MC68000
1979年、Motorola社はMC68000を発表します。最初は4 MHzクロック品ですが、1年後には6 MHzクロックと8 MHzクロック品を発表。さらに10 MHzクロックや12.5 MHzクロックの製品も出てきます。マニュアルやサンプルで配られたLSIを納めたプラスチックケースのラベルには、Break Away from the Pastと書かれていて、その命令体系のミニコンピュータ的美しさやら16 bit CPUといいながら32 bitまでのデータ操作が普通にできることといったところと合わさって、過去との決別、新時代の雰囲気が感じられたものです。
使用トランジスタ数は型番どおりの約68000個、5インチウエファ上に4 um HMOS(高密度n-MOS)プロセスで作成されています。2段階マイクロプログラム制御を採用し、16 bit幅の演算処理回路を3組内蔵して並列処理可能な構造など、当時としては野心的で大規模な回路になっています。
2段階マイクロプログラムとは、下位レベルマイクロプログラム(ナノプログラム)で制御される回路を上位マイクロプログラムで制御する方式で、単一レベルのマイクロプログラム制御と比べて少ないマイクロプログラム容量で複雑な動作を実行できます。演算処理回路はデータ用、アドレス下位用、アドレス上位用が個別に用意されています。データ操作用には乗除算も可能な複雑な回路が用意され、データだから16 bit以下の演算中心ということで16 bit幅、32 bit演算は2回に分けて実行する形式になっています。アドレス処理に関しては、必ず32 bit演算を行わなくてはならないので、上位と下位のそれぞれに16 bit演算処理回路が割り当てられています。ただし、アドレス演算は(インデックス修飾などの)加減算が中心で乗除算などは不要ですから、若干簡単な回路になっています。データ用とアドレス用を分離したのは、メモリ参照に複雑なアドレッシングが使用されることが予想されるため、アドレス計算とデータ処理を効率良く実行するための工夫でしょう。なお、ここでいう演算処理回路というのは、レジスタとALUが一体化したような回路です。アドレスレジスタ上位の横にマルチプレクサがあって演算回路に接続されているものがアドレス上位用の演算処理回路というわけです。
当時の16 bit CPUとしては前年に発表の8086が1 MByteのアドレス空間で約29000個のトランジスタを集積、同年に発表のZ8000が8 MByteのアドレス空間で約17500トランジスタとなっていますから、ライバルと比べて倍以上のトランジスタを集積したぜいたくな回路といえるでしょう。もちろん、だてにトランジスタを使用しているわけではなく、32 bit演算が普通に可能で高度なアドレッシングモードを備えた、強力な命令体系を実現しています。
クロック周波数が8 MHzのとき、ほぼ1 MIPSの実行速度が得られます。

一番上はMotorola社のオリジナル。2番目が日立のセカンドソースの最初のバージョンで4 MHzクロック動作、その下が同じ日立のRマスク版で8 MHz動作のもの。下段左が基板面積をとらないPGAパッケージで日立製のSマスク10 MHzクロック版。一部メモリアクセスタイミングが改良されているマスクです。下段右がプラスチックパッケージにした日立の製品で、放熱特性の悪いプラスチックパッケージでも動作するように低消費電力化されたUマスクになっています。具体的にはSマスクで最大1.5 W消費していたのをマスクの再設計でUマスクでは0.9 Wまでに減らしています。
集合写真2番目の日立初期のHD68000-4を他の日立製HD68000と比べると、型番の上にRとかUの文字がありません。MC68000というと、今では標準が8 MHzクロックのように思えるかもしれませんが、開発当初は4 MHzクロックのものしかありませんでした。MC68000のバスサイクルは最短で4クロック必要ですから、4 MHzクロック動作では1回のメモリアクセスに1 usかかる計算になります。これでも1979年とか1980年の当時では、8 bitマイクロプロセッサとは大違いの高性能マイクロプロセッサとして扱われていたのです。なお、そのころはメモリが16 Kbitダイナミックメモリ全盛で64 Kbitのものが出始めたばかり、アクセスタイムが200 nsでサイクルタイムが500 ns程度というのが普通でした。それを考えると、4 MHzクロック動作のMC68000はマイクロプロセッサ側のバスサイクルが遅めでシステム性能を下げてしまう感じがしますね。だからこそ、速やかに8 MHzクロックの製品が主流になったのでしょう。
