
思考支援:雑誌連載の内容:第9回 |
どんなシステムにとっても、データの作成や保存の機能は重要だ。今回は、既存OSと情報中心システムとで、データ入力について比較してみよう。
既存OSでは、入力内容と表示結果が同じなので、使用するアプリケーションの上でデータを入力する。しかし、情報中心システムでは、入力内容と表示結果が同一にはならない。構造を持ったデータとして入力し、そこからいろいろな表示内容が生成されるのだ。
そのため、データ入力には専用モードを用意することになる。データの信頼性を高く保っておくために、データ構造や関連を意識しながら入力や修正を行うわけだ。正しく使用すれば、元データを二重に入力することがないというメリットもある。
システム全体の使い勝手を評価するうえで、データの入力と保存の方法は非常に重要だ。今回は、データ入力の機能について、既存OSと情報中心システムとを比較する。
本連載の第7回で述べたように、情報中心システムでは、作成結果と表示結果が異なる。作成結果というのは、ユーザーが入力した元データのことだ。情報中心システムでは、人物データや、企業の組織構成データなど、世の中のほとんどのデータが対象となる。どのデータでもなんらかの構造を持っていて、音や画像データなども構造の中に含まれる。加工する前のデータは、すべて元データに該当するのだ。
これに対して表示結果は、元データを処理して得られた結果データを含め、見やすく整えられた表示内容となる。一覧表や階層ブロック図や関連図など、すべての表示方法で作成した内容が対象である。情報中心システムでは、元データと表示結果が分かれていることが大きな特徴といえるだろう。
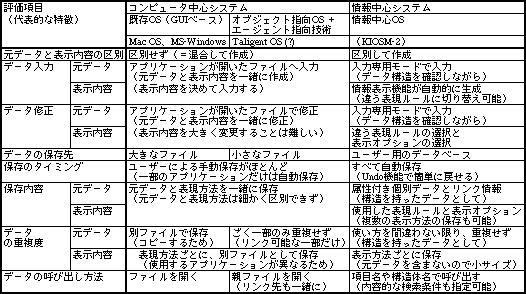
これに対して既存OSやオブジェクト指向OSでは、アプリケーションに依存したファイルという単位で入力し、その中には元データと表示結果を一緒に入れてしまう。それだけではなく、表示結果のほとんどをユーザーが自分で作成しなければならない。元データと表示結果の明確な区別は行われていない。ユーザーは、表示結果を意識しながらデータを入力するのだ。この点が、情報中心システムとの大きな違いで、データ入力などに差が現れることになる(表1)。
表1、データの入力や保存方法を、既存OSから情報中心システムまでで比較。情報中心システムでは、構造を持ったデータとして保存し、そこから各種表示内容を生成する。既存OSでは、同じ元データを用いても、表現方法ごとに別アプリケーションで別ファイルとして作成するので、データの一元管理は難しい。この点は、オブジェクト指向OSになっても変わらない
OSの進歩 =================>
情報中心システムの特徴は、元データと表示結果を区別するという点だけではない。表示結果はシステム側で自動生成するので、ユーザーが入力するのは元データだけに限られる。ユーザーは、表示結果を得るために最低限の指示をするが、オプションの設定を選ぶだけの操作でしかない。
また、表示結果は、元データの一部だけを抽出して作成する。たとえば、身長と体重の関係をグラフ化する場合、人物データの身長と体重データだけを用いる。ところが、ほとんどの人物データは、名前や住所データなどと一緒に、身長や体重データを格納している。既存OSのように、身長と体重データだけを1つのファイルとして入力するような使い方はしない。身長や体重データも、人物データの一部として入力するからだ。関連するデータは、すべての構造を持った形で保存するのが、情報中心システムの基本である。
このような構造のため、データを入力するときには、データ構造を強く意識する必要がある。意識するといっても、ユーザーがデータ構造を考える必要はない。システム側で自動的に知識ベースを参照し、そのデータ構造を表示するからだ。ユーザーは、その構造を見ながら、必要な値を入力する。
この方法だと、入力専用のモードを用意するしか方法がない。表示結果は、元データから生成した加工結果なので、その部分では入力できないことが理由だ。同様に、データを修正するときも、データ構造を見ながら行う。構造を持ったデータとして入力するからこそ、各種の先進的な機能が実現できるので、このルールを変えることはできないのだ。
システムで標準的に用意する入力機能は2つある。1つの独立したデータを入力する個別入力機能と、同じタイプのデータをまとめて入力する一覧表入力機能だ。それぞれ順番に説明しよう。
