
思考支援:雑誌連載の内容:第25回 |
コンピュータを使った作業では、編集内容を保存したり、直前の操作を取り消す機能が必要だ。より自然に使えるシステムを目ざすなら、「自動保存」が基本となる。紙での作業の場合、消しゴムなどで消さないかぎり、制作したものは残る。今後の理想的なシステムにおいては、前の状態へ復帰する機能を充実させつつ、ユーザーがより安心して使える効率的なシステムを目ざす。
コンピュータを使い始めて覚えることの1つに、編集した内容を保存するという操作がある。これを忘れると、せっかく作成した内容もたちまち消えてしまう。自動的に保存をしてくれるソフトウェアとしては、データベースソフトのファイルメーカーProなどがあるが、こうしたソフトウェア以外を使う場合には、ユーザー側が意識して保存することを求められる。
コンピュータを使わない作業をする場合、紙に書かれた内容であれば、それを消さないかぎり残る。このことから、どちらかといえば、自動保存ソフトのほうが自然な作業に近いといえる。しかし、多くのソフトでは手動保存を採用している。この場合ファイルとしていったん保存してしまった内容は、取り消しができない。このため、作成結果を確認してから保存する必要がある。
編集中の内容については、操作の取り消し(Undo)機能を用いて、操作前の状態に戻せる。既存OSでは、各アプリケーションごとに取り消し機能が用意されている。ただ、たいていのソフトは直前に行った操作結果までしか戻せない。ワープロソフトのNisus Writerなど一部の高機能ソフトでは、何回か前の操作まで取り消すことができる。ただし、取り消した作業を順番に戻る方式なので、ある一部分の作業だけを取り消したいような場合には使いづらい。また、アプリケーションを終了すると戻せない、といった欠点もある。
ほとんどのソフトでは、ファイルとして保存した内容に対しては、取り消す手段を用意していない。これが不便だと感じられているためか、ごく一部のソフトでは、変更される1つ前のファイルを残す機能を提供している。だがこれも苦肉の策であり、使いやすくはない。途中経過を残したい人は、別名で保存しながらそれまでの履歴を残すことで対処している。このような仕組みなので、上書き保存すべきか、別名で保存すべきか、ユーザーが考えながら操作する環境になっている。この作業は、慣れると当たり前に感じるが、初心者だとどちらがいいのか最初は戸惑うだろうし、よい仕組みとはいえない。
「紙に書いた内容は、消しゴムなどで消さないかぎり必ず残る
これは、ソフトウェアでいえば自動保存の機能といえる」
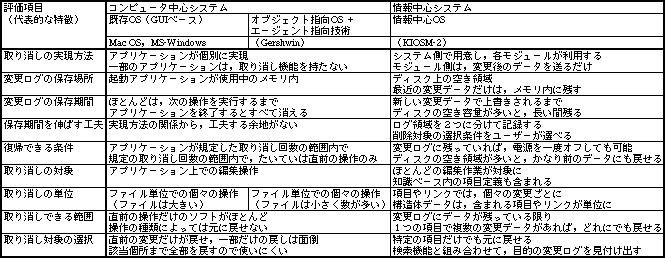
情報中心システムでは、取り消し機能をシステム側で用意する。既存の取り消し機能よりも強力で自由度が高いうえに(表1)、データを以前の状態へ復帰させることが中心となるので、「取り消し機能」ではなく「データ復帰機能」と呼ぶ。
表1、取り消し(データ復帰)機能を、OSごとに比較した結果。情報中心システムになると、データ復帰機能が格段に向上する
OSの進歩 =================>
ここでは、データ復帰機能が充実しているので、自動保存が基本となる。ただし、データを容易に変えられては困る。このため、データの入力や変更については専用のモードで操作する。前号でも述べたが、もちろんデータにチェック機能などをかけて、データの質を確保する支援機能も使う。作成するデータの多くは、項目と構造体データに加え、それらの間のリンクとなる。処理の流れ図などの作成データも、内部的には構造体データであり、項目とリンクで構成する。
内部的な動きを説明しよう。データ作成を担当する各モジュールが、変更したデータをシステム側に渡す。システム側では、前のデータを別な場所(データ復帰用に保管する場所)に移動し、変更後のデータを追加する。このような仕組みなので、各機能を担当するモジュールは、取り消し機能を持たない。テキスト編集のように何度も続けて操作する場合でも、そのつどシステム側にデータを渡す。既存OSのワープロソフトのように、1つの大きなファイルとしてはつくらず、短いテキストを組み合わせる説明内容の構造体データとしてつくるので、このような仕組みが可能なのだ。
個々の項目やリンクごとの変更を記録するので、ほとんどの変更操作に対してデータ復帰機能が使える。知識ベース内の項目定義も対象となる。自動生成する表示内容のオプション変更も、オプション設定だけを記録すればよいので、データ復帰の対象に加えられる。
