
思考支援:雑誌連載の内容:第6回 |
前回は、知識ベースに入れる内容について、基本部分を紹介した。今回は、残りの内容について解説する。知識ベースには、項目や処理の定義だけでなく、項目や処理の中身を説明したヘルプ情報も含める。状況に応じて使い分けられるように、3レベルの説明データの形式を用意する。また、入力や表示における理解しやすさを向上させるために、レイアウト定義も加える。入力ミスの防止に加え、内容理解に役立つ。さらには、テキストデータから個別のデータを抜き出すための、文字列パターン定義も入れる。これらの定義を加えることで、本システムの使いやすさがさらに向上する。
知識ベースの役割は、項目や処理内容を定義して、自動化を実現することだけではない。ユーザーの使い勝手を向上させるとともに、扱うデータや処理の内容を理解させる機能も重要だ。
ユーザーの知識には、かなり個人差がある。ある分野では専門家であっても、ほかの分野に関しては素人となる。専門家になる前は、誰でも素人だったはずだ。未知の専門分野における処理では、各項目や処理の説明が重要になる。それがシステム上で調べられれば、処理を実行しながら勉強するといったことも可能だ。
せっかく知識ベースという仕組みがあるのだから、これを上手に拡張して、その中に説明データを入れる。ただ入れるだけでは不十分だ。問題を解決する作業の中で、関連する説明データが、簡単に呼び出せなくてはならない。
それに加えて、定義した項目や処理の内容を理解しやすく表示することも、内容理解を助ける。項目や処理ごとに、これまで使われている情報の見せ方が存在するので、その情報も知識ベースに入れる。それをAutoExpression機能が利用し、よりわかりやすく表示するわけだ。
このような改良を加えることで、システム全体の使い勝手は大きく向上する。今回説明する内容は、この範囲に含まれるものだ。重要なものから3つ選んだので、順番に説明していこう。
「せっかく知識ベースという仕組みがあるのだから、
これを上手に拡張して、その中に説明データを入れる」
ヘルプ機能で表示する説明データは、項目だけでなく、処理方法や構造体にもつける。説明データの形式を標準化することで、表示するための処理も共通ですませられる。
説明のデータは、用途を考慮して3種類用意する。簡単なものから順番に、1行表示のテキスト、1画面表示の図版とテキスト、対話型の詳細説明だ。
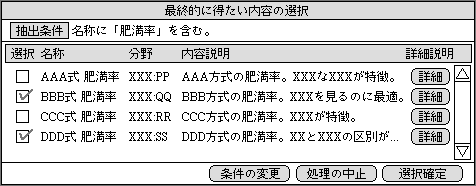
1行表示のテキストは、最終的に得たい項目や処理を選ぶときの候補表示で用いる(図1)。自動的に表示する点が最大の特徴で、似たような項目の違いを知らせ、誤解を防ぐことが目的だ。1行といっても、表示する領域の幅は可変なので、短い言葉を連ねて説明する。最初に重要な言葉を入れ、だんだんと詳しくなる言葉を加える。そうすることで、短い表示領域でも最低限の意味を伝えられ、表示領域が増えるごとに詳しく説明できる。
図1、最終的に得たい項目名を決めるときの、候補を表示する画面表示。複数の候補を選んだときは、そのすべてを求めてくれる。なお、この例は、全体的なイメージを伝えるためのもので、最終的なものとは異なる。
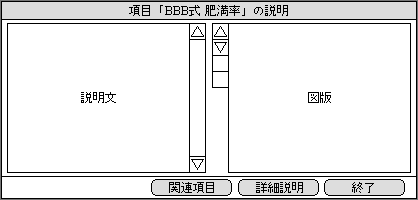
1画面表示の図版とテキストは、より詳しい意味を説明するときに用いる。必要なときだけ、ユーザーの指示により表示する。前述の候補一覧の画面では、候補ごとに呼び出しボタンがつく。少し長い文章と数個の図版で構成する。どの項目でも共通の表示機能によって、文章と図版のデータが呼び出される(図2)。また、関連する項目の説明を呼び出す機能も加える。
図2、1画面のヘルプ表示。1つの説明文章と数個の図版で構成し、図版を切り替えながら読む。この例も、イメージを伝えるためのもので、最終的にはより多くの機能が加わる。
対話型の詳細説明は、本システムで扱えるデータなら、ムービーでも何でも入れられる。リンク構造を持ち、AutoExpression機能を利用して表示する。その分野をまったく知らない人が対象だ。各項目ごとに用意するのではなく、関連する項目をひとまとめにして作成する。