データの入力では、なんのデータを入力するのかを、最初に選択する。身長と体重の例であれば、人物データを選ぶことになる。人物データは、知識ベース内では構造体定義に該当する。実際のところ、人物データの定義には数多くの項目が含まれる。氏名、住所、勤務先、趣味、血液型、嗜好品というように、いくらでもある。
ここから必要な項目を選択する作業が、次に続く。この段階では、本連載の第5回で説明したグループ定義を利用する。これは、特定の目的ごとに項目を選び、グループ化した定義だ。身長と体重の入力では、「体の大きさ」や「健康診断」などというグループ定義を選ぶことになる。もしグループ定義で不足する項目がある場合は、手動で項目を追加することも可能だ。
項目の選択が終わると、いよいよデータ入力の画面が現れる(図1)。これは、データベースのレコード入力画面と似たものだ。縦に項目が並び、入力する枠を表示する。
図1、個別入力の画面例。知識ベースの項目定義を利用して、項目名や意味などを一緒に表示する。単位は値ごとに自由に変えられる。日付の単位には、西暦と和暦がある
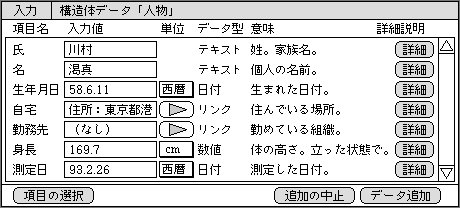
ここで重要なのは、知識ベースに含まれているヘルプ内容やデータのタイプや単位も一緒に表示することだ。その項目の簡単な意味を表示すれば、知らない項目の場合でも、より正確に入力できるからだ。人物データの場合は効果が小さいが、各種専門分野の値を入力するなら、初心者ほど役立つだろう。
数値や日付の単位は、デフォルトのものが表示され、その場で変更することも可能だ。ポップアップ形式で、同じ書類の単位だけを表示する。長さであれば、センチメートルのほかにインチやメートルなどが選べる。日本人はセンチメートルで入力し、米国人はインチで入力するといった使い方も簡単にできる。わざわざセンチメートルに変換して入力する必要はない。どの単位で入力しようと、AutoExpression機能が、統一した単位に値を変換して表示するからだ。日付では、西暦か和暦かも単位として扱う。これも表示するときに、西暦か和暦かに統一される。なお、項目のタイプには、勤務先のように、ほかのデータへリンクするものもあるのだ。
データの入力と更新では、他のデータと比較しながらのほうがやりやすいケースもある。同類のデータと比較することで、入力ミスが少なくなるからだ。そのため、一覧表形式での入力と更新もサポートする(図2)。この形式の画面表示は、1行が1データに対応し、項目数が多いときは横スクロールを利用する。
図2、一覧表形式の画面例。多くのデータを比較しながら入力するときに用いる。同じ項目名でも、個々のデータごとに単位を変えられる
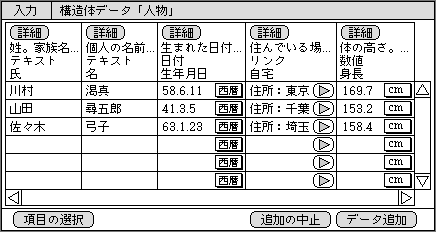
一覧表形式では、画面上に多くのデータを表示するため、項目ごとの意味などを表示するスペースが確保しにくくなってしまう。それでも見出しの上側には、データのタイプなどの最低限の内容を表示する。
単位に関しては、個々のデータごとに変更する必要があるので、データ部分に表示する。これもポップアップ形式で、選択可能な単位だけが現れる。基本的な操作方法は、個別入力機能と同じだ。
一覧表形式のデータ入力は、項目を追加するときにも役立つ。たとえば、住所録の目的で入力した人物データがあるとする。それらに身長と体重のデータを加える場合、追加項目は2つしかないことが明らかだ。そんなときは一覧表形式を選び、身長と体重の項目に続けて数値を入力したほうが効率的である。このように決まった項目を追加するときにも、一覧表形式の入力は役にたつのだ。
情報中心システムのような仕組みでは、データの属性やリンクが正しくないと、便利な機能が正常に動かない。他のシステムと比べて、データの信頼性が重要となる。その意味から、誤った修正を起こしにくくし、よく内容を確認してデータを修正する仕組みが必須なのだ。この点こそ、入力専用モードを用意する大きな理由である。
ただし、AutoExpression機能が生成した表示結果から、値のまちがいを見つけることもある。その場合に元データの修正を素早く行えるように、入力画面の呼び出し機能を強化する。表示結果上の値を選び、データ修正モードに切り替えることで、入力画面を表示するようにつくる。こうすれば、使い勝手の面での欠点はなくなる。
