
思考支援:雑誌連載の内容:第1回 |
「オブジェクト指向」......。タリジェントやマイクロソフト、ノベル、サン・ソフトなどの主要OS会社が開発に取り組んでいるシステムは、必ずこのキーワードがベースになっている。しかし、この次にどんなコンピュータが出てくるべきか、ということに関してはあまり検討されていないようだ。そこで本誌では、川村渇真氏が考えた「思考支援コンピュータ」というシステムを連載で詳しく紹介し、それと対照する形で現在アップルが実現している技術についても見ていきたい。そこで登場してくる新しいキーワードは「思考支援」だ。
読者のみなさんは、現在使っているコンピュータを、使いやすいと感じているだろうか。たしかに、10年以上前には予想もできなかったレベルまで、コンピュータは進歩している。
以前に比べれば操作方法も簡単になったし、扱えるデータの種類も増えた。今では、動画までもが当たり前に使えている。しかし、本当に使いやすくなったのだろうか。
かなり前に筆者は、現在のコンピュータの進歩の方向に、大きな疑問を持った。「このままユーザーインタフェースを改良し続けて、使いやすさが大幅に向上するだろうか」と。また「期待のオブジェクト指向技術は、使いやすさの向上には、ほとんど貢献しないのではないか」とも。
このような疑問から出発して、自分なりの未来のコンピュータを考えるようになった。構想はだんだんと固まり、人に説明できるまでになった。そして構想の一部を、単行本の形で公開した。それが『オブジェクト指向コンピュータを創る』(アスキー刊)である。
この本の内容は、筆者が考えている新しいコンピュータの全体像からすると、数分の1でしかない。その先には、より使いやすいコンピュータのアイデアが控えている。本連載は、その本の続編に位置づけられるもので、数分の1の残りを紹介するのが目的だ。当然、新しいコンピュータの仕組みを提案する内容となる。
このような理由から、後述する今回の内容に興味を持たれた読者は、ぜひとも『オブジェクト指向コンピュータを創る』を読んでいただきたい。本連載の内容をより深く理解できるとともに、筆者の構想の基本部分もわかっていただけると思う。
当然のことだが、夢物語を語ろうというのではない。現実に動作してユーザーが使えるコンピュータを対象としている。現在のCPUパワーやメモリ容量では難しくても、5〜10年後のハードウェアで動くことを前提として考えている。
今回は、初回ということで、次世代コンピュータを考えるための切り口となる、コンピュータの新しい捉え方について述べる。これを理解すれば、本連載の目的もいくぶん見えてくるだろう。
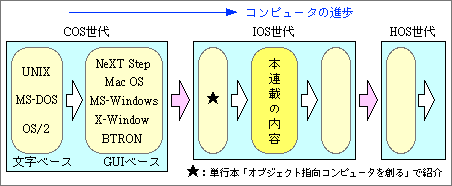
筆者が『オブジェクト指向コンピュータを創る』で提案したシステムは、1つの流れの中の第一歩として位置づけられる。本を読んでない人のために、その流れ(図1)を簡単に解説しよう。
図1、コンピュータの進歩の流れ。現在のコンピュータはCOS(コンピュータ中心システム)だが、次はIOS(情報中心システム)へと移行する。その先には、HOS(人間中心システム)が待っている。本連載では、IOSの第2世代の中身を紹介する予定だ
既存のコンピュータは、あくまでコンピュータ技術が中心となって設計されている。オペレーティングシステム(OS)という基本部分があり、その上でアプリケーションソフトが動く。最初にOSを設計し、それに合わせる形でアプリケーションソフトをつくる。このような設計手順のため、OS部分ではコンピュータ技術が中心になり、アプリケーションは、その制約から抜け出せない。具体的には、ファイルというデータを扱う単位も欠点の1つで、ユーザーに余分な手間と知識を要求するだけでなく、データの融通性を大きく阻害している。
