
思考支援:雑誌連載の内容:第2回 |
前回紹介した、情報作業環境モデルそのものに関する考え方に引き続き、新システムの基本中の基本となる「データの構造」のあり方について提案する。現在のコンピュータシステムのデータ構造が持つ問題点も浮き彫りにされる。
前回は、今後のコンピュータを設計するための、システム機能の新しい捉え方を示した。その内容は、ソフトとハードに分けるだけでなく、ソフトの上位に位置する「情報作業環境モデル」という論理モデルが重要となるということだ。今回からは、筆者が考える次の世代のコンピュータを「情報作業環境モデル」として提案していきたい。
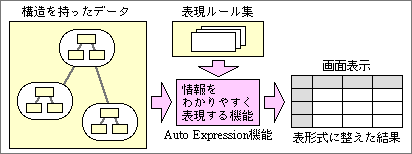
今後1年間ぐらいで紹介するシステムでは、2つの新しい機能が中心となる(図1)。1つはObject First機能で、取得したいデータや目的を最初に指示し、システムと対話しながら求めるものだ。情報作業環境モデルでは操作レベルに位置する。もう1つは、データをわかりやすく表現するAuto Expression機能で、ユーザーと対話しながら最適な情報表現方法を求められる。これは情報作業環境モデルの表現レベルに位置する。この2つを含んだ論理モデルは、筆者が考えたIOS世代の論理モデルなので、KIOSM-2(=Kawamura Information Oriented System Model Level-2)と名前をつけた。レベル2としたのは、『オブジェクト指向コンピュータを創る』で提案したシステムがレベル1にあたるからだ。同書のシステムは、論理モデルとして提案したものではないが、大部分が論理モデルに該当する内容なので、レベル1として位置づけ、名前もKIOSM-1と改名する。
図1、これから1年くらいで紹介する予定のシステムでは、Object First機能とAuto Expression機能を持つ。2つの機能は、情報作業環境モデル上で、それぞれ操作レベルと表現レベルに位置する

将来的には、筆者が提案した論理モデルをもとに、世界共通の論理モデルとなるCIOSM(=Common Information Oriented System Model)に発展できればと考えている。
KIOSM-2の中心となる2つの新機能を実現するためには、システム内でのデータの持ち方が非常に重要となる。Object First機能にしてもAuto Expression機能にしても、データの細かな特性がわからなければ、実現できない。たとえば、数値データなら、それが長さなのか金額なのか、各機能で理解できることが必要だ。さらには、金額だとしたら、どんな項目の金額で単位は何なのかも含める。このような各データの属性を持てなければ、高度な処理を実現するのは難しい。
どのような属性が必要かを検討する前に、現状のシステムでのデータの持ち方を見てみよう。Macを含む多くのシステムでは、ファイルという単位でデータを管理し、アプリケーションが内容を表示する(図2)。ファイルには何種類もの形式があり、アプリケーションに依存したものもある。アプリケーション間で共通したファイル形式があり、それを介してデータをやりとりする。この方式では、アプリケーション内の特殊な機能を使って入力したデータは、ほかのソフトへ渡せない。また、ユーザーはファイル形式を意識しながらコンピュータを使わなければならない。
図2、ファイル中心システムでは、アプリケーションが書類ファイルを読み、表などの形式でデータを表示する。どのように表示できるかは、アプリケーションの機能で決まり、表示内容のほとんどをユーザーがつくる

以前に提案したKIOSM-1では、少し改良を加えてある。オブジェクトドライバに依存したオブジェクトデータとしてデータを保存する。これによって、どんな形式のデータでも自由に組み合わせる環境が整った。しかし、データの内容を分析して、それに応じた高度な処理を実現するまでは含んでいない。
既存のシステム向けとして登場するOpenDocは、ファイル中心システムを残しながら、その欠点を解消し、データの融通性を向上させるものだ。ファイル中心システムとKIOSM-1の中間に位置するもので、ファイル中心システムの欠点も残っている。
これから提案するKIOSM-2では、数値データを中心として、データの細かな属性を持てるように、システム全体を設計する。そうすることにより、各処理がデータの属性を考慮しながら進められる。高度な機能や自動化を実現するためには、個々のデータの属性を知ることが必須だからだ。
「既存のシステム向けとして登場するOpenDocは
