
思考支援:雑誌連載の内容:第20回 |
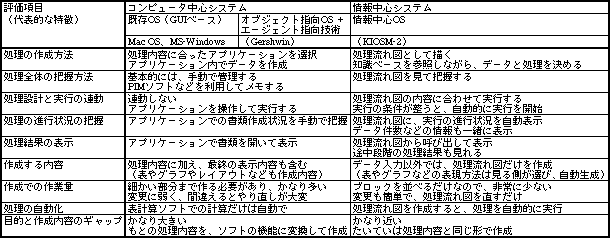
既存システムでは、一連の作業を把握する仕組みが組み込まれていない。そのため、ユーザーはPIMソフトなどを使ったり、あるいは紙にメモするなどの方法で管理している。だが、こんなやり方は手間もかかるし、効率も悪い。一方、情報中心システムでは、処理の作成と把握が 一体化しているばかりか、実行までもが連動できてしまう。ユーザーが行いたい本来の目的に近い形で処理を作成するため、使いやすさのほうも格段に向上する。
これまで3回にわたって、「説明技術を基礎にした説明内容の作成支援機能」について述べた。この中で触れてこなかったことに、データの加工処理がある。実験やアンケートの結果の集計をどうつくるのか、複数の写真画像を合成するなど、データの加工が必要な場合というのはかなりある。この作業をどのように支援するかも、コンピュータにとっては重要な機能だ。
データ加工という面で忘れられていることのひとつに、処理全体の把握がある。たとえば、アンケート結果の集計なら、どんな処理や手順でデータを加工し、どんな内容の表やグラフをつくるか、といったことだ。これもコンピュータを用いて把握できたほうがよい。既存OSには、その部分をサポートする機能がない。もしコンピュータ上で管理するなら、今のところPIMソフトなどを使ってメモするなど、ユーザーが手動で情報を残すしかない。また、既存OSではアプリケーションという仕組みのために、細かな処理ごとにアプリケーションを選択する必要もある。アプリケーション間の連携は貧弱で、中間ファイルの保存形式も併せて考えなければならない。今後登場するオブジェクト指向OSでは、アプリケーションの連携が容易になるものの、処理の把握に関しては手動のままだ。オブジェクト指向OSになっても、この部分は手つかずの可能性が高い。というのは、ファイルやアプリケーションという枠組みが残っているからだ。
ところが、情報中心システムでは処理全体の把握を支援する機能を持つ(表1)。そうなると、把握機能を使うのが当たり前になり、それなしで処理を進めるのがイヤになるだろう。それほど便利で、なくてはならない機能でもある。
表1、処理内容の設計と把握と実行の3要素で、既存OSから情報中心システムまで比較した結果
OSの進歩 =================>
「データ加工で大事なのは処理全体の把握
既存OSにおいてはアプリケーションの存在がじゃま」
情報中心システムの処理把握機能は、流れ図として処理の流れを描く(図1)。データと処理のブロックを線で接続し、処理内容を視覚的に表現する。データと処理とを線で結ぶことで、処理の流れを作成する。一番上はデータブロックで始まり、次に処理ブロックが続く。データと処理のブロックが交互に並んで、最後はデータブロックで終わる。処理ブロックでは、上が入力で下が出力を表す。1つの処理ブロックで、入力データのブロックが複数のことも、出力データのブロックが複数のこともある。処理ブロックとデータブロックには、自由な名前をつけられる。
図1、処理流れ図を作成する画面の概略イメージ。処理の流れを示すブロックを並べ、各ブロックの中身を規定する。右上にあるのは、一時的に退避したブロックの一覧
1つの処理流れ図が複雑になる場合は、一部のブロックの集まりを別な図として分離し、複数の図を階層的に区分けする。これによって、処理の内容が把握しやすくなる。また、処理上の意味で下位の流れ図を分離すれば、別な処理でコピーして使うことも可能になる。流れ図の流用は、作業の軽減に役立つ。データブロックの中身として指定するのは、データの意味を表す構造体名か項目名になる。人物データとか、企業の財務データとか、比較的大きな枠組みである構造体名を指定することが多い。逆に、人物の身長データとか、企業の資本金データというように、細かな項目名を指定することもある。どちらにするかは、処理の目的で決まる。一番上に位置するデータブロックだけは特別で、データが保存してある抽出元を指定する。自分のハードディスクや、ネットワークで接続された外部データなどだ。それに抽出処理を通して、人物データなどを引き出す。
抽出以外の処理ブロックの設定内容は、データから導き出すことが多い。上のレベルのデータが決まると、そのデータを扱う処理が限定されるからだ。このため処理ブロックの設定は、候補となる処理内容から選ぶ形になり、操作が簡単ですむ。