後にはCMOS版も作られています。1985年11月からサンプル出荷と同年9月20日に発表がありました。12.5 MHzクロックで最大200 mW、標準100 mWの消費電力ですから、一桁低消費電力になっています。

上ふたつが日立製のHD68HC000で、左がPLCCパッケージの8 MHzクロック版、右がシュリンクDIPの12.5 MHzクロック版です。下は通常のDIPに納められたモトローラ製MC68HC000で16 MHzクロックのもの。
ただ、CMOSへの移行はだいぶ遅れた感がありますけど。さらに後になって、こっそりと高速化されているのにも注目。下側は16 MHzクロック品です。最初の発表では12.5 MHz版までですから。すでに、このMC68HC000も廃品種で、一部機能に変更のあるMC68EC000になって・・・それからどうなったんだっけ。えーと、もちろんMC68HC000のCPUコアを使ってI/O周辺機能を集積した組み込み用のCPUも開発されて使われています。
プログラマから見たレジスタモデルは次のようになっています。
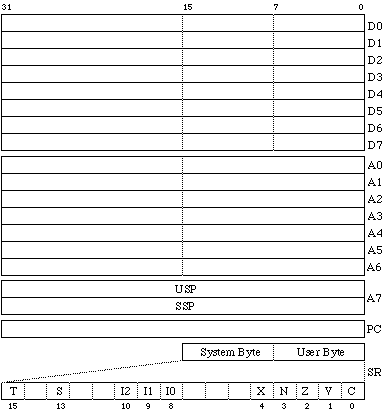
32 bit幅のデータレジスタが8本、32 bit幅のアドレスレジスタが7本、32 bit幅のスタックポインタが2本、32 bit幅のプログラムカウンタが1本、16 bit幅のステータスレジスタが1本と、完全な32 bit構成のレジスタです。これなら、扱うデータが16 bitだけどアドレス空間が24 bit幅でアドレッシングをどうしようなんて考えなくてもすむ、力技によって実現できる単純さです。
もちろん、データレジスタは8 bitデータや16 bitデータの操作もできるようになっていて、その場合はそれぞれLSBから8 bitか16 bitの部分が有効になります。たとえば、D0に8 bitデータをメモリからロードすると、上位24 bitは何も変化しません。同様に、D5に16 bitデータを加算すると、仮に桁上がりがあっても上位16 bit部分は変化しません。ステータスレジスタ内のフラグは変化するでしょうが。
アドレスレジスタはポインタレジスタやインデックスレジスタなどに使えるメモリアドレス操作専用のレジスタです。そのため、8 bitデータは扱えません。また、16 bitデータの演算操作を行なう場合も、データレジスタと異なり32 bitすべてが影響を受けます。単に16 bitデータをロードする場合でも、符号拡張が行われて全32 bitが変化します。また、アドレスレジスタ専用の加減算命令などありますが、演算フラグの変化のしかたもデータレジスタ用の加減算命令とは異なるため、注意が必要です。
スタックポインタはユーザスタックポインタ(USP)とスーパバイザスタックポインタ(SSP)の2本が存在します。この二つのスタックポインタは、もちろんサブルーチン呼び出しや割り込み時のプログラムカウンタの退避に使用するためのものですが、プロセッサの特権状態によって使い分けされます。ユーザモードのときにはユーザスタックポインタが、スーパバイザモードのときにはスーパバイザスタックポインタが、使用されます。つまり、特権状態によって決まる一方のスタックポインタしか使えません。ただし、スーパバイザモードでだけは、USPに値をロードする専用の特権命令を使用できます。スタックポインタは7番目のアドレスレジスタとしても使用できます。
プログラムカウンタも32 bit幅ですが、奇数アドレスをロードすることは禁止されています。命令は16 bit幅のワード構成で、必ず偶数アドレスから始まるアドレス位置に格納されていなくてはなりません。
最後に、ステータスレジスタ(SR)があります。上位8 bitをシステムバイト、下位8 bitをユーザバイトと呼びます。スーパバイザモードではSRの内容を自由に変更できますが、ユーザモードではユーザバイトだけしか変更できません。ただし、ユーザモードでシステムバイトの内容を読み出すことは可能になっています。フラグとしては、キャリー(C)、オーバーフロー(V)、ゼロ(Z)、負符号(N)、拡張(X)のおなじみの演算結果を保持するものがユーザバイトに納められています。拡張フラグは32 bitより大きなデータの加算時に桁上がりを保持するためのもので、従来のプロセッサのキャリーフラグの機能が、条件判定用のキャリーフラグと演算拡張用のXフラグに分離されたものです。たとえば、論理演算やMOVE命令ではキャリーフラグがクリアされますが、Xフラグは影響を受けません。システムバイトのI0, I1, I2は割り込みマスクで、Sがスーパバイザ状態ビット、Tはトレースモードビットです。Tビットがセットされると、直後の1命令を実行後に専用の割り込みシーケンスが起動するようになっています。そのため、デバッグ用プログラムでプログラムのシングルステップ実行制御を外部回路なしに実現できます。
