
思考支援:雑誌連載の内容:第12回 |
データベース機能は、情報中心システムの中でも重要なポイントだ。しかし、既存OSの中では情報整理がうまく機能していない。それはなぜなのか? 情報中心システムではどうあるべきなのか?
最もコンピュータらしい機能のひとつがデータベースだ。既存OSでは、全体の仕組みが悪いため、データベースが持つ本来の情報整理機能を生かしきれない。ところが情報中心システムでは、データベース機能を標準で組み込み、すべてのデータ整理に活用できる。また、データベースへの登録データを自動抽出する機能もあり、ユーザーが情報を整理するのを大きく助ける。データベース機能の位置づけと組み込み方法は、今後のシステムでの重要な部分といえる。
コンピュータが得意なのは、情報の整理だと一般には思われている。しかし、実際に整理を始めてみると、最初にイメージしたようには進まない。情報整理に最も有効なソフトはデータベースだが、ファイル管理や書類管理にはほとんど使えない。非常に限られた用途でしか、データベースは役に立たないのだ。結果として、多くの人は挫折してあきらめてしまう。
このような現実を見るかぎり、コンピュータは情報整理が得意だという認識は正しくない。とはいうものの、論理的には、情報整理こそコンピュータが得意な分野だ。それができない原因は、既存OSの仕組みの悪さにある。データベースも1つのアプリケーションであるため、ほかのアプリケーションとの連携は難しい。データベースに入れたデータを広く活用するためには、ほかのアプリケーションから直接アクセスできなければならない。
データベースに入れたデータもファイルであるため、ディスク全体のファイル管理には使えない。まさに根本的で構造的な問題なのだ。この欠点は、オブジェクト指向OSになって変わらない。少しだけ改善されるのは、データベース内のデータをほかの書類上に張り付けることが容易になる点だ。しかし、システム全体としてみれば小さな改善にすぎない。ファイルとアプリケーションが基本にあるかぎり、解決する見込みはない。
「情報整理こそコンピュータが得意な分野だ。
それができない原因は、既存OSの仕組みの悪さにある」
情報中心システムでは、データベース機能を標準装備している。まず、ユーザーが作成したデータを保存する入れ物自体が、大きなデータベースとなる。すべてのデータは、人物や組織といった意味としての構造体を構成している。その構造体名で呼び出せるのは、全体がデータベースだからだ。ここでいうところのデータベースは、個々のデータの属性(項目名や値の種類など)をキーとしたもので、検索方法やキーの種類は決められたものしか使えない。
これに加えて、ユーザーが自由に構築するタイプのデータベース機能もある。それは、中にある個々のデータへリンクを張り、それをまとめる形で作成する(図1)。このリンクをまとめた部分だけが、データベース用のデータとなる。データベース内に入れるデータというのは存在せず、通常のデータにリンクを張るだけですませる。この結果、データベースに登録したデータは、通常のデータとなんら変わらない。どんな処理にでも用いることができる。また、リンクを張るだけなので、1つのデータをいくつものデータベースに登録できる。
図1、情報中心システムでは、データベース用データと構造体データへのリンクで、データベース機能を実現する。使用するソートキーの数だけ、並び順データを持つ。リンクしたデータを変更すると、データベース用データも連動して自動更新する
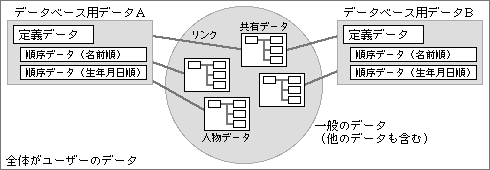
データベース用データは、簡単にいうなら、データベースの定義と、各キーごとの順序データで構成する。この順序データをもとに、順番に呼び出したり、一覧表でまとめたりする。
1つのデータを複数のデータベースに登録しても、元データが1つなので、それを修正するだけで全データベースで一緒にデータが書き換わる。データベース側はただリンクを張っているだけなので、更新後のデータを呼び出すだけでしかない。ただし、キーとなる項目が更新されると、順序データだけは書き換える。この書き換えはシステム内部で自動的に実行するので、ユーザーは元データを修正するだけですむのだ。