このような世代のコンピュータを、筆者はCOS(Computer Oriented System:コンピュータ中心システム。カライダが開発を中止したC/OS、すなわちConsumer OSとはまったく異なる)と呼んでいる。ユーザーインタフェースを改良したMacintoshでさえ、ファイルやアプリケーションといった概念が中心となり、COSの範疇に含まれる。COSの第1世代を文字&コマンドベースのシステムとするなら、グラフィカルなユーザーインタフェースを持ったMacintoshやWindowsは、COSの第2世代となる。
その次の世代に位置づけられるシステムは、コンピュータ技術が中心となるのではなく、人間が扱う情報自体を中心に設計したものとなる。その意味で、IOS(Information Oriented System:情報中心システム)と呼ぶ。ファイルやアプリケーションといった仕組みはなく、情報(データ)と機能を前面に押し出したシステムとして、ユーザーからは見える。ソフトを動かすという感覚で使うのではなく、情報そのものを見たり加工したりするという意識で、ユーザーはコンピュータを使用する。あくまで中心は情報そのものなのだ。
また、データ間に自由な関連を持てるため、構造を持ったデータとして保存可能だ。関連づけるデータのタイプ(文字や画像など)に制限はなく、コンピュータ上で扱える全タイプのデータが対象となる。つまり、ユーザーインタフェースの次は、データの扱い方(データハンドリング)の改良が重要となる(図2)。
図2、コンピュータを使いやすくするために、まずユーザーインタフェースが改良され、現在に至っている。その次はデータハンドリングの改良で、すでに『オブジェクト指向コンピュータを創る』で紹介した。問題はさらに次で、本連載のテーマでもある

IOSの先として、HOS(Human Oriented System:人間中心システム)がある。当分のあいだ(今後10年ほど?)は夢のような話なので、ここでは触れないことにする。
「ソフトを動かすという感覚で使うのではなく
情報そのものを見たり加工したりするという意識で
ユーザーはコンピュータを使用する」
IOSに含まれる最初の世代のシステムとして、筆者は『オブジェクト指向コンピュータを創る』を書いた。それは、オブジェクトドライバとオブジェクトデータという構造を採用し、ユーザーはデータ(=情報)中心でコンピュータを操作する。新しいタイプのデータは、そのオブジェクトドライバを追加するだけで、簡単に扱えるようになる。個別のデータを扱うのは、オブジェクトドライバだけに依存し、それらをどのように組み合わせるかは、別な種類のドライバが担当する。その結果、組み合わせ用のドライバは、データのタイプに依存しないだけでなく、どのようなデータでも扱える。
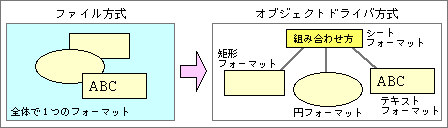
このような構造を実現するのは、オブジェクトデータ(文字や画像など)をリンクさせる機能だ。たとえば、シート上に異なるデータを配置する場合、シートとオブジェクトデータをリンクさせるだけでよい(図3)。このシート自体も、シート型のオブジェクトドライバのデータであり、色やサイズなどの情報を持つ構造になる。
図3、シートオブジェクトに、個別のオブジェクトデータを張り付けるイメージで、データのリンクが構成される。シートオブジェクト自体も、リンク型オブジェクトドライバのデータとなる
さらに重要なのは、アウトラインプロセッサや多次元ワークシートやデータベースの機能も、オブジェクトドライバとして実現することだ。現在はアプリケーションとして提供されているこれらの機能は、よく考えるとデータの関連を定義するという根本的な役割がある。アウトラインプロセッサは、階層的にデータを整理し、表計算ソフトに代表されるワークシートは、2次元や3次元の表形式でデータを整理するものだ。データベースはもう少し複雑で種類があるが、データを整理する機能に変わりはない。
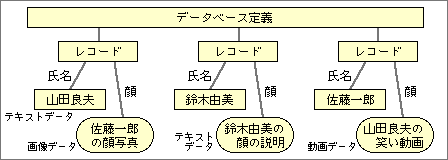