つまり、トレースビットには、従来はマイクロプロセッサの外部回路で用意しなくてはならなかったシングルステップ制御回路をスマートにプロセッサ内部に取り込んで、その回路を制御するスイッチという役割が与えられているわけです。超LSI技術の進歩によって、これまでは内蔵できなかった機能を次々とチップ内部に取り込むことが可能になったのです。ただ、この時点ではメモリ管理ユニットや浮動小数点演算回路などまで取り込むほどの集積度は得られていないため、どちらかというとハードウェアやソフトウェアの開発効率向上とか信頼性向上に有益な小さめの工夫を多数取り入れた形になっています。たとえばトレース機能のほかに、スーパバイザ状態とユーザ状態が区別されて、全権を握るオペレーティングシステムと相互に保護されているプロセス群に分離した管理ができるようになっているのも、そのひとつです。ハードウェア面では従来と比べて高度なバスプロトコルを装備したのも、同じ例に挙げられるでしょう。プロセッサの外側に接続される回路規模も大きくなりがちであるという欠点はありますが、データがバスを介して転送されるあいだにノイズなどの影響でデータに誤りが生じても、従来のマイクロプロセッサのバスプロトコルより対策が施しやすいなど、大規模システムの信頼性を高められるように配慮されています。
アドレッシングモードもMC6809に劣らず高度で、それでいてシンプルといえるものが使用できます。
レジスタ直接アドレッシング
データレジスタ直接
アドレスレジスタ直接
レジスタ間接アドレッシング
アドレスレジスタ間接
ポストインクリメント付きアドレスレジスタ間接
プリデクリメント付きアドレスレジスタ間接
ディスプレースメント付きアドレスレジスタ間接
インデックス付きアドレスレジスタ間接
絶対アドレッシング
絶対ショート
絶対ロング
プログラムカウンタ相対アドレッシング
ディスプレースメント付き相対
インデックス付き相対
イミディエートデータアドレッシング
イミディエート
クイックイミディエート
インプライドアドレッシング
インプライドレジスタ
これだけのアドレッシングモードがあるわけですが、もっとも複雑なインデックス付きアドレスレジスタ間接モードでも、アドレスレジスタのひとつの内容にアドレスレジスタかデータレジスタの内容を加え、さらに8 bit定数値を加算した結果を操作対象アドレスとして使用するという意味で、強力といえば強力ですが、MC68020以降に拡充されたアドレッシングモードと比べればまだシンプルといえるでしょう。
レジスタ直接アドレッシングは操作対象が内部レジスタというアドレッシングモードで、データレジスタとアドレスレジスタについての2種類があります。命令によってはアドレスレジスタ直接が使用できないものや逆にデータレジスタ直接が使用できないものもあります。と、書いてしまうと、繁雑な規則を覚えなくてはならないような感じがしますが、普通は意識する必要がないと思います。Motorola式のアセンブリ言語形式だと、フラグ変化などが異なるためアドレスレジスタに対する操作は特別なニーモニックが与えられていて、そのためにアドレスレジスタ直接の区別が必要になるくらいの意味しかありません。
レジスタ間接アドレッシングはアドレスレジスタの本領発揮というところです。アドレスレジスタの内容をそのまま操作対象アドレスとするアドレスレジスタ間接と、前もって自動デクリメントしたり、後で自動インクリメントするプリデクリメント付きやポストインクリメント付きアドレスレジスタ間接は、C言語でいう単純なポインタを実装するのに使えます。特にプリデクリメントやポストインクリメントの機能をうまく使えば、スタックやFIFOといったデータ構造を効率良く実装できます。ディスプレースメント付きアドレスレジスタ間接モードは、指定したアドレスレジスタに16 bit定数を加算したものを操作対象アドレスとするモードで、スタックフレーム上に確保したローカル変数を参照するのに便利です。また、インデックス付きアドレスレジスタ間接モードは、指定したアドレスレジスタとインデックスレジスタを加算した上に8 bit定数を加算したものをアドレスとして使用するモードで、配列参照などの操作をアドレッシングモードとして実現できるようになっています。