データベースには、カード型やリレーショナル型などいくつかの種類がある。このような違いは、データベースドライバとして持つ。データベース用データは、どれか1つのデータベースドライバのデータになる(図2)。だからデータベースを構築するときは、データベースの方式を最初に選ぶ。このような構造なので、データベースドライバを追加するだけで、いろいろなタイプのデータベースが使える。
図2、いろいろなタイプのデータベースは、データベースドライバとして組み込む。自動採番などの共通の機能は、各データベースドライバから呼び出す形で用意する。データベース用データは、該当するドライバによって生成&更新される。このデータは、ドライバごとに内容が異なる
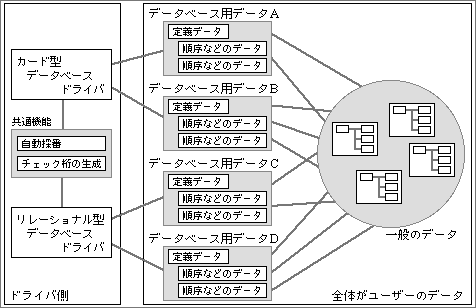
データベースドライバは、データを整理する機能しか持たない。データの表示や印刷はAutoExpression機能が担当し、ムービーなどの個々のデータの扱いはシステム側ですべて面倒を見るからだ。これで、データベースドライバの構造は簡単になり、開発も容易になる。
どのタイプのデータベースでも、最初にデータベースを定義するときに、データの種類を決める。日付や数値といった個々のフィールドのタイプではなく、人物や組織などの構造体名が対象だ。たとえば、住所録に入れるデータなら、人物データに限られる。同様にどんなデータベースでも、対象となるデータの構造体名を指定する。これは、次のようなメリットを生む。もし普通に新しい人物データを入力したとき、人物データが対象となるデータベースを列挙して、データベースに登録するかどうかを尋ねる。その場で選ぶと、入力した人物は、データベースにも登録される。つまり、ただデータを入力するだけでなく、できるだけデータベースへの登録して情報整理を促す機能が組み込まれているわけだ。これができるもの、個々のデータを細かく管理している仕組みがあるからだ。
データベースへ入れるデータは、データベースを定義する前に入力してある可能性が高い。ある程度までデータが増えた時点で、データベース機能を用いて整理しようと考え始めるからだ。
そのため、既存のデータをデータベースへ取り込む(リンクを張る)機能も必要になる。ここでも、人物などの構造体名が役立つ。データベースを定義した時点で、対象となる構造体名が決まる。そのままユーザーのデータ全体を検索して、登録データの候補を拾い出す。それを一覧表形式で表示し、ユーザーはその中から選ぶだけの操作ですませる。データベースへの登録も簡単だ。
データの中には外部から受け取るものもあり、それは構造体データになっておらず、テキストデータのことが多い。昔の紙の資料をOCRで入力した場合も長いテキストデータになる。このようなデータからでもデータベースへ登録できる機能があれば、かなり便利だ。
本連載の第6回で説明したように、知識ベースには項目データごとに文字パターンの定義も含んでいる。これを利用すると、長いテキストの中から、特定の項目を抜き出すことも可能だ。テキストから抜き出したデータは、構造体データに変換して、データベースへの登録候補になる。
文字パターンで抜き出したデータは、正しいデータのことも、まちがったデータのこともある。それを判断するためには、もとのテキストデータを表示して確かめるのが一番だ。そこで候補一覧から選択する画面では、もとのテキストを一緒に表示しながら作業を進める(図3)。
図3、自動抽出機能で得られたデータベースの候補データは、抽出元がテキストの場合は、元データを一緒に表示して正しいかを判断する
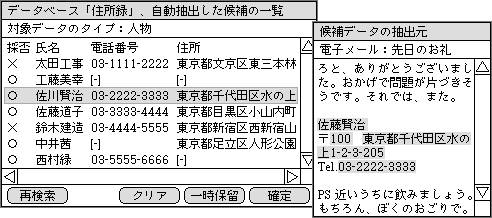
構造体データは複数の項目も含む。人物データなら、氏名や住所などだ。このようなデータを自動的に選ぶ場合、個々の項目は正しく抽出できたとしても、関係のある1セット分(人物なら1人分)を正しくグループ化するのは難しい。近くにあるとか線で区切られているなどを参考にしながら、1セット分を集める。それが正しいか判断するのは、もとのテキストをユーザーが見たときだ。もしまちがっていた場合の訂正作業を軽減するために、もとのテキストの表示では、前後を広く加える。自動的に選んだ項目のうち、まちがっているものは、表示した元テキストの任意の部分を選んで置き換える機能もサポートする。これによって、正しくない自動抽出データの訂正も容易になる。