これらのデータ整理機能は、データリンクの拡張として実現する。当然、データ整理用のオブジェクトドライバとなり、実際のリンク情報がオブジェクトデータとなる。リンク部分の情報だけを独立したデータとして持つため、扱うデータのタイプには依存しない。データベースなら、データ定義するときに、データのタイプを決める必要はなくなる。たとえば住所録で、顔データが写真であったり動画であったり、顔の特徴を説明したテキストデータでもよい(図4)。このようなことが可能になるのは、データベースなどがリンクの延長として実現するからだ。
図4、データベース機能はリンク型オブジェクトドライバで、リンク情報が中心となる。そのため、1つの項目で違うデータのタイプを簡単に持てる
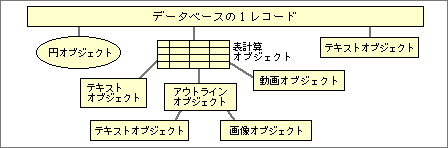
データ整理機能を独立されることは、より大きな融通性を実現する。ここで大切なことは、リンク情報自体もオブジェクトデータである点だ。それにより、データ整理機能が何重にも組み合わせて使える。たとえば、データベース内の1つのデータとして3次元ワークシートが入れられ、そのワークシート内の1セルにアウトラインデータも含められる(図5)。これらは基本的にリンク機能なので、最終的には、テキストや画像などの情報データにたどり着く。
図5、リンク型オブジェクトドライバは、複数を自由に組み合わせられる。データベースの中に3次元ワークシートがあり、その1つのセル内にアウトラインデータを入れることも可能だ
この結果、システム全体が統合ソフトのエンジンを持っているように動く。現在のシステムと比べて、使いやすさは格段に向上する。
このようなドライバ&リンク構造は、ソフトを開発する面でも大きなメリットを生む。オブジェクトドライバごとに開発すればよいので、新しいタイプのデータを扱うドライバを簡単に追加できる。それらを自由に組み合わせて使えるため、機能的には特別な制限などない。結果として、使えるアプリケーションが何本あるかといった低次元の自慢競争をしなくてすむ。アプリケーション&ファイル形式のシステムより、はるかに融通性のある環境が実現できるからだ。
既存のシステムも、現在の問題点に気づきつつある。しかし、今あるソフトやデータとの上位互換を保たなければならない。そのため、アプリケーション間でデータをリンクする方法で、欠点を解消しようとしている。そのための仕組みが、OpenDocやWindowsのOLE(Object Linking & Embedding、OpenDocよりも低次のオブジェクトリンクを実現するもの。最初のバージョンは発行と引用程度)だ。もちろん、ファイルというデータの保存単位には変化がない。
このような改良方法の最大のメリットは、既存のアプリケーションやファイルを使い続けながら、だんだんと新しい環境へ移行できる点といえる。すでに稼動中の多くのマシンが存在する現状では、しかたのない選択だろう。
当然のことながら、互換性を保ったままの新システムへの移行では、使いやすさの面で完成度は低くなる。アプリケーションを意識して使わなければならないし、データベース機能やアウトライン機能を自由に組み合わせて使うことも難しい。とはいうものの、良い方向に向かっていることはまちがいないので、できるだけ早期に実現することを期待したい。
このような状況を踏まえながら、本連載の内容は、さらに先のレベルのシステムを提案するものとなる。ユーザーの使いやすさをより深く分析し、もっと便利で高度に役立つシステムが目標だ。目標といいながら、その内容はすでに頭の中にある。その最初のレベルを、1年くらいかけて紹介していきたい。
初回ということで、前置きが長くなってしまった。いよいよ第1回の本題に入る。コンピュータを大幅に使いやすく進歩させるためには、システム全体を新しい考え方で捉えることが重要となる。
