
8008のパッケージ違い。上ふたつはセラミックパッケージですがピンの取り付け方など少し違います。多分、左の方が少し古いのではないかと思います。下はCERDIPです。右側は左のパッケージと同じ種類ですがパッケージを分解してチップをむき出しにしたもの。それなりの顕微鏡があればパターンを眺めることができます。
4004を基にした次世代のプロセッサというと、8008となります。世界初の8 bitマイクロプロセッサですね。Intelによりますと、1972年4月1日発表、10 um幅p-MOSプロセスで約3500個のトランジスタを集積となっています。標準品ではクロック周波数500 kHzで8 bitの加減算命令の実行時間は20 usでした。後に800 kHzクロックで動作する8008-1という型番の高速バージョンが発表されています。8008は4004の成功を受けて開発されたのではありません。4004の開発途中で、8008の開発プロジェクトが立ち上がっています。その際に4004の設計者を引き抜いて8008の開発にあたらせました。このため、4004の次世代のプロセッサというより、4004と同世代の姉妹品という設計になっています。設計者が共通な上、4004が顧客にどのように評価されるかわからない状態で別の顧客から依頼があったデータ端末用LSIとして開発が始まったため、確かに4004と似ているところが多くあります。
そのひとつが、下の写真からわかるようにパッケージに現れています。
8008のパッケージ違い。上ふたつはセラミックパッケージですがピンの取り付け方など少し違います。多分、左の方が少し古いのではないかと思います。下はCERDIPです。右側は左のパッケージと同じ種類ですがパッケージを分解してチップをむき出しにしたもの。それなりの顕微鏡があればパターンを眺めることができます。

Siemens社の高速版8008であるSAB8008-1Cと、旧東ドイツVEB Kombinat Robotron社の8008互換チップのU808D。
デジタルカメラで開封したチップを接写してみました。

普通の撮影法で、メタル層のパターンしか見えませんので、Intel社の公開しているダイ写真とは異なったものになります。下には8008の文字が見えますね。左側にはIntel社のコピーライト表示が潰れてしまっています。メタル配線が白く光っているだけなので、左下のボンディングパッドなどはどこにも接続されていないように見えますが、実際はきちんと接続されています。
4004が16ピンだったのに対し、8008は18ピンのパッケージとなっています。4004と同じく、当時の標準的パッケージに納めてコストダウンを狙っています。18ピンが標準的かと疑問に思われるかもしれません。当時の代表的なICファミリであるTTLファミリでは、14ピンと16ピンのパッケージが標準でしたし、この頃から成長を始めた汎用CMOSロジックICファミリも同じですから。しかし、当時のIntel社の主力製品である1103ダイナミックメモリは18ピンパッケージを使用していました。従って、8008が18ピンパッケージを採用することで、製造ラインへの追加投資を最小限にできたと思われます。
これがピン割り当てです。
Vdd 1 18 INT D7 2 17 READY D6 3 16 CLK1 D5 4 15 CLK2 D4 5 14 SYNC D3 6 13 S0 D2 7 12 S1 D1 8 11 S2 D0 9 10 Vcc
アドレス空間は16 KByteで、14本のアドレスラインが必要なはずですが、18ピン。やはり4004のときと同じように、8本のバスを時分割してアドレス下位、アドレス上位、命令やデータの転送と、順番に行っています。このほか命令の実行ステートが必要で、内部レジスタの加減算の場合には10クロックが消費されます。従って、500 kHzクロックでの加減算命令実行時間は最短で20 usとなるわけです。なお、ジャンプ命令などの場合では22クロック必要な命令があります。そういった命令は3 Byte命令になっているのですが、3 Byteを順番に読み込むたびにアドレス下位、アドレス上位、命令読み込みというシーケンスを繰り返すので、結局22クロックが必要となるのです。標準的な小さなパッケージに押し込んだためですね。
S0 - S2はステータス情報で、これとCLK1, CLK2, SYNCのタイミングを組み合わせて、CPUが何をしたいのか外部回路で決定してやらなくてはなりません。たとえば、アドレス上位をD0 - D7に出しているから外部アドレスラッチに記録しろとか、先に出したアドレスはメモリアクセス用で今D0 - D7に出しているデータをそこに書き込めとか、すべて外部回路でタイミングを作ってやらなくてはなりません。はい。集積度の低いTTL ICでそういう回路を作るのは大変で、10個や20個では足りません。メモリも集積度が低かった上に入出力用LSIもありませんでしたから、それらしいコンピュータを作るにはメモリとその周辺回路まで合わせて60個から100個のICを組み合わせることになります。ただ、それでも8008を使わないよりずっと楽というわけです。
