
シス開発:使いやすいデータベースの構築法 |
データベースを構築する際には、最適なフィールド定義が重要である。それを求めるために、対象となる業務に関するデータ分析を実施する。データ分析とは、業務に関係するデータを調べて、その特性を整理することだ。それをもとにフィールドを定義すれば、適切なシステムが作れる。いわば、システム構築の要。その手順の概略を紹介する。
本格的に実施するには、正規化というデータ整理手法を理解する必要がある。データベースの専門家なら知っているはずなので、それ以外の人を対象として簡単な説明を加えた(これについては専門書が数多く出ているので、詳しい内容を知りたい人は、そちらを参照してほしい)。ただし、正規化も完璧ではなく、変化して困る値は正規化後に項目を追加する。また、トラブル解析用の項目なども追加する必要がある。これらの現実的な設計についても触れている。
使いやすくて役立つデータベースに仕上げるためには、フィールド定義の前に、対象となる業務をきちんと調べることが大切だ。どんなデータがあるか、どのタイミングで何を入力するか、どんな内容を印刷するかなど、関係する内容を明らかにする。このように業務の内容を詳しく調べる作業を、一般に業務分析と呼ぶ。
業務分析の中でも、データの構造を調べるのがデータ分析である。どんな項目があって、どのような関係を持っているのか、細かく調べる作業だ。データベースを設計する場合、このデータ分析が一番重要で、データ分析の結果をもとにフィールド定義を作成する。
データ分析の中で、必ず登場するのが正規化という作業だ。データの冗長性をなくし、同じデータを複数箇所へ入力するのを防止する。その結果、データの変更が生じても、一箇所だけを修正すれば済む。反面、値の参照が多くなるため、内部的な処理が増えて、応答性が低下する欠点も持つ。しかし、データの信頼性を重視するなら、正規化の結果を重視してデータベースを設計すべきだ。
正規化によって得られたデータ分析結果は、複数の表の形になる。そして、複数の表のデータを組み合わせながら、目的のデータを作る。このような構造は、リレーショナル型のデータベースに適した形だ。そのため、正規化によって得られた理想的なデータ定義は、カード型データベースでは実現できない場合がほとんど。その点を理解してか、リレーショナル機能を備えるデータベースが増えている(ファイルメーカーProもその1つ)。きちんとしたデータベースを構築したいなら、リレーショナル機能を持ったソフトが必須だ。
データ分析の作業は、これが定番という作業手順はない。多くの人は、過去の経験と照らし合わせながら、自分なりの方法で実施している。手順として細かく整理している人は少ない。要点さえ理解していれば、順序が多少変わっても適切な結果を得られるためだ。
しかし、データ分析をしたことがない人にとっては、きちんとした手順を示されたほうが、より良い分析結果を迷わずに得られるだろう。ということで、お勧めの手順を作ってみた(表1)。絶対的な手順ではなく、初めてデータ分析をする人のための1例として捉えてほしい。最初のうちは、この手順にしたがって何度か試してみて、慣れたら自分なりの手順にアレンジするのが理想である。
用意した手順は、9段階になった。できるだけ理解しやすいようにと、細かく分けたためだ。手順に含まれる内容は、本格的な方法と基本的に同じである。要点だけを述べるといっても、考え方は変わらない。
この9段階にしたがって、順番に作業内容を説明する。細かな手順を意識せず、各行程での考え方に注目してほしい。それさえ理解できれば、適切なデータ分析結果を得られるとともに、自分なりのアレンジも可能となる。
表1、データ分析の基本手順。絶対的な手順ではないが、このとおり実施すれば、データ定義が効率よく得られる。
1、項目の洗い出し 思いつく限りの項目を洗い出す
全項目に適切な名前を付ける2、項目のグループ分け 意味付けしたグループに項目を分ける
グループ分けの結果が、最初の段階の表3、ソートや検索で必要な項目の追加 ソートや検索に必要な項目を追加する
