
思考支援:雑誌連載の内容:第23回 |
コンピュータが進歩すると、データの正確さを高く保つことも、重要な問題として浮かび上がってくる。情報中心システムでは、さまざまなチェック機能があらかじめ組み込まれているので、データになんらかのまちがいがあれば、即座に発見してくれる。何度も計算し直したり、見直しをする必要が圧倒的に減る。また、知識ベースと連動する方法なので、簡単に使えてしまうし、データに対する質の高いチェックも可能だ。ユーザーの側がデータの質自体に気を配るようになるのもメリットである。
コンピュータのレベルが上がると、機能重視からデータ重視へと変化する。どのような加工処理ができるかだけでなく、データの質を高く保つための支援機能も求められる。その1つが、データのまちがいを発見してくれる機能で、データの正確さを保つために使用する。
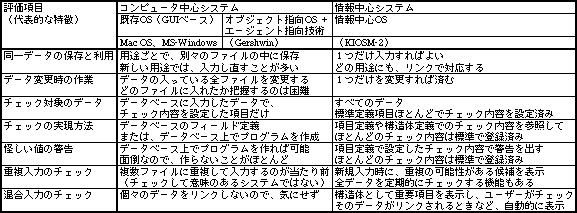
最も簡単なのは、データを入力するときの値をチェックする機能だ。既存OSでも、データベースのフィールド定義に設定する形で実現している。ところが、データベース以外のソフトでは、簡単なチェックさえできない。同じ数値データでも、ワープロ書類上の数値はもちろん、表計算ソフト上の数値もチェックできない。データベースに入れるのは一部のデータだけなので、ほとんどのデータに対しては、チェックがかからない。非常に限られた機能といえる(表1)。
表1、既存OSから情報中心システムまでで、まちがいデータの発見機能を比較した結果。情報中心システムにならないと、データの正確さを高めるための支援機能がつかない
OSの進歩 =================>
さらには、1つのデータが複数ファイルに重複して入力してあることも、大きな欠点になる。データの変更が生じたとき、すべてのファイルを一緒に書き換えるのは困難だ。実際には、どのファイルに入っているのかを把握することすらできない。結果として、データの正確さを確保するのは不可能に近い。
ところが情報中心システムでは、リンクによって1つのデータを幅広く共有する。データの変更時には1カ所だけ直せばよく、正確さを高く保ちやすい構造だ。
しかし、それだけでは満足できない。入力ミスを可能な限り防げぬよう、データ自体をチェックする機能に加え、さらに正確さが向上するようにする。もともとの基本構造がよいので、データのチェック機能も組み込みやすい。
まちがいデータには、大きく分けて2種類ある。1つは、項目の値が正しくないもので、数値データなら、「数字が1つ抜けた」とか、「桁をまちがえた」などが考えられる。もう1つは、「1つのデータを重複して複数入力してしまう」とか、「逆に2つのデータを1つのデータとして入力する」場合だ。特に重複して入力された場合は、情報中心システムの特徴であるリンクのメリットを生かせないので、発生をできるだけ抑える必要がある。
まず最初は、項目の値がまちがっているデータの発見だ。これは、入力時や更新時に入力値をチェックすることで実現する。
チェックすべき内容は、知識ベースの項目定義の中に入れる。後述するように、値の範囲や形式などを設定する。それを参照しながら、入力機能がまちがったデータを発見し、ユーザーに知らせてくれる。
項目定義内のチェック内容は、値の条件を2種類に分けて登録する(図1)。1つは絶対条件で、それを満たさないデータは入力できない。もう1つは通常条件で、それを満たしていないデータを入力した場合、値が正しいかどうかの確認を求める。この警告が出た場合、ユーザーはもとの値を確認して、そのまま確定するか入力し直すかを決める。
図1、データの入力条件を設定した項目定義の例。絶対条件と通常条件の2種類があり、それぞれに複数の条件を持てる
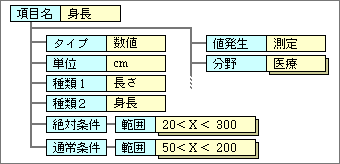
2種類の入力条件は、たとえば次のように使用する。人物データの身長の項目なら、絶対条件の範囲に20〜300cmを設定すると、これ以外の値は入力できない。加えて、通常条件の範囲を50〜200cmとすれば、この範囲外のデータには確認の警告を出す。身長の項目ならそれほどメリットはないが、金額の項目では、大きな額のときに確認を求める用途で役立つ。
チェックする内容は、値の範囲だけではない。小数点以下の最大桁数を規定できれば、測定データの入力ミスを防げる。通常の測定結果が0.1単位なら、小数点以下を0.1単位までに設定し、小数点以下が2桁以上の入力データで警告を出す。同様に、整数だけのデータとか、10単位で増減するデータもあるだろう。打ちまちがいを発見するのが目的だ。