流れ図を描く順番は、上からとは限らない。最終的に得たいデータが決まっているなら、一番下から始める。得たいデータの項目名か構造体名を指定して、それを得るための処理を選んでいく。この作業こそ、以前に説明したObject First機能そのものだ。つまり、処理流れ図は、ユーザーから見たObject First機能の姿のひとつでもある。
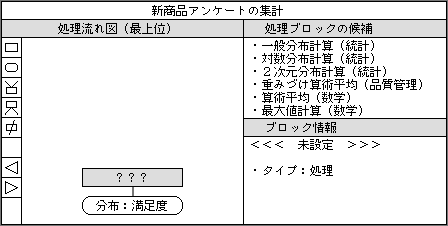
Object First機能が働くため、一番下に指定した項目名から、それを生み出すための処理の候補を自動的に表示してくれる。そのタイミングは、空の処理ブロックを追加したときだ。一番下にデータブロックがあり、その上に処理ブロックを追加すると、Object First機能が動き出し、知識ベースを参照して、処理ブロックの中身になることができる候補を表示する(図2)。この中から選ぶので、処理内容の設定は容易だ。もし処理内容が不明なときは、処理の意味を説明したヘルプを参照する。
図2、処理流れ図を作成する画面では、上下に隣り合ったブロックから導かれる処理候補やデータ候補を表示する機能がある。この例は、一番下のデータブロックを決めたので、それを導き出すための処理を候補として表示したところ
一番上や一番下ではなく、途中からブロックを描くこともできる。そのとき、データブロックではなく、処理ブロックを最初に描いてもかまわない。画像合成や統計のように、処理を中心に考えたほうがよい場合もあるので、処理を先に描く機能もサポートする。
処理ブロックに処理内容を設定すると、選ばれた処理内容の定義から、入力や出力で使う項目名が決まる。ただし画像合成のように汎用的な処理の場合は、項目名が決まる代わりに、データのタイプが決まる。両方とも、データブロックを設定するときに役立つ情報だ。
データと処理のどちらから始めても、最終的には、データと処理の関係として流れ図が仕上がる。処理として指定できるのは、知識ベースに定義した全部の処理が対象だ。画像処理からシミュレーションまで、どの機能でも利用できる。情報中心システムに組み込む全部の機能は、項目定義と処理定義の形式をとるので、このようなことが可能だ。
処理流れ図の最も重要な点は、たんなる図ではないことだ。ここで定義した処理は、実際のデータを処理する実行と連動する。つまり、流れ図を描くことは、処理を設計することに等しい。この部分こそ、情報中心システムならではの機能だ。既存OSのようにPIMソフトにメモしたのでは、絶対に実現できない。
流れ図を描いている途中でも、処理の実行が可能な条件を満たすと、バックグラウンドで実際の処理が動き出す。処理可能な条件とは、一番上となる抽出元が確定した状態だ。それに続く処理ブロックとデータブロックがペアで決まった部分まで、処理を実行する。処理ブロックだけが決まったのでは、処理で生成するデータが決まらないので、実行できない。処理ブロックとデータブロックがペアとして決まった段階で、処理を実行できる。
処理をバックグラウンドで実行するため、処理の進行状況を把握する機能も必要となる。別なモードで表示することもできるが、流れ図上で確認できたほうが使いやすい。そのため、進行状況を示す機能も加える。ブロックにマークをつけるとか、ブロック内を薄い色で塗りつぶす方法などが考えられる。
処理ブロックとデータブロックを、途中に挿入することもある。そのときは、挿入したブロック以降の処理を再実行する。画面の処理状況表示は一度クリアされ、実行の進行状況に合わせて再表示する。
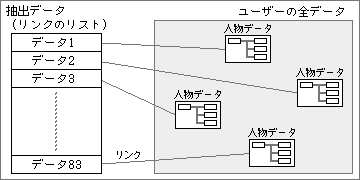
抽出したデータは、内部的にデータのリンクリストをつくる(図3)。対象となるデータへリンクを張るだけなので、元データに含まれる全項目が参照可能だ。加えて、つねに最新状態でデータを処理でき、余分なディスクスペースも消費しない。
図3、抽出したデータの内部での形は、リンクのリスト。各データは、元データにリンクしていて、つねに最新状態を参照できる
「ある条件が揃えば、流れ図が実処理を伴う
たんに流れ図を描くのに比べ、飛躍的に作業がラクになる」
各ブロックでの処理が終わると、データブロックにデータ件数を表示する。抽出したデータ件数が見られることは、いろいろな面で役立つ。たとえば、抽出データが1件もないのに、続く処理をつくっても意味がない。また、件数が予想とちがえば、続く処理を変えることもある。もちろん、抽出条件の設定ミスも考えられるので、条件を先にチェックする。どちらにしても、無駄な処理や作成を防止する手助けになる。