(名前の読み、登録番号、など)4、キー項目の決定と識別項目の追加 表ごとに重複しないキー項目を決める
重複しない項目がないなら、識別項目を追加する5、必要度の設定 必要度を3レベルで区分けする
不要な項目を削除した表を作る6、正規化 正規化によって冗長性を排除する 7、記録用など目的で重複項目を追加 記録などの目的で必要となる項目を追加する 8、データベース・ソフトに合わせて最適化 使用するソフトに合わせて、表を最適化する
処理速度の向上がおもな目的9、トラブル解析用の項目の追加 トラブル解析時に役立つ項目を追加する
データ分析での一番最初の工程は、項目の洗い出し。対象となる業務で用いる全部の項目を、思いつくまま列挙する。実際に使うかどうかは後で判断するので、とにかく全部の項目を書き出すことが大切だ。
データベースを用いる業務は、これまで手作業で行ってきた場合が多い。その際に使用していた管理台帳や各種用紙などは、項目洗い出しのために役立つ。今まで使っていた資料を全部集め、それを見ながら項目を拾い出すと、効率よく作業が進められる。また、項目が漏れる可能性も低い。
すべての項目には、正式な名前を付ける。できるだけ短く、内容を正確に表す言葉を選ぶのがポイント。名前から意味が分かりにくい項目には、簡単な説明を加える。後で良い名前が思い浮かんだら、説明を削除して名前だけに直す。
日付のように何種類もの似た項目が挙がるものについては、どんな意味なのか区別できるように名前を付ける。単なる「日付」ではなく、「発注日」、「登録日」、「納入予定日」という具合に、違いを識別できるような名前を考える。同じ名前を持つのは、本当に値が同じ項目だけ。違う項目なのに同じ名前を付けると、間違いや混乱の原因となりやすい。
洗い出した項目は、人物とか取引先という単位でグループ分けする(図1)。すべての項目が、どれかのグループに含まれるはずだ。どんな単位でグループ化するかは、実世界の区切りに合わせて決める。人物や取引先などは、簡単に分けられるだろう。実際に物が存在しない抽象的な内容でも、取引のように現実の作業として考えれば、比較的容易にグループ分けできるはずだ。もし余った項目が出たら、それが属するグループを考えてみよう。グループ化できずに残っている項目は、単に余っているのではなく、洗い出し忘れているグループの一部かもしれない。それを考えるためのヒントになるはずだ。
グループ分けでは、同じ項目が複数のグループに属することもある。たとえば、取引先グループに含まれる取引先名称は、取引グループにも含まれる(図2)。その意味から、通常のグループ分けとは異なる。
実際の作業では、項目を洗い出し終わってから、グループ分けをするわけではない。項目を洗い出す段階でも、グループに分けながらまとめる。洗い出しの作業も、グループ単位で考えることで、項目の漏れを少なくできる。項目の洗い出しとグループ分けは、一体化して構わない作業である。
グループ分けが一旦終わった段階で、グループごとに必要な項目を見直す。項目の漏れがある場合、この段階で発見できることもあるからだ。
グループ分けした結果である各グループは、リレーショナル型データベースの1つの表に相当する。項目をグループで分けることは、基本となる表を作ることに等しい。ここで作成した表をもとに、段階的に改良しながら理想的な表を作るわけだ。これ以降の作業では、ここで作成した表を用いる。
図1、洗い出した項目は、関連する単位でグループ分けをする。
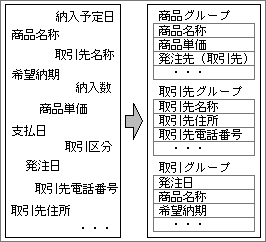
図2、項目のグループ分けでは、1つの項目が複数のグループに含まれても構わない。
項目を洗い出して整理する作業では、アウトライン・プロセッサが役立つ。クラリスワークスのように、アウトライン機能が付いたワープロソフトでも構わない。