情報中心システムの場合、構造を持ったデータとして入力を行うので、元データは1つですむわけだ。元データを修正すると、いろいろな表示結果も自動的に更新されることになる。データの一元管理が徹底できる仕組みだ。
ところが既存OSでは、表現方法が違えば、違うアプリケーションにデータを入力しなければならない。このとき、元データを1つにして共有することはできない。つまり、1つのデータを重複して入力しても、それらが連動しないのだ。もしデータの修正が発生したときは、両方を修正する必要がある。しかも、どのファイルに入っているかは、ユーザー自身が覚えていないといけない。これは非常に面倒で、ほとんどの場合、連動させることは不可能だ。結果として、長期的視点で見た場合、データの信頼性は低下する。
「誤った修正が起こりにくくし、
よく内容を確認してデータを修正する仕組みが必須なのだ」
同じタイプのデータを整理して入力する場合、既存OSならデータベースソフトや表計算ソフトを用いる。そうしないと、分類や整理ができないからだ。表計算ソフトでは凝った整理が難しいので、データベースを利用する可能性が高い。しかし、あらかじめフィールド定義が必要なため、定義していない値は入力できない。
しかし、情報中心システムでは、知識ベースに定義してある項目なら、そのとき使わないと思っても、入力しておくことができる。たとえば、友人のデータを住所録の目的で入力するとき、身長と体重を知っている人がいたなら、入力しておいてかまわない。同様に、出身地とか血液型とか、知っているものはなんでも入力できる。
これに慣れると、入力するときに面倒だと思わないかぎり、知っていることは全部入力するようになる。「とりあえず入力しておくか」といった気軽さで、なんでも手あたり次第に入力する。その結果、データの種類や範囲がどんどんと広がる。より幅広いデータ入力は、コンピュータの利用範囲を広げることにつながる。メモする感覚で入力し、そのうち思いがけなく役立つことも経験するだろう。とりあえずなんでも入れられる点も、情報中心システムのメリットのひとつだ。
既存OSでは、元データと表示結果を一緒に作成する。このことに疑問を持つ人は、非常に少ない。「2つを区別しないことが当たり前」と思って最初から使っていたため、不自然に感じないからだろう。
しかし、情報自体の構造や特性を分析すると、構造を持ったデータとして入力するのが一番だ。データ構造まで入力するからこそ、あとから複数の表現方法での表示が可能になる。どの表現方法がよいかは、あとからユーザーが選べばいいのだ。
ひとつの例として、会社の組織図を描くケースを考えてみよう。ブロック図として描くのなら、ドローソフトなどを用いてつくる。しかし、欲しいのは、組織の階層構造を表現したものであって、ブロック図による組織図とはかぎらない。ブロックの中に描く文字数が多いときは、アウトライン形式のテキスト表示に接続線を加えた表現方法のほうが見やすい。最初にブロック図がよいと判断するときでも、それほど深く考えて選んでいるとは思えない。実際のところ、どの表現方法がよいかは、描いた結果を比べてみないと正確な判断はできない。
ところが、既存OSでは、どの表現方法を採用するかで、作成に使用するアプリケーションが決まってしまう。あとから変更する場合は、別のアプリケーションでつくり直すしかない。これでは、つくったあとで表現結果を比較することが難しい。つまり、表現方法をいくつも試せず、どの表現方法が適しているのか、いつまでたっても知ることができない。
情報中心システムでは、すべての表現方法を簡単に試せる。それは、AutoExpression機能が自動生成するからだ。表現方法を試行錯誤できる環境といえる。この結果、最適な表現方法について考えるようになり、得られる表示結果の質も向上する。これも、非常に重要なことだ。
情報の持つ特性を中心にシステムを考えた場合、既存OSが持っているこの種の不自然な構造が、いろいろと見えてくる。今後も、よりよいシステムを提案しながら、既存OSのよくない面を指摘していきたい。
「既存OSでは、どの表現方法を採用するかで、
作成に使用するアプリケーションが決まってしまう。
あとから変更する場合は、
別なアプリケーションでつくり直すしかない」
データ構造を強制的に意識させる入力機能 |