データ復帰機能と同じくらい重要なのが、さまざまな操作によって発生する変更ログを記録しておく場所だ。既存の資源を有効に活用するというポリシーから、ハードディスクの空き領域を利用する(図1)。せっかく空いているのだから、使わないと損だ。ハードディスクなので電源を切っても変更ログは残るし、再び電源を入れたあとでも復帰できる機能も実現できるので、メリットは多々ある。古いログを上書きしながら使い、新しい分の変更ログをつねに残す。空き領域が広いほど、長い期間の変更内容を保存できるため、かなり古い時点のデータにも戻すことができる。
図1、ハードディスク内の空き領域を利用して、変更ログを記録する。極端に少なくなると困るので、最低限の容量を保障する

もし、実データが増えると、必然的に空き領域を使うことになり、変更ログを記憶しておくスペースのほうが減少する。それで、変更ログとして利用する最低容量を決めておき、容量をオーバーすると実データのほうを記録しないようにしておく機能も必要だ。もちろん、緊急事態が発生し絶対に保存したいデータがある場合だけは、変更ログの領域を利用する機能を残しておく。変更ログの最低容量を何%にするかは、システム側の環境設定として指定できたほうがよいだろう。既存システムでは「データをどのように表現するか」に関する部分が、作成データの多くを占めている。変更の多くは、元データなどではなく、どのように表現するかという部分だ。ここが、作業の量を増やしているうえに、取り消し機能を複雑にしている。
ところが情報中心システムでは、元データの入力や処理の流れの作成だけがおもな作業となる。元データだけをつくるので、ファイルに比べてデータ量はかなり少ない。加えて、表現部分の操作がないため、変更の量も圧倒的に少ない。これらの結果、同じ記憶容量でも多くの変更履歴を保存できる。
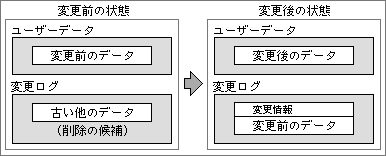
変更ログの内部構造は、データベースとなっている(図2)。元データの変更前の内容は、ユーザーのデータ記憶領域からログ領域へ移され、変更の種類を示す情報を加えて保存する。変更後の元データをデータ領域に登録し、新しい値として利用する。このような仕組みとなっているので、変更ログのデータは、いろいろなキーで検索できる。該当する変更データを素早く呼び出すためには、変更ログ全体をデータベース化するしかない。
図2、データを変更すると、変更後のデータをユーザーデータに追加し、変更前の値を変更ログに移動する。変更ログの中では、削除候補として用意していた古い他のデータを削除する
変更ログの領域を可能なかぎり有効に使うためにはどうしたらよいだろう。これには、記憶領域の区分けを利用する。ログ領域を一気に消費するときというのは、画像などの大きなデータを何度も変更したときだ。そのすべてを保存したのでは、ほかの多くの変更ログが古い順から消えてしまう。
この問題を解決するために、変更ログの領域を2つに分けて使用する(図3)。1つは、確定した変更を保存する領域で、メイン変更ログと呼ぶ。もう1つは、サブ変更ログと呼び、一時的な変更を記録する。
図3、ユーザーが呼び出して変更する場合、途中の変更内容はサブ変更ログに入れる。メイン変更ログに入るのは、閉じるときの最後の変更内容だけ
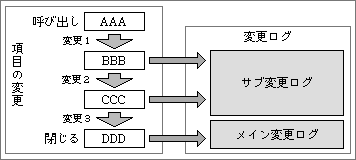
このような二分割構造のログを用いるのは、画像の編集作業などを想定してのことだ。ユーザーの気に入るまで変更を何度も繰り返すと、そのたびに変更ログに保存されてしまう。編集の途中段階まで戻したいのは、編集が終わるまでであって、終わったあとで戻すということはあまりないだろう。
そこで、編集中の変更ログを保存する部分(サブ変更ログ)と、編集終了時点での変更内容を保存する部分(メイン変更ログ)に分ける。編集が終わったかどうかは、編集するデータを閉じたかどうかで判断できるため、識別は簡単だ。
サブ変更ログの保存方法は、最も古いデータを消しながら上書きする方式をとる。続く別なデータでの編集中の変更が少なければ、前に閉じた変更内容も残っていて、運が良ければ、編集途中の内容へも戻せる。以上のように、二分割構造の変更ログは、限られたディスク領域を有効に活用するために役立つ。
既存システムを基準に考えてみると、扱うデータは段々と大きくなってしまうことが多い。加工前のデータをファイルとして保存し、さまざまなものを組み合わせた加工結果を、新しいファイルとしてつくり、さらに保存が行われるからだ。このように加工しながらのコピーが続くため、大きなファイルが増えてしまう。情報中心システムの時代になると、説明内容の構造体データとして作成するため、小さなデータの集まりとしてつくるように変わる。