1行に1項目を入れて、洗い出した全項目を入力する。項目名だけでは意味が正確に伝わりにくい項目については、項目名の後ろに短い説明を加える(図3)。「:」記号など挿入し、名前と説明を区切ればよい。順番の入れ替えが容易なので、思い付いた順に項目を入力し、後で整理する。
もう1つの利点は、階層構造によってグループ分けができること。最上位階層の一番下に「未整理」のグループを作り、新規の項目はまず「未整理」に入れる。入力した項目を見て、関連を持つグループが見つかったら、「未整理」から移動する形で、意味を持つグループを作る。「未整理」の部分に項目がなくなったら、グループ分けの作業は終了だ。
図3、アウトライン・プロセッサを用いると、項目の整理やグループ分けが容易になる。

基本的な項目以外にも、追加しなければならない項目がある。レコードの並び順を決めるための項目や、条件に該当するレコードを検索するための項目などだ。
並び順の決定で困る代表的な例は、人物を名前順に並べるケース。日本人の名前は漢字を用いるが、コンピュータ内の漢字コードでは、名前の読み順にはならない。名前を五十音順で並べるなら、名前の読みのデータが必要だ(図4)。会員名簿における氏名、取引先マスターにおける取引先名称などの重要な名称項目が、読みを加える対象となる。
余談だが、並び順が目的で企業の読みを入力する場合は、株式会社や有限会社の部分を除く
(表2)。漢字で入力する正式名称には含めまが、読みには含めない。この方法により、多くの人が望むより自然な並び順を実現できる。読みとして入力する値のルールも、データ分析の段階で決めておきたい。
名前の読み以外にも、並び順を決めるために必要項目はある。たとえば、登録した順番の番号や、承認した日付などだ。
検索のための項目追加は、レコードを抽出するのが主な目的。そのため、絞り込みに必要な条件を洗い出し、条件に含まれる項目が追加の対象となる。たとえば、取引先との取引年数が必要なら、取引開始年月日を項目に加える。たいていのケースでは、すでに挙げた項目に含まれているはずだ。
並び順であれ検索であれ、どのような項目が必要になるかは、データベースを利用目的に大きく関係する。その意味から、データの構造だけを独立して考えるのではなく、データの利用者や使用状況も合わせて考えることが大切だ。データ分析は、業務分析の一部であるため、業務分析の結果も利用しながら、データ定義を求める。
図4、漢字などの読みでソートしたい項目には、読みの項目を加える

表2、会社名の読みのデータは、「株式会社」や「財団法人」などを除いて入力する。
正式な会社名 入力する読み カレー食堂株式会社 かれーしょくどう 株式会社日本演芸工業 にほんえんげいこうぎょう 日本ミカン公社 にほんみかんこうしゃ 財団法人リンゴ互換機協会 りんごごかんききょうかい 林檎産業有限会社 りんごさんぎょう 有限会社ワクワク わくわく
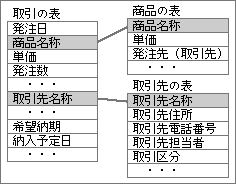
グループ分けした各表ごとに、重複しないキー項目を含めなければならない。最初は、洗い出した項目の中に、キー項目の条件を満たすものがないかどうか調べる。もしない場合には、新たにキー項目を追加する。
キー項目になるための条件は2つあり、最初の1つは、値が重複しないこと。他の表から参照されたとき、どのレコードかを特定するためには、重複する値が存在しては困るからだ。すべてのデータが違う値を持つことは、キー項目として必須の条件。人間の名前は、同姓同名の可能性があるため、キー項目として適さない。会社名も同様だ。
もう1つの条件は、入力しやすいこと。漢字やひらがなよりもアルファベット、それよりも数字のほうが入力は簡単だ。数字だけの識別コードを付けるのは、入力のしやすさを考えての結果である。たとえば、顧客コードに漢字を採用した場合を考えてみればよい。取引データを入力するたびに、かな漢字変換で漢字を呼び出すとしたら、入力は非常に大変だ。氏名をキー項目に採用しないのは、名前が重複する問題よりも、入力に不向きな点が大きいといえる。
