
これはuPD7807で一般的なシュリンク64ピンDIPですね。以前はQUIPというジグザグに長さの異なるピンが出ている小型64ピンパッケージが主に使われていました。
これはuPD7807で一般的なシュリンク64ピンDIPですね。以前はQUIPというジグザグに長さの異なるピンが出ている小型64ピンパッケージが主に使われていました。

これは8 KByteのUV EPROMを内蔵したuPD78P09Rで、窓付きセラミックQUIPという珍しいパッケージに収められている。QUIPはQuad
In-line Packageの略で、4列の2.54 mmピッチのピンが出ている。ただし、内側の2列は、外側と1.27
mmだけ位置がずれている。
写真の縮尺は上のuPD7807と同程度でずいぶんと大きく感じられますが、普通のQUIPはパッケージの真横から1.27
mmピッチで引き出されたリードが互い違いに折り曲げて4列に整形されているので、シュリンクDIPより小型に感じられるはずです。
内部のプロセッサ部のアーキテクチャについて、例によってレジスタセットから眺めることにしましょうか。
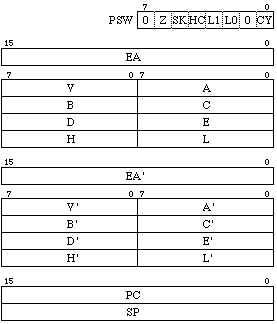
このように、8080とかZ80 CPUとそれほど違わないレジスタ構成になっています。
まずPSWはプログラムステータスワードの略で、フラグ類が納められたレジスタです。詳細は後述します。
8 bit幅のレジスタは、V, A, B, C, D, E, H, Lと、それに'記号の付いたレジスタがもうひと組あります。'付きはZ80
CPUの俗に言う裏レジスタに相当します。NECではZilogがZ80 CPUの2組のレジスタをそう呼んでいるように、MAINレジスタとALTレジスタという呼び方をしています。
16 bit幅のレジスタは拡張アキュムレータEAと、そのALTレジスタEA'、およびプログラムカウンタPCとスタックポインタSPがあります。オリジナルのuCOM-87アーキテクチャにはEAおよびEA'レジスタはありませんでした。uPD7807,
uPD7809, uPD7810, uPD7811のように16 bit ALUを備えたプロセッサに追加されたものです。なお、これ以降のアーキテクチャ紹介では、その拡張されたuPD7807について扱いますから、uCOM-87ファミリのプロセッサが最初からこれほど高機能であったとは思わないでください。
レジスタの名称の紹介は済みましたが、まだ機能には触れていませんね。Aレジスタはアキュムレータとして8
bit演算に使用されます。Vレジスタは、MC6809のDPレジスタに相当するもので、8
bitダイレクトアドレッシングで操作するメモリの上位8 bitアドレスを指定するレジスタです。VAレジスタペアとして、8080のAFレジスタペアのようにPUSH,
POP命令で退避したり、EXA命令でEAレジスタとともにV'A'レジスタペアおよびEA'レジスタと交換することができます。
B, C, D, E, H, Lレジスタは、やはり8080と同じように、スクラッチパッドレジスタと同じように使えるほか、BC,
DE, HLレジスタペアとしてポインタレジスタにもなります。さらに、DE, HLレジスタペアをポインタとして使う場合、8
bitデータ操作後にオートインクリメントやオートデクリメントする機能、16 bitデータ操作時には2だけオートインクリメントする機能もあります。しかもDEレジスタペアには8
bitデータでアドレス修飾を行う機能もあり、インデックスレジスタ的に使えます。HLレジスタペアには8
bitデータの修飾のほか、A, B, EAレジスタによる修飾も可能で、8080とは異なる多様なアドレッシングモードがあります。ただし、命令とアドレッシングモードの直交性はそれほど高くなく、比較的限定された命令でのみ使えると考えてください。EXR命令でEAからHLまでの全MAINレジスタをALTレジスタで入れ替えられるほか、EXX命令でBC,
DE, HLだけの入れ替え、EXHでHLレジスタペアだけの入れ替えが可能です。
EAレジスタは16 bitの拡張アキュムレータですから、当然16 bit単位の演算命令を中心に使用されます。その他、乗除算命令でも使われます。
PSWは、それ自体が命令の操作対象となることは、割り込みから復帰するRETI命令とソフトウェア割り込み命令SOFTI以外にはありません。個別のフラグ単位の操作はあり得ますが、全体を別のレジスタに転送するような命令は存在しません。割り込み時にスタックに保存されるだけです。割り込み許可フリップフロップなど割り込み関係の状態はPSWとは別の場所にあり、専用の割り込み許可・禁止命令やI/O操作によって操作することができますし、特別なテスト命令で調べることのできるものもあります。
PSWに話を戻すと、有効なフラグは6種類、残りの2 bitは0になっています。演算の結果によって影響を受けて条件判断に利用できる一般的なフラグが、ゼロフラグのZ、ハーフキャリーのHC、キャリーのCYの3種類です。命令実行シーケンス制御に使われるのが、スキップ条件成立を表すSK、MVI
A, byte命令の縦積み命令シーケンス実行中を表すL1、MVI L, byteやLXI H, word命令の縦積み命令シーケンス実行中を表すL0の3種類です。
SK, L1, L0フラグの意味はuCOM-87ファミリのプロセッサ独特の実行制御方式に関係しています。