絶対アドレッシングは、メモリの絶対アドレスによる参照です。アドレスを指定する定数として、16 bitの値を使用する絶対ショートアドレッシングと、32 bitの値を使用する絶対ロングアドレッシングがあります。絶対ショートの場合には16 bitの定数が符号拡張されてからアドレスとして使われるため、$000000から$007FFFまでと$FF8000から$FFFFFFまでの範囲のアドレスを参照することができます。MC68000では$000000から割り込みベクタテーブルが始まり、ROMを配置する必要があるため(少なくともメモリが必要)、$FF8000より上位にI/Oポートを設置することが多くなります。メモリと異なり、I/Oポートは絶対アドレス参照の方が便利なことも多いですから。もっともMC68681なんかを多数並べた場合には、インデックスレジスタで参照した方がデバイスドライバを共用できて便利かもしれませんけどね。I/O参照以外は、MC68000では絶対アドレッシングを使わないプログラミングが簡単にできます。絶対ショートを使用した場合でも、ディスプレースメント付きアドレスレジスタ間接アドレッシングモードを使用した場合と比べて同じクロック数で実行されますし、絶対ロングなら不利になります。あるルーチンで使用する変数類を参照する場合、ベースアドレスを一度アドレスレジスタにロードしてしまえば、そこからの相対アドレスを使用してディスプレースメント付きアドレスレジスタ間接アドレッシングを用いて簡単にアクセスできます。絶対アドレッシングと比べて遅くならないのですから、プログラムのモジュール化を進めやすいように、絶対アドレッシングは例外的な使用に留めることになるでしょう。
プログラムカウンタ相対アドレッシングはオフセットをPCの値に加えたものを操作対象アドレスとするものです。オフセットとして符号付きの16 bit定数を用いるものがディスプレースメント付き相対で、インデックスレジスタ(アドレスレジスタでもデータレジスタでも可)と8 bit定数を用いるものがインデックス付き相対です。なお、分岐命令については、8 bitオフセット定数を用いるプログラムカウンタ相対アドレッシングも使用されます。
イミディエートはごく普通ですが、クイックイミディエートというのは4 bitか8 bitの定数をオペコードの一部に含んだ特別に短い形式のイミディエートアドレッシングという意味です。
インプライドアドレッシングは、汎用レジスタ以外のレジスタに対する操作で、SR, CCR, USP, PCが使用できます。なお、CCRはコンデションコードレジスタで、SRのユーザバイト部分の別名です。
命令をとりあえずニーモニックだけ。
ABCD Add Decimal with Extend
ADD Add Binary
ADDA Add Address
ADDI Add Immediate
ADDQ Add Quick
ADDX Add Extended
AND AND Logical
ANDI AND Immediate
ASL Arithmetic Shift Left
ASR Arithmetic Shift Right
Bcc Branch conditionally
BCHG Test a Bit and Change
BCLR Test a Bit and Clear
BRA Branch Always
BSET Test a Bit and Set
BSR Branch to Subroutine
BTST Test a Bit
CHK Check Register against Bounds
CLR Clear an Operand
CMP Compare
CMPA Compare Address
CMPI Compare Immediate
CMPM Compare Memory
DBcc Test Condition , Decrement and Branch
DIVS Signed Divide
DIVU Unsigned Divide
EOR Exclusive OR Logical
EORI Exclusive OR Immediate
EXG Exchange Register
EXT Sign Extend
JMP Jump
JSR Jump to Subroutine
LEA Load Effective Address
LINK Link and Allocate
LSL Logical Shift Left
LSR Logical Shift Right
MOVE Move Data from Source to Destination
MOVE to CCR
Move to Condition Code
MOVE to SR