ファイル中心システムを残しながら、その欠点を解消し
データの融通性を向上させるものだ」
まず最初に決めるのは、どの程度の細かさでデータの属性を管理するかだ。
それを決定するにあたって、表計算ソフトのワークシートを例に考えてみよう。各セルに入力した数値データは、値の単位を持っていない。また、データの名前もわからない。たいていは、左か上のセルに名前となるテキストを入力してすます。しかし、数値の処理を自動化しようとするなら、単位やデータの種類を区別できる必要がある。それぞれの数値の特性がわかってこそ、いろいろな自動化が可能となるからだ。
このような理由から、数値データは、1つひとつを分けて管理する。当然、単位や種類などを属性として持つ。既存のワークシートのように、見出し部分までユーザーが配置を考えるようなことはしない。元データの属性を参照し、そこから見出しや罫線などを自動生成するためだ(図3)。
図3、Auto Expression機能を持つシステムでは、構造を持ったデータから、表などに整理した形で情報を表示する
次に、数値データに必要な属性を考えてみよう。基本的なものを中心に挙げてみる。
まず必要なのはデータの種類で、どんな内容の数値であるか分類するのが目的だ。具体的には、長さとか重さとか個数といったものがある。それに数値の単位が続く。長さには何種類かの単位があり、それを特定しないと実際の値がわからないからだ。
世の中にあるほとんどの数値データを集めても、それほど多くの種類や単位にはならない。存在するすべての種類と単位を調査し、それを標準化して定義する。
種類と単位があれば、同じ種類で単位が違うデータを比較したり、別な単位でデータに換算したりできる。たとえば、長さのデータなら、メートルからインチへ変換するというようにだ。
長さや重さといった種類よりも、もっと細かな内容まで属性として持つ。同じ長さでも、人の身長や物体の高さなど、いろいろな数値がある。また、何を対象としたデータなのかも知りたい。身長のデータを例にとると、身長を表す数値で、鈴木太郎という人の、25歳のときに測定したデータ、という具合になる。このように、数値の内容を細かく絞り込むための項目まで、属性として含む(図4)。
図4、数値タイプが持つ代表的な属性。種類や単位などが含まれ、数値の内容を細かく表せる

このようにして加えた属性は、すべてのデータが持つとはかぎらない。そこで、わかっている属性だけを持つようにし、不明なら持たないことも可能にする。
最も難しいのは、数値の内容によって属性が変わる点だ。属性の名前の表現がデータ作成者によって違っていては、データの統一性が保てず、いろいろなデータを集めて加工するときに困る。この問題は、多くのデータを標準化することで解決する。この標準化は、入力の手間を軽減する目的でも大きく役立つ。その部分の仕組みは、数回後の入力機能の説明で紹介する予定だ。ここでは、属性が持てる点だけを理解していただきたい。
実際の数値データは、精度や有効桁数を持っている。たとえば、測定で得られた5.2と5.20は、有効桁数や精度が違うデータとして扱う。ところが、表計算ソフトのワークシートで数値を扱う場合、どちらの値でも5.2として入力する。もし5.20と入力しても、強制的に5.2となってしまう。5.20と表示したければ、セルの書式設定で小数点以下を2桁に設定する。このような方法なので、もとのデータが5.2なのか5.20なのかは残らない。
そのためユーザーは、各データごとの有効桁数を覚えておき、必要なときに有効桁数を考慮するしかない。この方法の欠点は、ほとんど手動で精度を計算するしかないことだ。また、有効桁数を理解している人だけしか使えない。
実際の多くの計算では、有効桁数が存在する。もととなるデータの有効桁数が3桁なのに、計算結果を5桁まで求めても意味がない。有効桁数を知らないユーザーには、そのことを知らせるべきだ。より現実的な対応としては、もととなるデータの有効桁数によって、計算結果の桁数を自動的に決める方法がよい。元データの有効桁数が3桁なら、結果も3桁で表示するというようにだ。もしユーザーが詳しい計算結果を求めてきたら、有効桁数の関係で詳しい数値の意味がないことを(可能なかぎり容易な言葉で)説明したうえで、より細かな桁まで表示する。このようなシステムを使っていれば、ユーザー自身が有効桁数の意味を自然に知ることとなる。