キー項目に適した項目がない場合は、識別用の項目を追加しなければならない。一般的には、顧客コードとか取引先コードというように、番号を主体とした識別項目を追加する(図5)。データベースでは、よく見かける項目だ。
キー項目として追加した識別項目では、データベースの自動採番機能を利用することが多い。重複しない値を自動生成するので、人間か管理して決めるよりはるかに簡単だからだ。使用するデータベースソフトの機能に合わせて、自動採番できるような値を、識別項目のコード体系として決める。
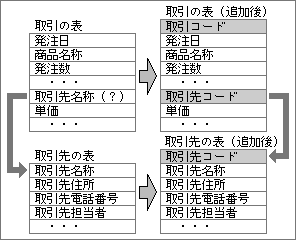
この段階の前までに用意した表が極端に悪いと、適切なキー項目を追加しそこなうこともある。たとえば、取引の表の中に取引先の全項目が含まれているケース(図6)。取引の表なので、取引コードをキー項目として追加するが、取引先コードの必要性に気付かないことも考えられる。逆に、取引先の表が別になっていれば、取引先コードを追加するだろう(図7)。このように、表の作り方によっては、必要なキー項目を見逃す可能性がある。
データ分析に慣れるまでは、グループ分けから正規化までの作業を何度もくり返し、適切な結果を求めるしかない。何度か経験するうちに、適切なデータ構造を最初から得られるようになる。
図5、他の表から参照するのに必要な識別用の項目を追加する。
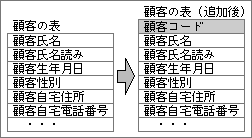
図6、分割の仕方が悪い表では、適切なキー項目を追加しそこなうこともある。

図7、分け方が適切な表なら、必要なキー項目の付け忘れが少ない。
ここまでは、いろいろな角度から捉えて、多くの項目を加えてきた。対象となる業務内容によっては、かなりの数の項目を含んでいるだろう。次は、必要な項目を選ぶ段階だ。
洗い出した全部の項目を、データベースに定義することもできる。しかし、項目数が多くなると、一番大変なのが入力作業。たとえ任意入力と決めても、項目があると入力したくなるからだ。必要のない項目をできるだけ削除することが、現実的には望ましい。項目数が少ないと、ファイルサイズが小さくなるとか、処理速度が向上するといったメリットも生まる。
具体的な区分け方法だが、すべての項目に「必須入力、任意入力、不要」の3レベルのどれかを設定する。必須入力は、どのレコードでも必ず入力する項目で、重要な内容が該当する。任意入力は、空のこともあり得る項目や、あまり重要でないものの、場合によっては使用する項目が対象だ。残りが不要に属し、使う可能性がまったくない項目。決定に際しては、データベースの利用目的などを十分に考慮する必要がある。あくまで、業務上の意味を重要視して決める。
レベル分けの結果を記号で表すと、作業がしやすい。たとえば、必須入力は「☆」、任意入力は「○」、不要は「×」というように。レベル分けした結果をもとに、不要の項目を削除した表を作る(図8)。
必要度によるレベル分けの作業は、正規化の前に行う必要がある。正規化では、データの冗長性を排除するために、表をどんどんと分割する。表を分けた後に不要な項目を削除したのでは、表自体が不要になるケースも出てくる。そんな無駄を生じさせないために、項目の選択を先に行う。
図8、すべての項目に重要度を設定し、不要な項目は削除する。
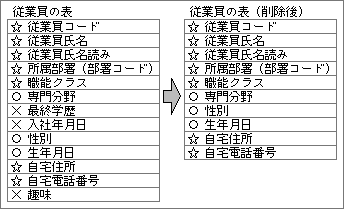
この工程で中心となるのは正規化だ。正規化というのは、データの冗長性を最小限に抑えるために、データの構造を整える作業である。この点を理解するには、良い例と悪い例を比較するのが一番だろう。
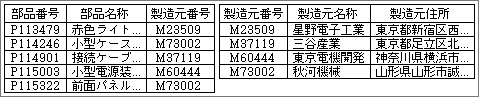
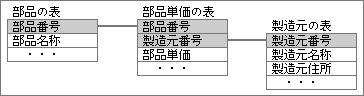
外注部品を管理する目的で、部品のデータベースを用意したとする。悪い例では、部品の表の中に製造元の名称や住所を入れる(図9、10)。1つの製造元が複数の部品を作るため、それぞれの部品レコードに製造元名称と住所を持つ。もし製造元の住所が変わったら、複数の部品で製造元住所を変更しなくてはならない。作業が面倒なだけでなく、修正し忘れが発生する可能性もある。本来なら一箇所にあるべきデータが、複数の場所に入力されていることが問題なのだ。