Move to Status Register
MOVE from SR
Move from Status Register
MOVE USP
Move User Stack Pointer
MOVEA Move Address
MOVEM Move Multiple Registers
MOVEP Move Peripheral Data
MOVEQ Move Quick
MULS Signed Multiply
MULU Unsigned Multiply
NBCD Negate Decimal and Extend
NEG Negate
NEGX Negate with Extend
NOP No Operation
NOT Logical Complement
OR Inclusive OR Logical
ORI Inclusive OR Immediate
PEA Push Effective Address
RESET Reset External Devices
ROL Rotate Left without Extend
ROR Rotate Right without Extend
ROXL Rotate Left with Extend
ROXR Rotate Right with Extend
RTE Return from Exception
RTR Return and Restore Condition Codes
RTS Return from Subroutine
SBCD Subtract Decimal with Extend
Scc Set According to Condition
STOP Load Status Register and Stop
SUB Subtract Binary
SUBA Subtract Address
SUBI Subtract Immediate
SUBQ Subtract Quick
SUBX Subtract with Extend
SWAP Swap Register Halves
TAS Test and Set an Operand
TRAP Trap
TRAPV Trap on Overflow
TST Test an Operand
UNLK Unlink
演算はアドレッシング指定によって指定された場所とレジスタの間で行われるのが普通で、ソースとディスティネーションに個別のアドレッシング指定ができるのはMOVE命令しかありません。
それなりに複雑な命令というのは、配列の添字の上下限を検査するのに使えるCHK命令や、スタック上にローカル変数領域を確保したり開放したりするのに使えるLINK命令とUNLK命令くらいでしょうか。
ハードウェア機能に関連した風変わりな命令には、RESET信号を出力して、プロセッサ以外の外部回路をリセットできるRESET命令とか、マルチバスマスタの同期に使用するためのTAS命令があります。16 bitデータバスに8 bit幅のI/Oポートを接続した際に効率良くアクセスできるようにするMOVEP命令も少々特殊かな。
これらを除けば、ごく一般的で平易な命令体系です。VAX-11のPOLYF命令やPOLYD命令のように係数ベクトルと変数の値を与えると1命令で多項式の計算を実行してしまうといった極端なCISC的命令はありません。文字列操作を1命令で行なうような命令もなく、ポストインクリメント付きアドレスレジスタ間接モードを用いた演算命令とDBcc命令を組み合わせて、小さなループとして実装することになります。
バイナリコードの方に目を移すと、オペコードは16 bit構成です。1 Byte命令はありません。アドレッシングモードによっては2 Wordのオペランドを持つものがあり、2オペランドのMOVE命令では10 Byte命令となることもあります。メモリが今ほど安価ではなくコード効率が重視された当時としては、ずいぶんとぜいたくなコード体系になっています。その分、レジスタやアドレッシングモードを増やして、命令数を減らそうとしているのでしょうが。
MC68000を用いて仮想記憶を実現するのは困難で、MC68000を2個用いて実装した例があるという話をご存じの方も多いでしょう。仮想記憶、特にワークステーションで多く使われるページング方式の仮想記憶について扱います。メモリを512 Byteから4 KByteのページと呼ばれる固定サイズの塊に区切って、ページ単位で管理を行い、ハードディスク上のデータとメインメモリ上のページをうまく入れ替えて、大量のメモリがあるように見せかける技術です。あるプロセスを実行中に、メインメモリ上にまだ割り当てられていないページを命令が参照しようとしたら、メモリ管理ハードウェアがそのページフォールトを検出して割り込みを発生し、割り込みによって起動したオペレーティングシステム内のメモリ管理ルーチンで、最近使用されていない実メモリ上のページを探し出し、ハードディスクに確保された仮想メモリのページと入れ替えを行い、割り当てられていなかったページが最初からそこにあったように見せかけて、再び元のプロセスを継続します。