READYは遅いメモリとのタイミング合わせに使う信号で、INTが割り込み要求です。INTを8008が検出すると、8080と同様に割り込み応答サイクルで1命令を読み込んでそれを実行します。そこでRST命令やCALL命令を読み込ませれば、割り込みサービスルーチンを呼び出すことができるという仕組みになっています。割り込み応答サイクルもステータス情報などの解読によって検出でき、どのタイミングでRST命令をバスに与えればよいかも、外部回路で作成してやらなくてはなりません。
なおVccは+5 VでVddは-9 Vにして使います。ピン配置からわかるように、GNDピンがないことに気をつけてください。8008はp-MOSプロセスで製造されたICであり、p-MOS ICをTTLと接続するときの定石として、本来のGNDピンを+5 VにしてシフトすることによってTTLとインターフェースしています。そのようにして使えば、入力スレッショルドレベルは1 - 2 V付近になるし出力のHレベルは3 V程度になるので、TTLレベルに一致します。ただ、出力のLレベルは-1 V以下になる場合があるので(インピーダンスが高いのでクランプダイオードで0 Vにクランプしても構わない)、TTLだとしてもクランプダイオードを内蔵していない入力やラッチアップ耐量の小さなMOS入力を接続すると、破壊する可能性があります。
4004は最高クロック周波数750 kHzで動作し1命令最短10.8 usで動作するのに対し、8008は500 kHzクロックが最大で20 usの命令サイクルになっているため、一見性能が低くなっているように思われます。しかし、8 bit単位の演算が可能なため、5 - 8 bit単位で表現される文字データ処理では4004より有利になります。たとえば4004ではROM上の表を引いて文字コードの変換を行おうとしたら相当の時間と命令列が必要になります。4004は電卓などの他、ビット単位で入出力制御を行う、たとえば信号機のコントロールのような組み込みに使われましたが、8008はもう少し複雑なデータ処理に使われるようになります。
レジスタ構成は、やはり4004と似ていて、こんなです。
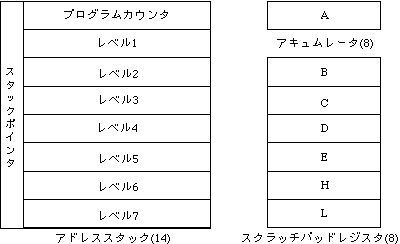
4004では4 bit幅で16個のスクラッチパッドレジスタがありましたが、8008では8 bit幅で6個、記憶容量的にはほぼ同一というか、少し減っています。その分、アドレススタック部分の容量が増えていますけど。
あと、HレジスタとLレジスタをペアにした16 bitのHLレジスタの内容をメモリアドレスとして解釈して、そのHLレジスタの指すメモリを命令で参照することができます。つまりHLレジスタの間接参照(HL)を、Mレジスタという仮想レジスタへの参照のように扱える命令体系になっています。レジスタセットは、意外なほど8080と似ていると思いますが、BC, DE, HLとペアにしていないのは、ペアで扱う命令がMレジスタ参照以外に存在しないからです。16 bitのレジスタ対に対するロードや加減算、インクリメントといった操作もできません。ですから、Mレジスタが使えたとしても、256 Byte境界をまたぐようなメモリ操作はたいへんに面倒です。ところで8008は知らなくても、8080やZ80をご存じの方は多いでしょう。8080やZ80で使われていたレジスタの名前の付け方は、この8008をなぞっていたことがわかります。
命令セット
命令表を以下に示します。読み方については表の後にある注釈を参照。一応、これだけわかればアセンブラを作成したり、アセンブリ言語でプログラムを書ける程度には整備したつもりですが。なお、アセンブラ表記のオペランドの項にimmとある命令は2 Byte命令で、addrが含まれる命令は3 Byte命令になります。それ以外の命令はすべて1 Byte命令です。
命令コード アセンブラ表記 clock 意味 11 ddd sss MOV rm, r 10/14 move 11 ddd 111 MOV r, M 16 move from M register 00 ddd 110 MVI rm, imm 16/18 move immediate 00 ddd 000 INR rx 10 increment register 00 ddd 001 DCR rx 10 decrement register 10 000 sss ADD rm 10/16 add 10 001 sss ADC rm 10/16 add with carry 10 010 sss SUB rm 10/16 subtract 10 011 sss SBB rm 10/16 subtract with carry (borrow) 10 100 sss ANA rm 10/16 and 10 101 sss XRA rm 10/16 exclusive or 10 110 sss ORA rm 10/16 or 10 111 sss CMP rm 10/16 compare 00 000 100 ADI imm 16 add immediate 00 001 100 ACI imm 16 add immediate with carry 00 010 100 SUI imm 16 subtract immediate 00 011 100 SBI imm 16 subtract immediate with carry 00 100 