全体を通して、ユーザーが行うのは選択だけに限られるため、最初から入力するのに比べて、作業負荷は格段に少ない。これは非常に重要なことだ。データベースに関する作業のうち、最も大変なのは入力である。これが大きく軽減されるので、データベースの利用はとてもラクになる。
これだけ自動化が進んだデータベース機能だと、仕上げとして、データベース化したいデータの候補を知らせる機能も加えよう。
仕組みは非常に簡単だ。ユーザーのデータ全体で、どのような種類のデータが多いのか数え、件数の多い構造体データを見つけだす。このとき、どれかのデータベースへ登録したデータは数えない。もし人物データが多いなら、人物データが対象となるデータベースを構築したほうがよいと知らせるのだ。住所録にするか会員名簿にするかは、ユーザーに決めさせる。
もっと親切にするなら、知識ベースの中に、考えられるデータベースの候補を入れておけばよい。人物データから考えられるデータベースの情報は、人物の構造体定義に入れる。各データベースごとに、キーにすべき項目を選んでおくと、もっと親切だ。そこまで情報があると、データベースを定義するときにユーザーが指定する部分は、ほとんどなくなる。あとは、知識ベース内のデータベース情報と項目定義をもとに、データベースを自動生成するだけだ。そして最後に、ユーザーが候補から採用データだけを選ぶ。
これだけの機能を提供すると、データベースを面倒だとも思わないし、データベースを使っていることすら意識しないかもしれない。
ここまで述べたように、情報中心システムにおけるデータベース機能は、いろいろな特徴を持っている(表1)。データベースの自動生成は、誰もがデータベースを使う基礎となる。既存OSで同じようなことを実現しようと思っても、ファイルというデータの区切りが邪魔して不可能だ。テキストから自動生成する機能だけは可能だが、テキストファイルとして保存したものだけが対象となる。情報中心システムのように、ハードディスク上の全データから自動生成するのは無理だ。
表1、各OSごとのデータベース機能の比較。アプリケーションとして実現しているかぎり、データベース本来の情報整理能力は生かせない
OSの進歩 =================>
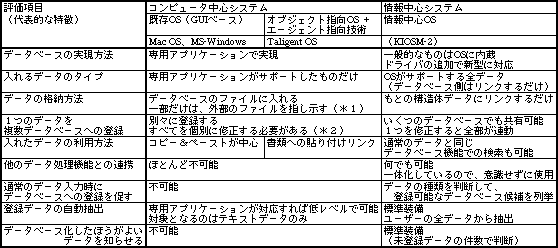
(*1)外部ファイルを移動するとリンクが切れる欠点を持つ
(*2)すべての登録先を覚えていればの話。実際には修正忘れが発生しやすい
既存OSやオブジェクト指向OSでは、ファイルがベースとなるため、データベースに入れたデータは、他のアプリケーションで利用しづらい。これもデータベースを使わない大きな理由だ。ところが情報中心システムでは、データベースに入れたデータは、通常のデータと同じように扱えるので、データベースの使用に伴う欠点はない。
同じデータを複数のデータベースに入れられるので、データベースをいくつ構築しても安心だ。次のような使い方も考えられる。まず最初はカード型のデータベースをつくる。それに慣れたら、同じデータをもとに、リレーショナル型のデータベースをつくる。これは、まったく同じデータを、2つのデータベースが共有している状態である。リレーショナル型を使ってみて、自分に合いそうなら、それを使い続ければよい。もし合わないならカード型を使う。気に入らないほうを削除することも、両方を残しておくこともできる。新しいデータを入力するときは、両方のデータベースを選ぶ手間が余分にかかる。
このような利用方法によって、いろいろなタイプのデータベースを試用できる。どれが自分に合うのか、実際のデータで試したうえで判断する。これも非常に大切なことだ。
コンピュータにとって、データベース機能は情報整理の基礎となる。それは、できるだけ意識せずに使えることが望ましい。残念ながら、既存のデータベースはいろいろな制限が多いので、使用できる範囲も狭く、使うのも簡単ではない。これでは、一般ユーザーが気軽に情報を整理するのは無理だ。情報中心システムでは、より自然で簡単に情報を整理する機能を提供し、日ごろからデータを整理する環境を実現する。
「コンピュータにとって、
データベース機能は情報整理の基礎となる。
それは、できるだけ意識せずに使えることが望ましい」
高度なデータベース機能で効率的な情報整理を実現 |