これら3つのうち、1行表示テキストと1画面表示の図版&テキストは、すべての項目や処理で必須とする。対話型の詳細説明だけは、任意でつけるというルールになるが、できるだけ多くの項目に用意することも大切だ。
「貸借対照表」のような構造体では、表示するときの項目の並び方が決まっている。左側に「資産」が、右側に「負債・資本」が位置する。このような配置は、長い歴史から生まれたもので、多くの人が共通して使っているため、内容を素早く理解できるメリットがある。わかりやすく表示するためのAutoExpression機能でも、このような部分は尊重すべきだ。
そこで、知識ベースには、項目の配置に関する情報を入れる。それをAutoExpression機能が参照し、最終的な表示内容を生成する。領域を縦横に分割し、どの部分にどの項目が位置するのかを、情報として持つ。これをレイアウト定義と呼び、構造体定義の一属性として入れる。
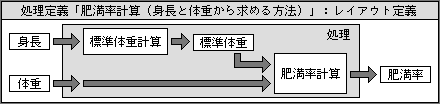
レイアウト定義は、画面上の配置だけに限らない。個別の情報をわかりやすく表示するためには、絵を上手に利用する方法が効果的だ。そこで、グラフィックデータと各項目を自由に配置したものも、レイアウト定義として持てるようにする。物の大きさを示す「外形寸法」の構造体定義なら、「幅、奥行き、高さ」の3項目を絵で表現できる(図3)。また、体の寸法などでは、人間の絵と一緒に示すことで、どの部分の長さなのか明確に伝わる。同様に、何段階かの処理については、ブロック図を示すレイアウトがあれば、入力ミス防止や表示での内容理解を助ける(図4)。このような利用方法があるため、処理定義にもレイアウト定義をつける。
図3、構造体定義「外形寸法」に含める、レイアウト定義の1つ。単純な絵と組み合わせるだけで、各値の意味や関係が直感的に理解できる。このレイアウトは、データの入力や表示で使われる。
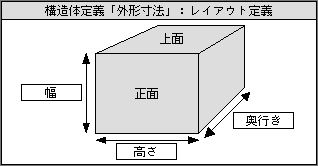
図4、処理の流れを示すブロック図を、レイアウト定義として加える、データ入力と結果表示に利用する。これは単純な例だが、もっと複雑な処理では効果が大きい
レイアウト定義は、もっと違う形式も追加できるように、基本部分のデータ構造を決める。最初に形式番号を入れ、次に実際の定義データを続ける。このような構造なら、あとから新しい形式のレイアウト定義を追加できる。ただし、AutoExpression機能と連動するものなので、表現ルールも一緒に追加する必要がある。
既存システムで入力したデータは、文章のようなテキスト形式がほとんどだ。それを本システムに取り込むと、文章テキストのデータになる。文章中に含まれている各種の数値や名前などのデータは、手作業で個別に取り出すしかない。
しかし、少し工夫するだけで、抽出の処理を半自動化できる。それは、知識ベースで定義した項目ごとに、文字列のパターンを定義する方法だ。たとえば日本の電話番号なら、「0Z-ZZZZ-ZZZZ」(ここでZは数字を意味する。この例ようなパターン定義は、正確性に欠ける表現なので、実際には違う方法を用いる。あくまで説明用)や「0ZZ-ZZZ-ZZZZ」のように、限られたパターンに絞れる。考えられる文字列パターンを何種類か登録して、それに該当する文字列を自動で見つけだせば、ユーザーは正しいものを選ぶだけの簡単な指示ですませられる。既存データを構造データに変換する作業が、大幅に軽減できるわけだ。
文字列パターンの定義は、何種類も登録できるとともに、パターンごとに確度を設定する機能も重要だ。電話番号の文字列パターンなら、「ZZZZ-ZZZZ」よりは「0Z-ZZZZ-ZZZZ」のほうが、電話番号である確率が高い。さらに「電話番号:0Z-ZZZZ-ZZZZ」というパターンなら、電話番号にほぼまちがいない。より複雑なワイルドカードも使えるようにし、何種類かのパターンを確度とともに定義する。パターンと一致した文字列は、確度の高い順に表示することで、効率よく正しいデータを発見できる。