もちろん、すべてのデータで有効桁数が必要なわけではない。そのため、データ属性として用意しておき、必要な場合だけ使うようにする。有効桁数の意味がない代表的な例は、金額を扱うケースだ。これは絶対的な値が重要で、元データの桁数に関係なく、1円や1銭の単位まで計算する必要がある。また、処理内容によっても判断でき、自動的に表示を切り替える。
同様に、測定した数値データには精度がある。また、サンプリングによる統計データであれば、母集団の数とサンプリング数との比率から、得られた計算結果の確からしさ(正しい場合の確率)を求められる。これも数値が持つ属性の1つで、処理によっては必要な値である。
このような数値処理上の値も、数値データの属性として持つのがベストだ。最初は使わないかもしれないが、理解が深まるにつれて、だんだんと利用する方向にユーザーが変化する。
円などのドローオブジェクトや画像データは、個々のオブジェクトごとに管理する。既存のドローソフトの1オブジェクトと同じレベルだが、複数のオブジェクトを1つのファイルに保存するようなことはしない。あくまで、ドローオブジェクトごとに1つのデータとして管理する。
この種のデータでは、線の太さや色などの属性が含まれる。具体的な属性は、既存のソフトで持つものと変わりない。ただし、画像データのフォーマットに相当する属性を持つ必要がある。その一部である圧縮方式や色数などは、属性としてデータ本体の外に出し、違いを識別できるようにする。
それ以外の属性として、数値データと同じように、内容を絞り込むためのものを何種類か定義する(図5)。写真の画像データであれば、被写体である対象や撮影日なども属性に含まれる。
図5、写真画像データが持つ代表的な属性。写真の内容を特定できるように、被写体である対象属性も含む。複数のものが写っていれば、対象属性は複数になる

円や四角のようなドローオブジェクトの場合は、属性を持つ意味は少ない。単純に形を描いているだけなので、内容を表す必要がほとんどないからだ。この種のデータでも、数値と同じように必要な属性だけを持つので、データの種類によって属性は異なる。具体的な属性については、種類ごとに標準化する。
現在のシステムでは、ドローオブジェクトを使ってユーザーがグラフィックを描く。構成図や関連図などをドローソフトで作成するからだ。しかし、情報表現機能を持つKIOSM-2では、ユーザーがドローオブジェクトを直接描くことは少ない。この点も、新システムの重要な特徴だ。
テキストデータは、短い1つの単語から長い文章まである。このため扱いが難しく、次の2種類に分けて管理する。1つは単純テキストで、1つの意味だけを含んだテキストだ。もう1つは文章テキストで、単純テキストの条件に該当しないテキストに使い、複数の文章を含んでいることが多い。
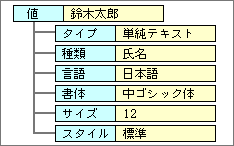
単純テキストのデータは、人の名前とか住所とか、データベースのテキストフィールドに相当するものといえる。つまり、内容が1つだけの意味を持っているテキストデータだ。そのため、データ内容の違いを属性として持つ。「住所」や「氏名」や「電話番号」のように、データベースのフィールドとして使いそうなものが種類となる(図6)。これは、数値データの種類属性に相当する。
図6、単純テキストが持つ代表的な属性。書体やサイズやスタイルはあまり意味がないので、多くのデータでは持たない
単純テキストの中には、「郵便番号」のように数字だけのデータも含まれる。この種のデータは、数字だけで構成されていても、数値データではない。数字かどうかで決めるのではなく、あくまでデータの持つ意味から、数値データかテキストデータかを判断しなければならない。
単純テキストでは、一般的なテキストデータのように、書体や文字サイズなどの属性も持つ。加えて、英語や日本語といった言語属性も含める。この部分に関しては、新しい機能はほとんどない。
単純テキストの種類では、「氏名」が「姓」と「名」の合成であるといった、構造を持てることが要求される。この点に関しては、リンク機能と深く関わるので、そのときにまとめて解説する。
もう1つの文章テキストは、いくつかの文章を含んだもので、長い文章の中の段落に相当する。全体が長い文章であっても、段落ごとに個別の文章テキストに分割し、全体として関連性を持たせる。つまり、段落となる文章テキストを組み合わせて構成した、構造データとなる。そうすることで、必要な部分だけ抜き出して表示することが可能となるからだ。現在のように長々と文章を続けた書き方は、誰もやらなくなる。
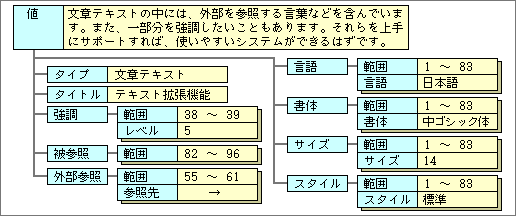