ここで、MC68000は命令と命令の間に割り込みを与えれば完全なコンテキストを保存することが可能なのに、命令の途中で無理矢理に割り込みをかけると(命令のオペランドのアクセス時にページフォールトが発生したような場合)元のコンテキストに復帰することができないというのが問題です。これを2個のMC68000で対処するのに、1個は1命令遅らせて実行させることによって、ページフォールトを発生した命令の実行前のコンテキストに復帰させるための情報を得られるとしている説がありますが……それはちょっと違うぞということを書いておきます。
先に1命令遅延の方法が実現可能か考えることにすると、可能です。ただし、相当なコストが必要です。割り込みが起ころうが何をしようが、リセット直後から(正確にはオペレーティングシステムがページフォールトの可能性を予期してからですが)レジスタの内容まですべて一致させて1命令遅らせて実行させなくてはならないし、メモリへの書き込みは遅れて実行しているCPUにはさせてはならないのに、コンテキストを移すときにはメモリへ書き込みができるようにしなくてはならないし、コンテキストを移す間は別々の命令列を実行しなくてはならないのにメインのCPUが元のコンテキストを再実行しはじめたら再び1命令遅れて実行させるように同期をとらなければならないし、ハードウェアも、ソフトウェアも、大変な負担となってしまうのです。
では現実的にはどんな方法があるのか。なんとういか、意外な解決方法があります。ページフォールトの際には完全なコンテキストを保存できないし、そのために復帰することもできないのなら、ページフォールトでコンテキストを切り替えなければよいのです。MC68000のバスサイクルはデータアクノリッジ信号を返さなければ任意の時間だけCPUを待たせることができますし、バスエラー信号の与え方によっては、ある信号が変化するまでCPUをバスから切り離し、その後でもう一度同じバスサイクルを再実行させることができます。この、後者の機能をうまく使うというのがタネです。
ページフォールトがメモリ管理ハードウェアによって検出されると、ハードウェアによってメインのCPUをバスからいったん切り離してしまいます。切り離すといっても信号線2本の操作で充分。この状態で、別のCPU、別に8 bit CPUだろうが何だろうがかまいませんが、とにかく停止中のメインCPU以外の回路でハードディスクやメモリやメモリ管理情報にアクセスして、適切なページの入れ替え作業を実行します。その後で、メインのCPUにバスサイクルの再実行を行なわせれば、正しいデータをメモリから読み出すことができるというわけです。メインのCPUは、ページの入れ替え作業の間は何もせずに停止していただけですから、コンテキストを保存したり復帰したりする必要はありません。ページの入れ替えを行なうCPUは原理的には何でもかまわないわけですが、MC68000をメインのCPUとしたコンピュータのバスに接続しやすいのはMC68000だろうから、補助のCPUにもMC68000を採用すればハードウェアが簡単になります。補助のCPUはページフォールトが発生するまでは停止させられていて、メインのCPUがバスから切り離されてから活動状態になります。補助CPUがページを入れ替え終わって、再び停止状態になってから、メインのCPUのバスサイクル再実行を起動します。二つのCPUが同時に動作する時間はまったくありませんから、マルチプロセッサシステムで必要なバスの調停回路や同期確立回路も不要です。
ソフトウェアの視点から眺めてみても、メインのCPUは仮想記憶のページ入れ替えに関するコードは一切不要になります。どうせ自分で実行できないわけですから。仮想記憶管理用データの初期設定なんかは必要ですけどね。補助のCPUのコードは逆にページ入れ替えに必要なプログラムだけで、それ以外のオペレーティングシステム機能は不要です。まぁ、ハードディスクのドライバなんかは必要ですけど。というわけで、きれいに切り分けられて、実装やテストが簡単になります。
ま、MC68000でページング方式の仮想記憶を実装するには、こんな手があったということで。
Returnto IC Collection