100 ANI imm 16 and immediate 00 101 100 XRI imm 16 exclusive or immediate 00 110 100 ORI imm 16 or immedeate 00 111 100 CPI imm 16 compare immediate 01 xxx 100 JMP addr 22 jump 01 000 000 JNC addr 18/22 jump if carry reset 01 001 000 JNZ addr 18/22 jump if not zero 01 010 000 JP addr 18/22 jump if plus 01 011 000 JPO addr 18/22 jump if parity odd 01 100 000 JC addr 18/22 jump if carry set 01 101 000 JZ addr 18/22 jump if zero 01 110 000 JM addr 18/22 jump if minus 01 111 000 JPE addr 18/22 jump if parity even 01 xxx 110 CALL addr 22 call subroutine 01 000 010 CNC addr 18/22 call subroutine if carry reset 01 001 010 CNZ addr 18/22 call subroutine if not zero 01 010 010 CP addr 18/22 call subroutine if plus 01 011 010 CPO addr 18/22 call subroutine if parity odd 01 100 010 CC addr 18/22 call subroutine if carry set 01 101 010 CZ addr 18/22 call subroutine if zero 01 110 010 CM addr 18/22 call subroutine if minus 01 111 010 CPE addr 18/22 call subroutine if parity even 00 vvv 101 RST vec 10 restart (1 Byte subroutine call inst.) 01 00m mm1 IN inport 16 input A from I/O port 01 rrm mm1 OUT outport 12 output A to I/O port 00 000 00x HLT 8 stop and wait for interrupt 11 111 111 HLT 00 000 010 RLC 10 rotate left 00 001 010 RRC 10 rotate right 00 010 010 RAL 10 rotate left through carry 00 011 010 RAR 10 rotate right through carry 00 xxx 111 RET 10 return from subroutine 00 000 011 RNC 6/10 return from subroutine if carry reset 00 001 011 RNZ 6/10 return from subroutine if not zero 00 010 011 RP 6/10 return from subroutine if plus 00 011 011 RPO 6/10 return from subroutine if parity odd 00 100 011 RC 6/10 return from subroutine if carry set 00 101 011 RZ 6/10 return from subroutine if zero 00 110 011 RM 6/10 return from subroutine if minus 00 111 011 RPE 6/10 return from subroutine if parity even
注:命令コードでxとあるビットは0/1のどちらでもかまわない。dddはディスティネーションレジスタを示す数値、sssはソースレジスタを示す数値。vvvはリスタートベクトルを表す数値(0から7だが、アセンブリ言語表記では0, 8, 10H, 18H, 20H, 28H, 30H, 38Hのように呼び出しアドレスでvecを表記するものもある)。mmmはI/Oポートアドレスを示す数値だが、OUT命令についてはさらにrrに1, 2, 3のいずれかの値をあてはめてアドレスを拡張できる(rrを0にすることはできない)。
clockは命令実行に必要なクロック数。ただし、オペランドにrmと指定のあるものはc1/c2と表記されていて、実際にrが指定されたときにc1クロック、Mが指定されたときにはc2クロックが消費される。同じく条件命令の場合、条件が成立しなかったときにc1クロック、成立したときにc2クロックが消費される。