コンピュータが開発された初期には、ハードウェアが中心で、ソフトウェアはつけ足し的な位置づけだった。それが現在では、ソフトウェアの重要性が認識されるまでに変わった。大切なのは、その次の段階だ。ユーザーインタフェースという狭い範囲で改良を考えるのではなく、コンピュータ上で情報を扱う作業全体を見直す時期にきている。「どのような仕組みに変更すれば、情報を扱いやすいのか?」。これが重要なポイントだ。
その意味から、ソフトウェアの上位に位置づけた「情報作業環境モデル」を提案する(図6)。これは、コンピュータ上で人間が情報を扱うこと全般を、1つのまとまったシステムとして捉える。そして検討結果を、操作まで含めた論理モデルとして定義する。このモデルは、コンピュータ内部でデータを保存するときの形式は含まれず、あくまでユーザーから見えるデータ構造を定義するだけだ。もちろん、データを操作する機能も含む。これらを検討するときの重要な点は、情報を扱う作業がやりやすくシステムを設計することにある。これを無視すれば使い勝手の大きな進歩は望めない。
図6、これからのコンピュータの捉え方として、ソフトウェアの上に「情報作業環境モデル」を加える。その部分は、何をつくるかという実現内容を定義するものだ。下の2つのソフトウェアとハードウェアは、定義したモデルを実際につくる部分として位置づけられる
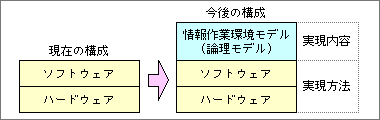
このような捉え方だと、情報作業環境モデルは操作まで含めた論理モデルで、コンピュータとして実現する内容を定義する部分になる。残りの2つであるソフトウェアとハードウェアは、どのようにつくるかといった実現方法に対応する。つまり、実現内容を独立して考え、それに従う形で実現方法を求めるという段階に、コンピュータの設計が移るわけだ。
コンピュータの特徴としては、論理モデルが正確に設計されていれば、実現するのは比較的容易な点が挙げられる。あとは、ハードウェア上の制約であるCPUパワーやメモリ容量などが整った段階で、実際に動かす条件が得られる。その点でも、論理モデルを採用する意味は大きい。
コンピュータの根本的な進歩が現状で足踏みしているのは、実現内容を中心に考えることに、頭脳を集中していないからだ。今後は、ゆっくりとであるが、その方向に向かうだろう。
余談だが、現在注目されているオブジェクト指向技術は、実現方法の1つであって、3階層のソフトウェア部分に含まれる。ということは、オブジェクト指向を突き詰めていっても、実現方法の改良には貢献するが、新しいコンピュータを求める作業には関係ないことがわかる。
「コンピュータの根本的な進歩が現状で足踏みしているのは、
実現内容を中心に考えることに、頭脳を集中していないからだ。
今後は、ゆっくりとであるが、その方向に向かうだろう」
これからのコンピュータを考えるうえでは、最上位に位置する「情報作業環境モデル」が重要だ。そして、情報作業環境モデルは、3レベルに分けて捉えられる(図7)。下から順番に、操作レベル・表現レベル・創造レベルだ。それぞれ順番に、概要を説明しよう。
図7、「情報作業環境モデル」は、3つのレベルに分けられる。上位レベルほど実現が難しいが、達成したときの意味は大きい
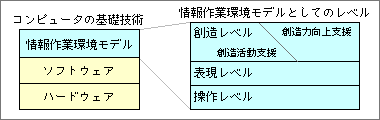
一番下に位置する操作レベルは、情報の操作・表示・保存・検索などを扱う。最も初期段階の改良は、メニューやボタンといった基本的な操作アイテムを用いたユーザーインタフェースの改良だ。次の段階では、使いにくさの原因となっているファイルやアプリケーションという概念を取り払い、オブジェクトドライバとオブジェクトデータという概念で情報を扱う。この部分の細かな内容は、『オブジェクト指向コンピュータを創る』で述べた。