データ件数が予想とちがうとか、処理が正しいかどうかを確かめるために、処理した結果を見たいこともある。処理流れ図には、処理結果を呼び出す機能も加える。処理結果の見たいデータブロックを選択し、処理結果の表示機能を呼び出す。すると、データの自動表現機能であるAuto Expression機能が動き、データに適した表現方法を自動的に選んで結果を表示する。必要に応じて、表現方法を変えて表示させる。
データ件数が多い場合は、表示するデータを抽出したいこともある。そんなときは、もとの処理流れ図に抽出処理を加えて、希望するデータだけを表示させる。データ確認用の処理も、流れ図へ処理ブロックを一時的に追加することで対応する。抽出処理だけでなく、検算用の処理を追加することもできる。混乱を防ぐために、本来の処理でないブロックは、ブロックの表示を変えて区別する。
データ件数や途中の処理結果を見られることは、考えながら処理内容を決めることに役立つ。
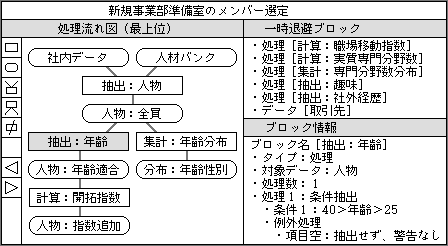
例として、図4のように新しい事業部の人材を決定する処理を考えてみよう。まず会社の人物データから条件抽出した結果を見る。もし人数が多すぎる場合には抽出条件を追加する。逆に人数が少ない場合は、外部の人材バンクのデータを抽出元として追加することも考えられる。どのように変えるかの判断には、抽出した人物データの中身を見るのが一番だ。
図4、複数の抽出条件での抽出結果を別々に見たいときは、抽出条件を並列に並べて、最後にデータを交ぜ合わせる。データブロックとして独立していれば、中間データとして個別に見ることができる
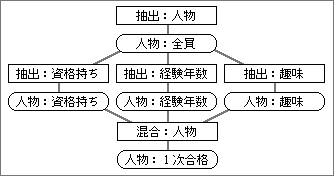
現実には、抽出条件を変えながら試行錯誤する場合のほうが多い。特定の資格を持つことを抽出条件に指定し、選ばれた人物データの細かな情報を見る。それで満足できないなら、別な抽出条件を指定する。こうして何度も変更しながら、目的に合う条件や処理を求める。1人でも見つかった抽出条件は残しておき、新たな抽出条件は別ブロックとして並列に追加する。このようにブロックを分けるのは、新しい条件だけで抽出したデータを見るためだ。複数の条件で抽出したデータは、後続処理の直前で交ぜて1つにする。
試行錯誤の段階では、抽出条件や処理内容をふたたび利用することが多い。そのまま使ったり、少し変更して使ったりする。それを支援するために、処理ブロックを外し、変更以前のものを残しておく機能もつける。無駄な作業をできるかぎりなくす重要な機能だ。処理定義に含まれるヘルプも、考えながら処理をつくる段階で役立つ。ヘルプには、処理の意味が説明してあり、適用すべき分野や目的を確認できる。また、似たような処理のちがいもわかる。考えながら処理を作成するためには、このような支援も必要だ。
処理把握機能が可能なのは、情報中心システムの基本構造がよいからだ。知識ベースと連動したObject First機能や、表示内容を自動生成するAuto Expression機能があって、初めて実現できる。既存OSのように、ファイルやアプリケーションという仕組みでは、このレベルでの実現は不可能だ。
ここまで説明したように、実処理と連動した処理流れ図は、コンピュータの使い方を根本的に変える。処理内容を把握しながら作成するだけでなく、結果を見て処理を修正できる。ユーザーのつくる内容が、データと処理との関係や流れを示すという点も見逃せない。本来の目的に近い形で、データを処理する環境だからだ。そのため、何をしているのかが把握しやすく、まちがいの発見も容易となる。
よく考えてみれば、処理の把握機能は、ついていて当たり前のものである。自分のつくった処理を把握しながら作業することは、最も基本的で重要なことだからだ。それが実現できていない既存のシステムを、初心者が使いにくいと感じるのは、当然の結果である。
逆に情報中心システムでは、作業の内容を目に見える形で表示および作成するため、初心者でも扱いやすい。ソフトを操作するという感覚ではなく、情報を直接扱うという感覚で使える。この違いは非常に大きく、コンピュータが格段に進歩したとユーザーは感じるだろう。
処理把握機能は、比較的小さな処理の把握を目的としている。この上のレベルとしては仕事全体の把握があり、それを支援する機能も一緒に必要だ。次回は、今回説明し残した処理把握機能の一部に加え、仕事全体での把握を支援する機能について解説する。
「実処理と連動した流れ図
情報を直接扱う感覚こそ、ユーザーが求めているもの」
処理内容を把握し、作業する仕組みがいかに画期的か? |