この欠点を改良して、無駄のないデータ構造を作るのが正規化。製造元の名称や住所を一箇所にまとめ、製造元番号で参照する構造に変える(図11、12)。製造元に関する全部の情報は、製造元グループという形で独立させ、他の表からは製造元番号で参照する。独立しているため、重複して入力することもなく、変更は一箇所で済ませられるのがメリットだ。結果として、データの信頼性が向上する。
正規化の作業は、1次から3次までの3段階に分かれている。しかし、ここでは要点だけ抜き出して説明する。実は、手順5までの工程でも、正規化の考え方の一部が含まれている。実際の作業では、ある程度のデータ構造が求められた段階で、正規化の考え方を適用する。得られたデータ構造が、適切であるかどうかを確認するための道具として用いるわけだ。大きな間違いを発見するのではなく、細かなミスを見付けるために活用することが多い。そのため、工程のこの位置に正規化を入れた。
図9、正規化していない表の例。「製造元名称」や「製造元住所」なども、部品の表に含めている。
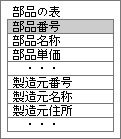
図10、図9のデータ構造で入力した表。「製造元名称」や「製造元住所」などが重複して入力される。

図11、図9を改良し、製造元の項目を別な表に移したもの。部品の表に含まれない項目は、「製造元番号」の値で参照する。
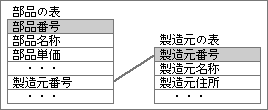
図12、図11のデータ構造で入力した表。「製造元名称」や「製造元住所」が1ヶ所なので、そこを変更するだけで済ませられる。
正規化の作業で最初に行うべきなのは、キー項目との関連を明らかにすること。前回の説明で、各表ごとにキー項目を追加した。それ以外のすべての項目で、キー項目との関係を考えてみる。
ここで言う関係とは、項目の値が決まるための条件だ。部品の表では、「部品番号」がキーになり、「部品名称」や「製造元番号」などの項目が並ぶ。「部品番号」が決まると、「部品名称」は自動的に特定できる(図13)。これが1:1の関係である。逆に、1つの部品で製造元が複数ある場合、部品番号に対して1:Nの関係となる。すべての項目に対して、1:1の関係になるように、表を分割するのが正規化なのだ。
関係を考える場合、どの項目に対して1:1になるのかも重要だ。正規化する前の表では、きちんと整理されてない状態なので、すべての項目がキー項目に直接関係する形にはなっていない。現実の世界を考えながら、項目間の関係を求める。「製造元名」のような項目は簡単で、「製造元番号」に対して1:1だと判定できる。難しいのは、「部品単価」のような項目。1つの部品で複数の製造元がある場合は、製造元ごとに単価が違う場合が考えられるからだ。このケースでは、「部品番号」と「製造元番号」が決まると「部品単価」が特定できるので、「部品番号+製造元番号」と「部品単価」が1:1の関係と定義する。どんな関係になるかは、実際の業務で決まるため、扱う部品の種類によっては、違う分析結果が得られる。この例での正規化後の表は、図11の例と条件が異なるため、違う結果になる(図14)。
図13、表が適切かどうかを調べるために、項目の関係を整理する。
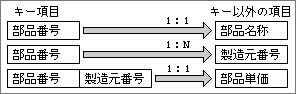
図14、1つの部品で複数の製造元がある場合には、表を分割する。
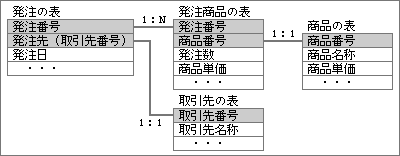
上記の考え方を適用する例を、もう少し詳しく説明しよう。正規化のもっとも単純な考え方は、繰り返し項目を分離することだ。表の中のキー項目に対して1:Nの関係がある項目は、繰り返し項目ともいえる。たとえば、1つの発注データの中に複数の商品があるとき、発注番号に対して商品番号は1:Nの関係だ(図15)。