その次の段階になると、最終的に得たい情報を最初に指定し、それを求めるためにシステムと対話する機能(Object Firstと命名)が実現する。最初に指定する内容としては、「製品Aと製品Bを比較したい」や「山田一郎氏の電話番号」や「我が社の過去3年の製品群別シェア」といったものだ。指示した目的をもとに、システムと何段階かの対話をしながら、最終的なデータを求める。ユーザーは、システム側からアドバイスを受けるとともに、検討対象データの所在をシステムへ教えたり、直接入力したりする。
この段階までくれば、ソフトを使っているという現在の感覚とは、大きく違う印象をシステムから受ける。ユーザーは、コンピュータがかなり賢い相談相手のようだと感じるだろう。かといって、エージェントと呼ばれるような人形が登場するわけでもない。この部分の具体的な操作方法や動作原理(=論理モデル)は、今後1年ぐらいで明らかにしていく予定だ。
さらに次の段階では、より融通性の高いデータコンバータが内蔵される。ユーザーからのシステムへの入力や指示は、最低限にすませられる。もう一段、コンピュータ側が賢くなるわけだ。
中段に位置する表現レベルは、情報を加工して表示する機能を提供する。最初に登場するのは、対象データを理解しやすく整えて表示する機能だ。
現在のシステムでは、データの並び方を工夫する機能がない。たとえば、表計算ソフトのワークシートでは、どのようにセル内のデータを配置するかは、作成するユーザーが考えて決める。当然、データの並び方によっては、わかりにくい表ができあがる。同様にHyperCardのスタックでも、カード上のフィールドの配置によって情報のわかりやすさが決まり、スタックの作者の力量に左右される。
新しいシステムでは、システム側で全体のレイアウトやデータの並びを整え、ユーザーが理解しやすい形でデータを表示する。作成する側がレイアウトを毎回考える必要もなくなる。
ここで問題なのは、わかりやすく情報を整えるルールだ。そのルールが明確に求められなければ、この種の機能を実現するのは難しい。具体的な表現ルールを示したものとして、筆者の書いた『HyperCard User Interface Guideline』(アスキー刊)がある。この本は、情報をわかりやすく伝えるためのルールを、スタックづくりに適応させたものだ。同様のルール集は、表計算ソフトのワークシートやワープロ書類やデータベースの表示&入力レイアウトのためにもつくれるし、より一般的な情報表現ルールの形でもつくれる。大切なのは、集めた表現ルールの特性を分析し、使いやすいシステムとして組み込むことだ。
多くの人がわかりやすいルールは何種類かあり、ユーザーごとに最適なルールが異なる。そのどれを使うかは、ユーザーが指定できるように仕組みをつくる(図8)。どのような情報のケースで、どの種のルールが気に入ったかを学習させれば、ユーザーに適したルールを、自動的に一発で選ぶ機能が実現する。
図8、「情報作業環境モデル」の「表現レベル」で最初に組み込まれるのは、情報をわかりやすく表現する機能だ。たくさんの表現ルールを参照しながら、ユーザーの好みに応じた情報表現が得られる
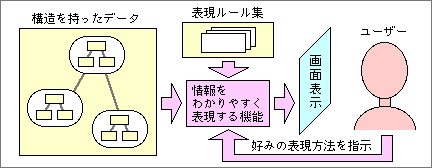
この部分の具体的な内容と動作原理も、前述の操作レベルの論理モデルのあとで、紹介する予定だ。わかりやすく情報を整える機能以外にも、情報表現レベルの機能はある。どのような内容かは、いずれ明らかにしていきたい。
最も上に位置する創造レベルは、人間の創造的な活動を支援する機能を提供する。また、この部分は「創造支援」と「創造力向上支援」の2つに分割できる。
創造支援機能は、考えが行き詰まったときに、発想のトリガーとなる情報を提供する。このレベルの機能を組み込んだコンピュータになると、身の回りの多くの情報を入れておき、何でもコンピュータ上で考えをまとめる時代になる。つまり、検討中の内容のデータは、すべてコンピュータ内に入っている可能性が高い。そのデータをもとに、検討する価値がある方向や、考え方を変化させるような情報を見せる機能がつく。