また、画面表示が中心であり、印刷用に高解像度の画像を用いる必要がない。動画にしても、説明テキストや数値の表などと自由に組み合わせられ、必要な部分だけの短いムービーとしてつくる。長時間ムービーの形でつくるのは、古いシステムでは当たり前だが、ある時期から減少する。静止画像にしても、大きなものをスクロールしてみるのではなく、全体像や部分の小さな画像を何枚か組み合わせ、必要な画像を表示するという使い方に変わる。
「変更ログをメインとサブに二分割しておき、
効率のよい復帰力を持たせるのがポイント」
メイン変更ログの領域を、さらに有効活用する機能も組み込んでおく。古いものから単純に削除する方法ではなく、削除データをもっと賢く選ぶ方法を用意する。
ログ領域を有効活用するためには、大きなデータを早めに削除する方法が有効だ。小さなデータなら、同じ容量に数多くを記録できるので、復帰可能なデータ数を増やせる。データの大きさと変更時期をもとに計算する式を用意し、その数値で削除する対象を決める。データが大きくて古いほど計算値も大きくなり、削除対象として優先的に選ばれる。その結果として、小さなデータほど長く残り、復帰できるデータの数が増える。
計算式の作成では、新しいデータが毎日追加されても、計算し直さなくてすむことが大切だ。新しいデータほど低い値になるように、日付連番(日付の内部的な通し番号)に負数を乗算する形で式をつくる。たとえば、式を「データサイズ×重み係数A−日付連番×重み係数B」とすれば、日付が新しいほど値が小さくなる。これをデータベースのキーに加えることで、削除対象が簡単に選べるようになる。
計算式で重要なのは、重み付けの係数だ。データサイズと日付のバランスを、ユーザーの好みで調整できるようにしておく。小さいデータを長いあいだ残したいときは、データサイズの係数を大きくして、大きなデータを優先的に削除させる。このような調整は、あらかじめ用意された10段階程度のレベルから選ぶ方式のほうが使いやすい。
削除対象を決めるアルゴリズムは、独立した機能として用意する。新しいアルゴリズムを組み込めれば、ログ領域をさらに有効活用できる。将来の拡張に柔軟な構造も、今後のシステムでは大切だ。
「ログを最大限に活用するには、
独自の係数を適用できるようにしておく」
情報中心システムでは、データ復帰の操作方法も大きく変わってくる。まず、復帰したいデータや構造体を選び、変更履歴を表示させる(図4)。メインとサブの両方の変更ログから読み出すので、2つの切り替えを意識する必要はない。ログ内の個々の値と変更時期を比べながら、戻したい値を選ぶ。1つ前の変更だけでなく、かなり前の変更にも戻せる。既存システムのように、順番に後戻りするような仕組みではないのだ。
図4、変更履歴を表示する機能では、抽出条件を指定する。これは特定の人物データに関する変更を表示させた状態
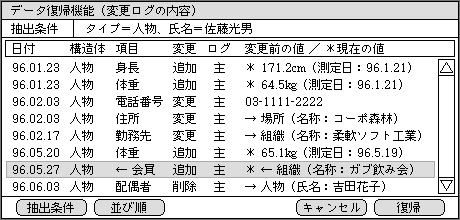
データ復帰機能では、検索機能も利用できる。抽出条件として人物データの住所を指定すれば、全員の住所項目に関する変更が現れる。最初は変更日付順だが、並び順は自由に変えられる。目的のデータが明確でないときは、かなり役立つ機能だ。
変更履歴には、値の変更だけでなく、リンクの変更も一緒に表示する。自分がリンクしている場合だけでなく、リンクされている情報も含める。値の変更が、リンク相手の変更と深く関係していることも考えられるので、より正確に把握しながら復帰させる必要がある。データの正しさを高く維持するためには、欠かせない機能だ。
データ復帰機能が充実すると、ユーザーは安心してコンピュータを使うようになる。もしまちがえても、容易に戻せるからだ。既存システムのように、別名の保存を繰り返したり、復帰できなくて、あきらめるようなことも非常に少なくてすむ。
自動保存は、より自然に使えることも大きい。その欠点を補うために、レベルの高い復帰機能を加え、全体としての使いやすさを向上させる。この組み合わせならば、紙に書くような自然さで使えるとともに、コンピュータが得意な復帰機能を幅広く利用できる。これからのシステムでは、自然さと便利さを両立させることも重要だ。情報中心システムのレベルになると、その環境を実現できる。
内容を変更前の状態に自由に戻せるデータ復帰機能 |