アセンブリ言語表記のオペランド部で、小文字で書かれているものについて注釈を示す。rはA, B, C, D, E, H, Lのいずれか、rmはA, B, C, D, E, H, L, Mのいずれか、rxはB, C, D, E, H, Lのいずれかを示す。immは8 bit定数で、addrは14 bitの絶対アドレスを表す数値(メモリ上では上位2 bitに0を詰めた16 bit幅で格納する)。vec, inport, outportについては先に触れたとおり。
レジスタ名と命令コード上でレジスタを表す数値との対応は次の表の通り。
レジスタ名 ddd/sss r rm rx
A 000 * *
B 001 * * *
C 010 * * *
D 011 * * *
E 100 * * *
H 101 * * *
L 110 * * *
M 111 *
また、そのレジスタがr, rm, rxに含まれる場合は各欄に*を書き込んでおいた。無印のレジスタ(例:rの場合のMレジスタ)は、そのアセンブリ言語表記でオペランドに使用するとエラーになる。
命令ニーモニックとビットパターンとの関係がわかったので、アセンブラも逆アセンブラも書けますね。フラグ類の変化は8080と同じく演算系の命令でのみ変化し、MOV命令では変化しないことを考えれば(ついでに条件命令からわかるようにCarry, Sign, Zero, Parityが存在することも考えて)、シミュレータも作成できるでしょう。クロックサイクル数も掲載しておいたので、実時間でどれくらいの実行時間が必要になるかも計算できますね。以前、私が8008のシミュレータをC言語で書いて、クロック周波数20 MHzの386マシンで実行したとき、すでに実物よりもシミュレータの方が倍くらい高速だった記憶があります。シミュレータはどちらかというとデバッグ用で、命令実行クロック数の計算とかシミュレータのメインループでトレースモードチェックが毎回入るとか、高速化に特に配慮しない方式だったのに、実物より速くて脱力しました。さすがにパリティ判定は表引きを行っていましたが。
どのくらい遅かったか、メモリコピーのルーチンで検証してみましょう。BCレジスタペアの示すアドレスからDEレジスタペアの示すメモリへと、Aレジスタで指定したバイト数(1 - 256)だけコピーするプログラムを以下に示します。Aに0が入っている場合は256 Byteのコピーが行われます。コピー元とコピー先は256 Byte境界をまたいでいるかもしれないと仮定します。
10 MEMCPY: MOV H, B 10 MOV L, C ; BCレジスタ対をHLレジスタ対へ 16 MOV B, M ; 転送データをBへ 10 INR L ; 転送元アドレスのインクリメント 18/22 JNZ MC1 10 INR H 10 MC1: MOV C, L ; BCレジスタ対へHLを戻して 10 MOV L, E ; HLにDEレジスタ対をコピーするのだけど、 10 MOV E, B ; Bに転送すべきデータが入っているので、 10 MOV B, H ; それを先にLに内容をコピーして不要になった 10 MOV H, D ; Eレジスタに転送したりして、わかりにくいや 14 MOV M, E ; コピー先に書き込み 10 INR L ; 転送先アドレスのインクリメント 18/22 JNZ MC2 10 INR H 10 MC2: MOV D, H 10 MOV E, L 16 SUI 1 ; 転送終了判定(DCR Aは使えない) 18/22 JNZ MEMCPY 10 RET
メモリ参照をできるだけ減らして内部レジスタの操作だけで済ませるようにしたため、少々わかりにくくなってしまいましたが、こんな感じになります。左端がクロック数で、結局、ループの最短サイクルは256 Byte境界を転送元も転送先もまたがなかった場合なので、222クロック必要なことがわかります。1 Byteのコピーだけで400 us以上必要で、100 Byteのコピーをしたら44 msもかかってしまいます。現代のマイクロプロセッサより1万倍くらい遅いことがわかるでしょうか。たとえば、80文字×25行のCRT文字端末の表示をソフトウェアでスクロールアップさせると、約2000 Byteのコピーが必要になるので、1秒くらい必要になる計算です(実際には256 Byteよりも多い転送をいっぺんに行おうとすると、カウンタを内部レジスタに保持できないので、メモリ操作がさらに必要となって、ぐんと遅くなってしまう)。
なお、同様のメモリ転送プログラムを8080で作成すると、このようになります。
7 MEMCPY: MOV A, M 7 STAX DE 5 INX H 5 INX D 5 DCX B 5 MOV A, B ; DCXではフラグが変化しないのでBCが0かテスト 4 ORA C 10 JNZ MEMCPY 10 RET
ただし、転送元アドレスがHLレジスタペアに、転送先アドレスがDEレジスタペアに、転送バイト数がBCレジスタペアに入っているものとします。また、このルーチンでは256 Byte以上の転送も可能になっています。ループ1回に必要なクロック数は48クロックで、8080が2 MHzクロックで動作することを考えると、24 usで1 Byteの転送です。つまり、このようなプログラムでは8008から8080にプログラムを移植することで、20倍くらいの高速化が可能です。これなら50 msで2000文字のソフトウェアスクロールが可能ですから、1秒間に20行のスクロールができる実用的な文字端末を作成可能ですね。