同じように発注数や商品単価も、発注番号から見れば1:Nの関係である。しかし、別な面から見ると、発注数や商品単価は、商品番号に大きく関係した項目だ。商品番号と発注数と商品単価が1つのグループを形成し、そのが1つの単位となって繰り返しを形成する。この3項目のグループ全体で、発注番号と1:Nの関係を持つわけだ。
このような繰り返し項目は、別な表として分離する(図16)。新しい表で重要なのは、元の表のキー項目も一緒に持つこと。「発注番号+商品番号」がキー項目となり、残りの発注数と商品単価が、キー項目と1:1の関係になる。商品番号だけをキーにしたのでは、発注数と商品単価が特定できない。繰り返し部分を分離するときは、元の表のキー項目と、分離部分の重要項目を合わせたものが、新しいキー項目になる。
繰り返し項目の排除では、繰り返す項目が、どの項目に関係しているかを見極めることが重要。最初の表の状態でも、どの項目との間に1:1または1:Nの関係を持っているかを調べれば、表の分割方法が判断できる。
以上のように簡単な例だが、正規化の方法を紹介した。大切なのは、1つのデータを複数の場所に保存しないという点だ。これさえ理解できれば、正規化などと専門的に表現しなくても、同じことが実現可能である。
ここで紹介しているような項目名のデータ構造図が苦手なら、実際の表を作ってから値を入れてみて、重複するかどうか確認する方法が良いだろう。それを何度か試した後で、データ構造図と関連づけて考えれば、データ構造図にも慣れるはずだ。
図15、表の中に含まれる全部の項目で、キー項目との関係を明らかにする。「1:1」や「1:N」のどちらかになるはず。

図16、「1:N」の関係を持つ項目は、別な表として外に出す。

正規化をきちんと実行したデータベースでは、無駄なデータがない。どのデータも重複せず登録でき、お互いに他の表を参照することで、必要なデータを集められる。
ところが、正規化の結果も完璧ではない。あくまで静的な分析であって、時間的な変化まで考慮した分析方法ではないからだ。苦手なのは、参照する表の値が途中で変わる場合である。
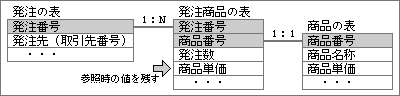
典型的な例は、発注データと商品マスターの関係。発注データには「商品コード」だけを入れ、「商品単価」は商品マスターから持ってくる場合を考えてみよう(図17)。ある発注が成立した後で、商品マスターの「商品単価」が変わり、そのあとで発注データを呼び出したとする。このとき表示されるのは、商品マスター内の新しい「商品単価」であって、発注した時点での「商品単価」ではない。正しい発注データを表示するためには、発注時点での単価を、発注データの中に含める必要がある(図18)。
このケースのように、参照する値が途中から変わって困る場合は、正規化あとで重複する項目を追加する。ただし、後で変わる可能性のあるデータをすべて保存したのでは、重複する項目が増えすぎて、正規化した意味がない。追加すべき項目は、金額などの重要な値だけに限定すべきだ。どの項目が重要かは、データベース化する業務側から考えて判断する。たとえば、取引先マスターの「取引先名称」も変わる可能性がある項目だが、変わったときの影響が少ないだけに、重複してデータを持たない。逆に、「取引先名称」が変わって困るような業務なら、「取引先名称」を取引データの中に持つことにする。どの項目を重複して持つかは、あくまで業務から見た重要度で決める。
図17、正規化した発注データと商品マスターの表。発注データ(発注商品の表)の「商品単価」は、商品マスター(商品の表)を参照して得る。
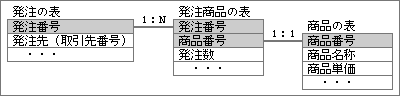
図18、図17を改良したもの。発注時の「商品単価」を残しておくために、「商品単価」の項目を「発注商品の表」に追加した。
