テーブルに入る個々のデータは値だけしか持たない。
より柔軟性を高めるためには、ほとんど意味のないリンク軸も持てるようにする。たとえば、同じ実験を何度か測定したときの結果を入れるケースだ。測定データは何個かあり、測定順に番号をつける。この番号をリンク軸にして、測定データをテーブルに入れる(図6)。リンク軸は回数の数値であるが、値自体にそれほど意味はない。たんに値を並べるための番号と考えたほうがよいだろう。
図6、意味のないリンク軸の例。同じ実験を複数回測定した結果をテーブル形式で並べたもので、測定回数をリンク軸に設定している
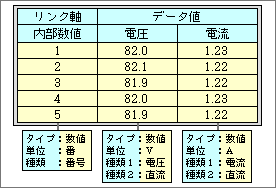
実際のデータでは、このような意味の薄いデータがよくある。ただ番号をつける場合もあるが、番号すらつけないで並べるだけのケースも多い。この種のリンク軸は、軸の値が数値であること以外に、属性を持たなければよいだけだ。属性をつけてもつけなくてもよい構造なので、意味のないリンク軸でも簡単につくれる。
現実のデータは構造体どうしで関連を持っている。たとえば、「人物」データの勤務先だ。複数の人が同じ会社へ勤務しているなら、同じ「勤務先」データへリンクする構造になる(図7)。この例では、勤務先である「組織」データ自体が独立した構造体であり、2つの「人物」データも独立した構造体となる。人物側では、「勤務先」として、「組織」データへリンクする。
図7、二人が同じ場所へ勤める場合のリンク結果。人物データの「勤務先」が構造体にリンクしている
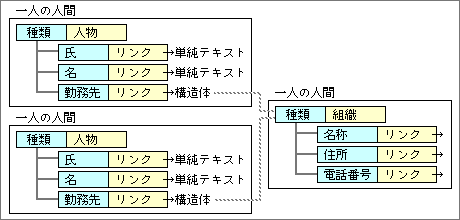
リンクされた「組織」データは名称が「勤務先」データとはならない。「勤務先」という見方はあくまでリンクする側の呼び名だ。リンクする側が変われば、取引先になったり配送先になったりする。これからわかるように、同じ構造体データへのリンクでも、リンクする側に合わせた呼び名が持てる構造になっている。このように情報の特性に合わせてデータ構造を設計することも、IOS(情報中心システム)世代のシステムでは重要な点だ。
さて、リンクした構造体へのアクセスだが、当然リンクした側の呼び名を用いる。この例では「勤務先」なので、「勤務先」の「住所」という形式でシステムへデータを要求する。その結果、組織の構造体側でリンクしている住所の個別データが返される(図7では省略してあるデータ)。もし仮に「勤務先」の「身長」を要求すると、データなしとして返答する。このように、リンクした名称とリンク先のデータ名を組み合わせてアクセスする。リンク先のデータが何重にもリンクしていれば、「勤務先」の「社長」の「長女」の「電話番号」といったアクセスも可能となる。もちろん実際には、データが入力してあって、アクセス権があればという仮定のうえでの話だ。
ここまでの説明でわかるように、リンク機能はデータの構造体を形成する。そして、既存のシステムのファイル形式に相当する構造も、リンク機能を使って実現できる。
しかし、できあがったものには大きな差がある。まず、単位や種類などの属性を持ったデータであることだ。通常のファイル形式だと、単位の違う長さを混在するためには、ファイル形式が対応していなければ難しい。ところが属性を持てる仕組みならば、非常に簡単である。
次の特徴は全部のデータへの関連性を自由に持てる点だ。ファイルという区切りの制約はまったくないため、ほとんど自由に関連をつけられる。
そして最大の特徴は、リンクをたどってデータを得る機能をシステム側で持つ点だろう。ファイル方式だと、アプリケーションがファイル形式を理解して必要なデータを抜き出さなければならない。もちろん、ファイルにまたがったデータへのアクセスは、さらに複雑となる。複数の形式のファイルを読み込んで処理するとなると、プログラムの作成も大変だ。
「IOS世代のシステム最大の特徴は、
リンクをたどってデータを得る機能を
システム側で持つ点だろう」
前回と今回で、おおまかなデータの持ち方を説明した。これまで「構造を持ったデータ」という表現を何度も使ったが、その意味も少しは理解していただけたと思う。
たしかに柔軟性のある仕組みだが、入力するのが面倒ではないかと心配する人もいるだろう。簡単なカード型データベースでさえ、フィールド定義が難しいと思うユーザーが多い状況で、ここで紹介したような凝ったデータ構造を定義できる人は少ないからだ。
もちろん、そのことは十分すぎるほど理解している。そして、この問題点を解消する方法も考えてある。複雑なデータ構造を意識しなくても、きちんとした構造でデータを入力できる仕組みをだ。
ここ2回は、データの基本モデルだけを説明してきたため、システムの動きや機能の全体像が見えず、モヤモヤした気分の人もいるだろう。次回からは、Object First機能を含むシステム全体の仕組みについて説明する予定だ。どれほど便利なシステムになるのか、楽しみに待っていてほしい。
リンク機能で柔軟なデータ構造を実現 |