なお、8008のソースコードをそのまま8080のアセンブラでアセンブルして実行することも可能で、その場合はループ1回の時間が53 usになります。つまり、それだけでも約10倍の高速化ですから、相当の改善であることは確かです。とはいえ、8008のコードが27 Byteで8080で書き直したコードが11 Byteと、メモリ効率もずっと良くなっていますし(8080が出た頃は1 Byteのメモリ単価が100円くらいしたことを考えると、16 Byteの節約だけでも1600円のコストダウン)、プログラムも理解しやすくメンテナンス性が高まっていますから、やはり8008は原始的すぎるマイクロプロセッサであったことがおわかりになるでしょう。これがさらにメモリブロック転送専用の命令を持つZ80 CPUや8086なんかでどうなるか考えてみるのも、初期のマイクロプロセッサの性能把握に役立つかもしれません。
命令表やプログラム例から、ニーモニックの意味は8080Aのアセンブリ言語と同一で、ソースコードレベルで8080Aのアセンブリ言語が上位互換の立場にあることがわかると思います。ただし、INR AとかDCR Mができないとか、DADやLXIやらINXなどができないことはまだしも、プログラム例には出てきませんでしたがSTA/LDAやらSHLD/LHLDができないのは面倒かもしれませんね。特定のアドレスのメモリにレジスタの内容を格納するには、そのアドレスを必ずHLレジスタペアに(8 bitずつ別々に)ロードしてからMOV M, rという命令を実行しなくてはなりません。8080ではさらにスタック操作命令が増えていることを考えると、プロセッサのクロックサイクル高速化以上に命令セットの高機能化のほうが8008から8080への性能向上に役立っていたといえるのではないでしょうか。プログラム例からわかるように、ずっと短いプログラムでアルゴリズムを表現できるようになっているのですから。
この命令の機能制限で、とんでもないところに悪影響があります。アキュムレータも含めたレジスタ類をダイレクトアドレッシングでメモリに書き込むことも、スタックにプッシュすることもできないわけですから、割り込みが可能だといっても、割り込みサービスルーチンで安全にレジスタをすべて退避することができません。これは一部レジスタを割り込みサービスルーチン用に最初から予約してメインプログラムでは未使用にしておくか、I/Oポートの一部をメモリのように読み書きできるようにしておいて、A, H, Lレジスタを出力ポートに退避しておいてから他のレジスタをM経由でメモリ上に退避し、その後で割り込みサービスを行って、逆の操作でメモリや入力ポートからレジスタの内容を復元すれば、解決できます。ところが実はそれでは足りません。おそろしいことにフラグ類を退避することも困難です。つまり、メインプログラムで演算命令と条件分岐命令の間に割り込みが入ってしまうと、割り込みサービスルーチンの中で演算を行ったが最後、正常に復帰できない可能性があります。これでは、入力に関する割り込みサービスルーチンの中で入力データをリングバッファに納めるような操作もできないわけで、カタログスペックでは割り込み可能となっていても、いったいどうやって利用したらよいのか、困惑してしまうような代物ですね。割り込みマスクもできませんし。唯一の有効な利用法というのは、割り込みサービスルーチンを使用しないフラグ待ちのような場面で、HLT命令でプログラムを停止させておいて、入出力要求などのパルス信号で割り込みを発生させ、NOP命令を割り込ませるというものです。こうすれば、フラグ待ちのループが1周で100 us以上必要となって要求発生から応答するまで最悪140 us以上も必要なのに比べて、約20 usでフラグ検出後の作業を始められます。場合によったらINやOUT命令を割り込ませてもよいかもしれません。そうすれば入出力要求信号から最短時間で入出力を行えます。しかも、割り込みサービスルーチンでなく、メインプログラム内での単なる時間待ちですから、レジスタやフラグ退避の問題もありません。
いやー、しかし、こういうものを割り込みと表現して、期待させるかなぁ。だって、READY信号に細工して、IN/OUT命令のポート入出力のタイミングでずっと待たせておいても同じ意味のことができる上、下手するとこちらの方が回路的にも簡単で、要求信号から入出力の時間も短時間で済んでしまうのですから。8080になるまでは、まともな割り込みサービスルーチンを実現できなかったということはおわかりになったでしょうか。さすがに4040では裏レジスタを用意して、まともな割り込みサービスルーチンを書きやすくなっていますけど。なんか、8008はアーキテクチャ設計というものをきちんと考えていなかったような気がしてきませんか。たぶん、そうなんだろうと私は思いますけどね。
{註: 上記の割り込みの記述など多岐に渡って「8008ファン」様よりコメントが寄せられていますので、ご覧ください。さらに詳細については、そのコメントの中で触れられている8008ファン様の8008専用Webページを参照するとよろしいかと思います。}
Returnto IC Collection