正規化した結果は、データの冗長性を排除するために、数多くの表に分かれてしまう。そうなると、ユーザーが見たい表は、いつくかの表を参照して呼び出す形で内部的に処理される。当然、ディスクへのアクセス回数が増えるだけでなく、CPUの処理も何倍かに増える。ユーザーから見ると、応答が遅くなるわけだ。
どれだけ遅くなるかは、使用するデータベース・ソフトやマシンの処理能力やディスクのアクセス速度で決まる。また、データベースに入れるデータ量が増えるほど、遅くなる傾向がある。複数のユーザーが同時にアクセスする場合は、アクセスの重複度合いやネットワークのデータ転送速度によっても遅くなってしまう。
現実のデータベースを作る場合には、これら全部の要素も考慮しなければならない。正規化した結果をそのままフィールド定義に適応したのでは遅くなるときだけ、冗長性の排除を一部分だけあきらめて、応答性の良さを優先する。
どのように変更するかは、データベース・ソフトの特性だけで決まらない。素早い応答を要求されるのは一部の機能であり、業務の内容から、その部分を特定する。また、各表ごとのアクセスの頻度も考慮し、総合的に改良部分を決める。どの部分を直したら応答が良くなるのかは、データベース・ソフトを使い慣れていることと、内部的な構造を理解していることが必要だ。この辺は、データベース・ソフトを使い慣れた専門家に任せるしかない。
ただし、レコード件数が多くない場合は、極端に遅くなることは少ないので、正規化の結果のままフィールドを定義して大丈夫だ。もし遅くなった場合には、より高速なマシンやハードディスクに置き換えるなど、正規化を保ったままでの対処を最初に考えるべき。どうしても解決できない場合だけ、正規化を崩すのが基本である。
最後に追加するのは、トラブルが発生したとき役立つ項目の追加だ。何が原因かを調べたり、リカバリーすべきデータを区分けしたりするために、必要だと予想される項目を最初から用意しておく。トラブル解析用の項目は、どれも自動的に入力することが基本。自動入力の項目として設定するか、プロシージャによる入力処理を作成する。
よく使われる項目に、登録日付と更新日付がある(図19)。トラブルが発生した日に処理されたデータを探し、どのレコードで発生したかを調べるときに用いる。どのデータの処理中に起こったかを特定できれば、原因の究明に役立つ。データベース・ソフトやプロシージャのバグが、どんな条件のデータで発生するかを調べやすくする。1日の更新件数が多い場合は、レコードを特定しやすいように、更新時刻の項目も加える。
更新日付の値を正しく保つためには、入力以外の画面で入力できないように設定することが大切。また、トラブル解析以外の目的では使わないので、通常のレイアウトには項目を含めない。
よく使われるもう1つの追加項目としては、ユーザーIDがある。不正な改ざんの実行者を探し出すとか、間違った使用方法で入力した人のデータを抽出するときに役立つ。ユーザーIDの自動入力は、ネットワーク対応のデータベース・ソフトなら、たいていサポートしている。
トラブル解析用の項目を追加しても、それを表示したり検索できるレイアウトを用意してなければ、いざというときに役立たない。全部の項目を含めた解析用のレイアウトは、最初から用意しておきたい。
図19、トラブル解析時に役立つように、更新日付や時刻の項目も追加する。

ここまでで、データ分析の作業は終わりだ。分析で得られた結果(図20)をもとに、データベース・ソフト上でデータ構造を定義する。最近のデータベース・ソフトでは、表の項目を線で結ぶタイプが多いので、間違えずにフィールド間の関係を定義できる。
正規化の結果でデータベースを作ると、1つの画面で表示したいデータが複数の表に分かれているため、通常の作成手順とは少し異なる。表の間に関連づけを定義した後で、関連付けた項目まで含んだレイアウトを作成しする。それを用いることで、関連したデータを一緒に表示したり、関連付けながらの入力が可能だ。ファイルメーカーProのように、リレーショナル機能をあまり意識させずに、使いやすいレイアウトを作れるソフトもある。自分の力量に合わせて、適したソフトを選びたい。