文字列パターンのワイルドカードとしては、数値の範囲を限定する機能も加える。たとえば、身長を見つけだすパターンとして「ZZZcm」を定義したとき、ZZZ部分の数値の範囲を限定できれば、まちがったデータを抽出する可能性が減る。また、数値の場合は、数値部分だけをデータとして取り出し、残りは単位などの属性に変換する機能も必要となる。
文字列パターンは、すべての項目で定義できる。たとえば「氏名」の項目なら、「氏名:XXX」のように項目名を見出しとするパターンがつくれるからだ。これをすべての項目に入力するのは無駄なので、この種のパターンを自動生成する機能を加える。
文字列パターンによる抽出機能は、項目が未定義のデータを先に入力するときも役立つ。KIOSM-2では、最初に項目を定義しないと、その項目としては入力できない。そこで、まず最初に文章テキストとしてデータを入力し、あとから項目を定義する。最後に文字列パターンで検索すれば、ほとんど自動で変換できる。先に入力するときに、前述のデフォルト作成パターンに適合させることだけが、唯一の注意点となる。
文字列パターンによる検索機能は、データベースを自動生成する機能の基礎ともなる。この機能は、いずれ紹介する予定だ。
知識ベースに入れる内容は、前回と今回で説明したものだけではない。各種説明図を描くときに役立つ、項目ごとのシンボルマークも重要な定義データの1つだ。入れる定義データの説明をこのまま続けてもキリがないので、このへんでいったん終了する。ほかの定義データに関しては、必要なときに説明する予定だ。
今回説明した内容の定義データを知識ベースに加えることで、システム全体の活用範囲は大きく広がる。特に重要なのが教育分野だ。一般の学校教育だけでなく、知らない分野の知識を得たいときに、強力な助っ人となる。
知識ベースに定義されている分野なら、学習の初期段階からコンピュータを利用できる。知識ベースの内容を読むだけでなく、実際に処理を動かして見れる。
このことは、本を読んで知識を得るのとは大きく異なる。また、既存システムのように、あらかじめ決められた教育ソフトを動かして、知識を習得するのとも異なる。データを入力したり、入力値を変化させたりして結果を見る行為は、試行錯誤しながらの学習になる。試行錯誤の重要な点は、より深く理解できるとともに、読むだけではわからなかった内容まで理解できることだ。結果として、理解の深さや範囲が増すことにつながる。さらには、AutoExpression機能によって、元データや処理結果をわかりやすく表示するため、理解しやすさはますます向上する。
それに加えて、新しく考えた処理を試してみたいなら、項目や処理を自分で定義し、値を入れて結果を見ることもできる。既存の処理を少し変えて、結果がどう変化するかも、容易に試せる。試行段階で知識ベースに定義した内容が確定したら、そのまま実際のデータに適用して、定義を使い続けられる点も魅力だ。
教育者は、教育する内容を知識ベースに定義し、最低限のサンプルデータを用意するだけですむ。1つの内容に関しては誰か1人が定義し、流通させればよい。基本的な分野の定義は、最初から揃っているので、それ以外の分野をつくることになる。
本連載ではまだ説明していないが、シミュレーション環境を実現する仕組みにも、新しい考え方を取り入れる。今回説明した試行錯誤が、より広い分野で活用できるはずだ。また、報告書などの文書作成に関しては、新しい支援機能をつける。伝えたいことを上手に説明するという部分を、強力に支援する機能だ。これまでにない、新しい文書作成環境を実現する。これらを加えることによって、教育システムとしての完成度は増すだろう。
今回までの内容は、かなり内部的な構造に焦点をあてて解説してきた。次回は、少し路線を変更して、本システムによってユーザーの環境がどのように変わるかを解説してみたい。
「知識ベースに定義されている分野なら、
学習の初期段階からコンピュータを利用できる」
内容理解や使い勝手の向上にも知識ベースは役に立つ |