テキストの項目では、最大の長さや文字の種類などを条件に設定する。名前の読みの項目ならカタカナだけを許すとか、名字の文字数が3文字を超えたら警告を出すとか、入力ミスの発見に役立てられる。
電話番号や郵便番号のように、決まった形式の値しか持たないデータもある。データの形式を規定する機能で、まちがいデータの入力を防止できる。これは、既存のデータベースでおなじみのものだ。
より汎用的なチェック内容を定義する方法として、簡単な式が使えると便利だ。たとえば、測定日や誕生日の項目なら、今日の日付よりも前でなければならない。こんな場合は、不等号を用いた式で指定する。表計算ソフトの式のように、多くの関数と組み合わせれば、かなりのチェック内容が定義できる。
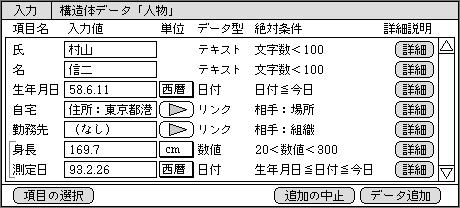
まちがいデータの入力機能では、絶対条件や通常条件を表示しながら入力できるようにする(図2)。入力前に書式や範囲がわかれば、元データのまちがいを事前に気づきやすい。
図2、入力画面の概略イメージ。項目の絶対条件を表示することも可能で、それを参照しながら入力できる
「単純な入力ミスやまちがったデータのインプットを
自動的に跳ねるシステムをあらかじめ組み込んでおこう」
複数の項目間で、値が大きく関係することもある。たとえば、電話番号と郵便番号と住所の場合、この3つ項目は密接に関係している。これらの整合性を調べれば、まちがいデータを発見できる。ただし、値の範囲指定のように、単純な機能では実現できない。
そこで、ソフトとデータを組み合わせたチェック機能を、自由に追加できるようにする。これを項目定義に設定しておき、両方にデータが入力された時点で、整合性をチェックする。さらにこの機能を発展させれば、片方のデータが入力されたあとで、残りのデータを入力する際に、候補を表示する仕組みも可能だ。データ入力の手間を軽減でき、一石二鳥となる。
ソフトとデータを追加する方式は、電話番号と住所のような項目には適しているが、ユーザーの側からは簡単につくれない。項目間の関係がもっと単純な場合には、式で表現できるので、関連を式として定義する機能も加える。式には不等号も使え、値の大小関係を記述するときに利用する。例を挙げると、同一人物の100m走と200m走のタイムは、200m走のほうが大きくなる。また、血圧の最大値と最小値では、最小値のほうが小さい。このような項目間の大小関係を記述できれば、入力時に警告を出して、入力ミスを知らせることが可能だ。このような関係を持つ項目はかなりあるので、エラーを発見できる可能性が増す。また、この機能で発見できるエラーは、値の範囲をチェックする方法では発見しにくい。それだけに価値のある機能といえる。
項目間のチェック機能も、絶対条件と通常条件のどちらにでも設定できることが大切だ。対象となる項目の特性に応じて、入力してはならない値と、警告を出す値を上手に使い分ける。
ここまで説明したチェック機能がいくら便利でも、チェック内容をユーザーが入力しなければならないようなら、ほとんど誰も使わないだろう。そこで、知識ベースに最初から入っている一般的な項目では、チェック内容をあらかじめ設定しておく。こうすれば、ユーザーは最初から項目チェックの機能を利用できる。また、システム供給者側が十分に検討してから設定するので、チェック内容がより適切になる。
「まちがいを排除するシステムを組んでも、
最終的にチェック内容を入力しなければならないなら、
誰も使わない」
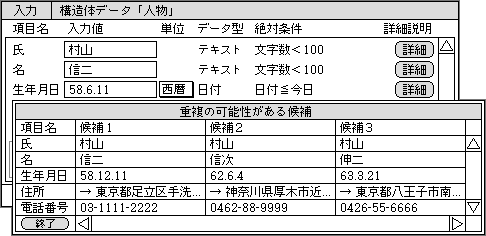
データの重複チェックは、入力時や変更時に自動的に実行させる。どんな構造体データでも、重要な項目が決まっている。たいていは名称の項目だ。この値が入力されたとき、同じ値を持つ構造体データが存在しないかどうか、全部のデータから検索する。見つかったデータを一覧表形式で表示し、同一のデータかどうかを確かめる(図3)。一覧表示に含む項目は、入力や更新で選んだ項目と合わせ、データを比較しやすくする。
図3、データの入力時には、重複の可能性があるデータを自動的に検索して、見つかれば一覧形式で表示する。1つのデータを重複して入力するミスを、防ぐための機能