図20、データ分析で得られたデータ構造の例。現実のデータでは、もっと多くの表が含まれ、関係も複雑になる。
一番重要な例外処理についても、少し解説しておきたい。データ分析の段階では、整ったデータ構造ばかり求めて、現実の世界をきちんと分析しないことがよくある。
実際の業務では、本来の流れから外れた例外処理がいくつも存在する。該当する例なら、いくつでも挙げられる。たとえば、部品を発注した場合、発注数を一度にまとめて納品せず、複数に分けて納入すること(分納)が考えられる。納入した部品の一部が不良品のこともあるだろう。また、発注を途中でキャンセルするとか、発注数を変更する場合も考えられる。そのとき、キャンセル分の金額の一部を支払うなら、キャンセルしたことやキャンセル料金も取引データに含めなければならない。
例として、分納への対応を簡単に考えてみよう。分納へ単純に対応するだけでなく、入力ミスの防止まで考慮する必要があり、実際にはかなり複雑だ。発注数が100個で、最初に20個が、2回目に30個が納入されたとする。このデータを入力する場合、発注番号だけで入力すると、同じ発注番号を何度も指定することになる。これを許すと、1回分の納入データを2度入力してもミスだと気付かない。重複入力を防ぐためには、同じ番号を複数回入力できないようにすべきである。1つの解決方法は、発注番号に分納番号を加えて、納品ごとの管理番号とすること。発注番号と分納番号を合わせた部分がキーになり、同じキーを持つデータは2度入力できないようにデータベースを作れば、同じデータの重複入力のミスを防止できる。
このように例外処理への対応は、データ定義にも影響を与える。どちらかと言えば業務分析に含まれる内容だが、データ分析にも関係が深いだけに、十分に調べなければならない。業務上の例外処理を考慮してないデータベースは、実際に運用し始めたとき、ユーザーから「使えない」との評価を下されることが多い。使ってもらうためには、例外処理への上手な対応が重要である。
ただし、すべての例外処理に対応したら、データベースは複雑なものになるし、作成の手間もかなり増える。どの部分をデータベース側で対処し、どの部分を手作業で対処するのか、現実的なところで線引きするのも大切な点だ。
ここまでの内容は、例外処理の話を除いて、比較的簡単なものを取り上げた。実際のデータベース構築では、より広い部分まで考慮しなければならない。そのためのヒントも、少し紹介しておこう。
1つのポイントは、時間軸を考慮することだ。更新のタイミングと頻度はどれぐらいか、定期的異に削除するのか、などを調べてみる。また、データはどんどんと増加するが、そのすべてを入れておくわけにはいかない。ある程度の期間を過ぎたデータは、別な形で保存するとか、ファイルを分けるなどの対処が必要だ。外に出す期間を事前に決めるとともに、その機能も最初から用意しなければならない。
2番目のポイントは、データの正しさを確保する方法だ。入力データが正しいかどうかは、入力検査として加える。そのルールを明確に規定しなければならない。難しいのは、複数の項目間での整合性を保つこと。ルールを規定するだけでなく、正しさを確保するための仕組みも考える必要がある。
3番目のポイントは、入力したデータの承認や検査の必要性だ。金額が一定額を越えたら上司の承認が必要だとか、途中で検査する工程を入れるかどうかを明らかにする。承認が必要な場合は、承認済みの項目を加えるだけでなく、関係のない人が承認処理を使えない仕組みも用意しなければならない。
以上のように、いろいろと考慮すべき点は出てくる。例外処理も含めて、これらをクリアーしなければ、使い物になるデータベースは構築できない。データ分析は、業務分析の一部であり、もっとも難しく大変な作業だ。また、実際の経験から得られたノウハウが多く必要な部分でもある。データ分析の善し悪しのほとんどが、業務分析の段階で決まると言っても過言ではない。
(1997年6月30日)
理想的なフィールド定義を作るデータ分析 |