文章テキストのデータは、単純テキストとは違った属性を持つ。文章中でほかのデータ(文章や図版や表など)を参照することもあり、逆に、文章の一部が参照されることもある。また、文章中に重要な数値や言葉を入れるときは、それらを数値データや単純テキストとして独立させ、参照する形で文章テキストを作成する。外に出した重要な数値や言葉は、内容に応じた属性を持ち、ほかの凝った処理で流用しやすくなる。
このような理由から、テキストの一部を参照可能部分として定義できるようにする。1つの文章テキストの中で、複数の参照可能部分を持つこともあるだろう。また、参照している部分や参照されている部分は、そのことがわかるように表示する必要があり、情報表現機能が担当する。
文章テキストでは、書いてある内容をひと言で表すタイトルを加える。ただし、段落ごとに分けて入力すると、タイトルをつける意味がないこともある。だから、必要なときだけつける。一般的には、複数の文章テキストを合わせて、1つのまとまった内容に組み立てる方法をとる。そのため、組み合わせた全体にタイトルをつける必要が生じる。この部分は、組み合わせを実現するリンク機能に依存するので、そのときに説明する。
結果として、文章テキストの属性は、参照などを含んだ構造になる(図7)。
図7、文章テキストが持つ代表的な属性。参照したりされたりするので、参照関連の属性を持つ。また強調のような作成者の意図を含める属性もある
既存のワープロ書類のテキストデータでは、文中に強調したい部分があると、下線や太字にスタイルを変更する。このような方法では、強調という同じ表現でありながら、書類ごとに表示スタイルが違ってしまう。この方法の根本的なまちがいは、「強調」と指定すべきところを、スタイル変更ですましている点だ。「強調」という属性がないことが理由なので、こういう結果になってしまっても仕方ないといえる。
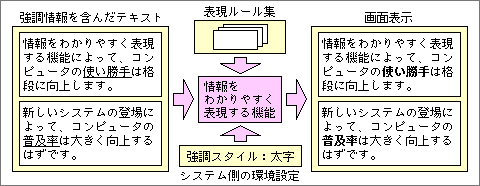
しかし、IOS世代のシステムでは、テキストデータに「強調」のような属性を持たせる。それも、単純な強調ではなく、何種類かの違う強調が使えるように、数レベルの強調を指定できる。
強調部分がわかれば、システム全体での表示方法も統一できる。強調のレベルに応じて、何種類かのスタイルをシステム側で設定しておく。そのスタイルは、ユーザーのマシンごとに変更可能で、自分が見やすいスタイルを設定すればよい(図8)。その結果、すべての文章テキストで強調部分が同じスタイルになり、情報の見やすさは向上する。同様に、参照されている部分も全部を同じスタイルで表示する。
図8、文章テキストの強調部分は、システム側で設定したスタイルで統一的に表示する。これによって、どのテキストデータでも強調部分だと簡単に判断できる。この機能をオンすると、文章テキストが持っている書体やスタイルは無視される
このような考え方は、情報をわかりやすく表示するための基本的なものだ。テキストデータにスタイル変更の機能をつけるのではなく、作成者の意図にできるだけ近い形で、属性が設定できるように仕組みをつくる。これこそ、IOS世代のシステムに必要な設計上の視点といえる。
「テキストデータにスタイル変更の機能をつけるのではなく、
作成者の意図にできるだけ近い形で
属性が設定できるように仕組みをつくる」
今回述べた属性は、あくまで基本的なものだけだ。誌面スペースの関係から、代表的なものだけを選んである。また、今後紹介する新機能を実現するときに、新しい属性が必要となる。それは、機能を紹介するときに加えることにする。
ここで紹介したようなデータの持ち方だと、1つの数値データに対して、その何倍もの属性を持つ印象を受けるだろう。しかし、属性自体も数値に関するデータなので、データの細かさが向上したと認識するのが正しい。持つべきデータが増えると問題になるのが、入力に手間がかかる点だ。それを軽減する新しい仕組みについては、データ入力機能を解説するときに紹介したい。
賢明なる読者の中には、「これだけ細かな属性を持ったら、かなり高度な処理を実現できそうだなあ」と感じた人がいるだろう。その勘はズバリ当たっている。これから数回あとに、その答えとなる新機能が出てくる。
今回のデータ構造は、データのリンクを考慮しない条件での結果だ。実際には、いろいろなデータが関連している。身長と体重の数値データに、同じ人の名前を含めるのは、明らかに無駄が多い。それを防止して冗長性をなくすためには、データを関連づけて持つ仕組みが必要だ。そこで次回は、今回説明したデータ構造をもとに、それらをリンクさせる仕組みを紹介する。
高度な機能の基礎となるデータ属性 |