創造力向上支援機能は、ユーザー自身の創造力自体を向上させるものだ。コンピュータを使っていながら、切り口や検討項目などを思いつく能力が向上する。その機能を意識せずに創造能力がアップするように、システムの深い部分に本機能を組み込む必要がある。
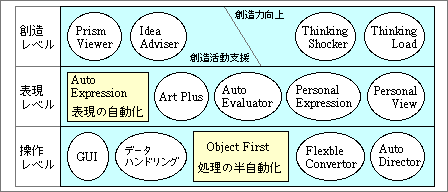
IOSの最上位である創造レベルまでのコンピュータは、かなりの高い確率で実現可能だ。人工知能を実現するよりも、はるかに簡単だ。どのような方法で実現するかは、ある程度までメドが立っている(図9)。ここに示した○印が、その実現アイデアの仮の名称だ。今後10〜15年で内容を煮詰め、順次発表する予定でいる。
図9、IOS(情報中心システム)世代である「情報作業環境モデル」の3レベルで、筆者が考えている解決アイデアの仮名称。○印の部分がそれで、すべて論理モデル。□印の部分は、ここ1年ぐらいの間に本連載で紹介する予定の論理モデル
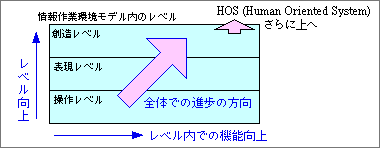
IOS世代のコンピュータの進歩は、情報作業環境モデルの3レベルと密接に関係している。1つのレベル内での進歩に加えて、上のレベルへの進歩もある(図10)。結果として、図の右上の方向へと進む。
図10、IOS(情報中心システム)世代である「情報作業環境モデル」の3レベルでの、コンピュータの進歩の方向。まずレベル内で機能が向上し、しだいに上のレベルの機能が加わる。IOS世代がひととおり終わると、HOS(人間中心システム)世代のコンピュータに移行する
ここまでの説明からわかるように、情報作業環境モデルは、コンピュータとは違う技術も必要となる。つまり、これからのコンピュータは、コンピュータ分野の技術的な知識だけでは設計できない。より広い範囲の知識が必要となる。特に上位の2レベルを設計する段階では、その傾向が強い。
当然のことだが、コンピュータ技術の高い知識も要求される。コンピュータ上で実現できない論理モデルを定義しても、実際に動くシステムにはならないからだ。現在のソフトウェア&ハードウェアで可能な機能を理解して、そのうえで動作可能な論理モデルを設計する必要がある。その意味では、コンピュータ技術に加えて、情報作業や情報表現の高レベルな知識が必要となる。さらに上の創造レベルでは、創造性の教育に関する知識も要求される。
しかし残念なことに、多くのソフトウェア技術者は、情報をわかりやすく表現するのが苦手である。コンピュータを相手にしているため、一般の情報をわかりやすく表現する機会が少ない。これでは、新しいコンピュータを設計する最低レベルをクリアするのが難しい。
現在のコンピュータ設計では、一般の情報を扱う部分を「アプリケーションの仕事だから、システム側には関係ない」と決めていた。そのような考え方は、今後のコンピュータ設計には通用しない。設計者に要求される技術が大きく変化する時期にきたことが、コンピュータの根本的な部分の進歩を遅らせている大きな原因かもしれない。
最も厄介な問題は、コンピュータ技術と情報表現技術が、かなり違う種類のものだということだ。そのため、両方が得意な技術者というのは、かなり少ないと予想できる。
しかし、そのような人材は必ず現れるものだ。情報をわかりやすく表現することが重要だと気づいた技術者が増えることで、両方の適性を持った人材が出る可能性も高くなる。そして、新しいコンピュータの設計に参加することになるだろう。設計者の適性の変革段階を通り過ぎれば、コンピュータの大きな進歩が得られるはずだ。本連載はその変革へのトリガーとしての役目も背負っていると、筆者は考えている。
次回からは、Object First機能を実現するために、どのような論理構造でデータを持つかについて、細かく検討してみたい。
「しかし残念なことに、多くのソフトウェア技術者は、
情報をわかりやすく表現するのが苦手である。
コンピュータを相手にしているため、
一般の情報をわかりやすく表現する機会が少ない」
情報作業環境モデルが重要な時期がやってきた |