同じデータがすでに存在するなら、入力する必要はない。ただし、必要な項目のすべてが揃っているとはかぎらない。不足する項目は、見つかった構造体データへ追加する形で、残りの項目を入力する。これが続くと、構造体データの項目数がだんだんと増え、より充実したデータへと成長する。
複数の元データを1データとして誤入力したケースは、エラーを自動的に発見するのが難しい。関連するデータを一緒に表示して、ユーザーに判断してもらう程度しかできない。こうした場合には、新しい項目を追加する項目の値を変更する、既存項目の値を変更する、リンクを張る、などのタイミングで、構造体データの全体像を表示する(図4)。ここでは一度に全項目を表示できないので、切り替えながら正しいデータかどうかを判断する。
図4、構造体データの値を総合的に見るための機能。リンク相手の主要な項目値も一緒に表示する
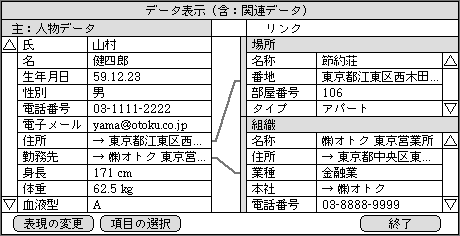
リンクを張る際に、リンク相手の重要項目が表示されれば、まちがったデータへリンクすることも防げる。リンク相手をまちがえるというミスは発見しにくいだけに、リンクの作成時や変更時には、正しい相手かどうかを確認できる仕組みが必要だ。代表的な項目の内容をまとめて表示できれば、最低限の確認機能として役立つ。
以上のような機能を備えても、まだ十分とはいえない。せっかく警告を出しても、調べる時間がないなどの理由で、そのまま入力してしまう可能性があるからだ。また、ユーザーが追加した項目定義の場合、値の有効範囲をあとで変更する可能性もある。変更前に入力した値に対しては、入力時に値をチェックする機能は無力だ。そこで、すでに入力ずみのデータを一括してチェックする仕組みも、別に用意する。ユーザーが入力した全部のデータに対して、前述のチェック内容をすべて調べる機能だ。全部のデータを対象に調べるので、データ量が多い場合には処理時間が長くなる。マシンの空き時間を利用して、バックグラウンドで実行させるのが、現実的だろう。それも、毎月1回行うなど、決められた周期で自動的に実行を開始し、調べ終わったら結果を報告する方法がよい。
結果報告の表示では、該当データを簡単に呼び出して修正する機能もつける。なお、チェックしたあとに修正された可能性もあるので、結果報告を表示する前に、該当データを再びチェックして表示する。この結果報告は、次の一括チェックまで残る。修正したデータは一覧から削除するので、すべて修正し終わった場合だけ、消えることになる。
ここまで説明したチェック機能は、既存OSやオブジェクト指向OSには不可能なものばかりだ。ファイル中心の仕組みである限り、データの細かなチェックは難しい。この類の欠点は、コンピュータ中心システムならではのものだ。
逆に情報中心システムでは、意味づけされた項目ごとに入力するため、値や関係の細かなチェックが可能となる。チェック内容を、知識ベースの項目定義に入れるため、すっきりとした構造で実現できる。基本構造の良さが、エラーチェックにも生きてきて、質の高いチェック機能を実現してくれる。これは、情報中心システムらしい機能の1つであり、「情報中心」の言葉にふさわしい機能といえる。
情報中心システム以降のコンピュータでは、データの質を重視するのが当たり前になる。その第一歩が、間違ったデータを発見する機能だ。ただし、機能をたんに組み込めばよいというものではない。ユーザーに余分な操作を強いることなく、自動的に各種のチェックが実行されることが重要だ。ユーザーに手間をかける方法だと、いずれチェックしなくなり、データの信頼性を高く保てない。チェック内容が増えても、自動的な実行だけは確保する必要がある。
情報中心システムに慣れてくると、データの正確さを高く保つ意識が芽生え、使い方も変わる。データの入力や変更の際に、対象以外の項目も一緒に見るようになる。自動的に検出できるまちがいは限られているので、このような意識の変化は意外に重要だ。また、ユーザーが独自に追加する項目定義にも、いろいろなチェック内容を設定して、まちがいを発見しやすい環境をつくる。さらに正確なデータを求めて、使い方を工夫するようになるだろう。
データの正しさを高く保つための機能は、システムのレベルが上がれば当然要求されるものだ。情報中心システムにならなければ、その第一歩すら実現できないのである。
「ファイル中心の仕組みでは、エラー訂正に限界がある。
個々に意味づけされた項目中心のシステムこそ、最も効率的」
データの正確さをより高めるための支援機能 |