まずSKフラグについてですが、uCOM-87ファミリには条件分岐命令がありません。ジャンプ命令は無条件のものだけです。では、どのように条件判断を行うのかというと、条件スキップということを行います。ある命令の実行時に、特定の条件が成立したら、次の命令を実行しないでもうひとつ先の命令を実行するという機能です。
スキップによる条件判定というのは、命令固定長のミニコンピュータなどではよく使われていました。私の手持ちではたとえばL-16Aがそうです。分岐命令には分岐先のアドレスを組み込まなくてはならないため、条件を示すビットパターンを分岐命令に追加すると命令長が長くなりがちで固定長命令に納めにくくなります。そのため、条件分岐命令をあきらめて、レジスタレジスタ間演算しかしない場合にはレジスタ指定フィールド以外にビットパターンが余るので、そこにスキップ条件を組み込み、演算した直後の命令をスキップするかどうかで条件分岐を実現する方法です。命令が1語固定長のコンピュータの場合なら、プログラムカウンタをよけいにインクリメントするだけで命令のスキップが可能で、ややこしい制御回路も必要ありません。
しかし、uCOM-87は可変長命令です。1 Byte命令から4 Byte命令まで多岐にわたっているので、プログラムカウンタをよけいに+1するだけでは命令のスキップがうまくいきません。もちろん、スキップできるのは特定の命令だけだという制限をつけるアーキテクチャもあり得るでしょうが、uCOM-87では任意の可変長命令をスキップできるようにしています。そこで、スキップ条件を満足したら、PSWのSKフラグをセットします。SKフラグがセットされた状態でも、次の命令をきちんと読み込んで命令の解釈を行いますが、実質的な命令実行を行いません。ただ、その命令の長さを決定して、その分だけ読み込みながら無視していきます。したがって、ある命令をスキップしても、その命令をスキップしなかった場合と比べてほぼ同じクロック数の時間が消費されます。さて、ここまでの話なら、PSWにわざわざSKフラグを組み込まなくても、内部フリップフロップを使えば実現できます。PSWにSKフラグを定義した理由は割り込みにあります。スキップ判定を含む命令の実行中に割り込みが発生すると、その命令の実行後に割り込みシーケンスが開始されます。割り込みサービスルーチンの最初の命令をスキップしては正しいプログラム動作を行えませんし、割り込みから復帰したときには割り込み前のスキップ判定結果に応じて適切にスキップしたりしなかったりできなくてはなりません。そこでPSWにSKフラグを組み込んで、割り込み時にはスタックに退避しておくようになっています。割り込みから戻るとPSWの内容も復元されるので、以前のSKフラグの状態に応じてスキップが行われるようになっています。
次にPSWのL1とL0の役割について説明します。これらのフラグは命令の縦積み制御に用いられます。uCOM-87では、MVI
A, byte命令、つまり8 bit定数をAレジスタにロードする命令が複数連続して配置されていると、2回め以降のMVI
A, byte命令は読み込まれるけれどもAレジスタへのロードは実行されないという機能があります。このようなMVI
A, byte命令の連続配置を縦積みと呼び、最初の命令しか実行されないことを縦積み効果と呼んでいます。このようなしくみが何の役に立つのか、簡単なコードで確認しましょう。Aレジスタの第3ビットが1になっていればPAポートに45Hを、0なら24Hを出力しなくてはならないというような場面を仮定します。このようなことは、機械か何かの制御を行うような用途では、よく見られるはずです。命令の縦積みを利用すると、次のように書けます。
ONI A, 08H ; A
& 08Hが0以外ならスキップ
MVI A, 24H ; 縦積み
MVI A, 45H
MOV PA, A
; Aの内容をPAに出力
最初のONI命令は、Aと定数の論理積が非0の場合にスキップを行う命令で、Aの内容は変化しないテスト命令の一種です。スキップしなかった場合、Aに24Hがロードされた後にMVI
A, 45Hが読み込まれますが、この命令は読み捨てられるだけでAの内容は変化せずに24Hのままです。スキップされた場合にはMVI
A, 45Hが最初の縦積み命令ですから、Aに45Hが入ります。バイナリコードでは8
Byteの長さになります。仮に縦積み制御がなければ、分岐命令がいくつか必要になるか、トリッキーなコードになるでしょう。このように、表を引くことによってコード変換をするには大げさだけれども分岐命令を用いるとコードが長くなりがちなコード変換の一種に縦積み命令は役に立ちます。
ONI A, 08H
JR L1
; 1 Byte分岐命令
MVI PA, 45H
JR L2
L1: MVI PA, 24H
L2:
これが分岐命令を用いた同じコードです。uCOM-87では6 bitオフセットの1
Byteジャンプ命令があるため、このコードでも10 Byteしか占有しませんが、先のコードより長くなっているのは確かです。
縦積み効果は3命令以上でも、命令が連続している限り有効ですから、たとえば今までの例題に先立ってAの第2ビットが1ならPAポートに出力する値が40Hだというような条件を付け加えると、こうなります。
OFFI A, 04H
JR L1
ONI A, 08H
MVI A, 24H
MVI A, 45H
L1: MVI A, 40H
MOV PA, A
これで合計13 Byteの長さのコードになります。OFFI命令はONI命令の逆でAと定数の論理積の結果が0のときにスキップを行うテスト命令です。縦積み命令の場合、スキップと同じように実行されない命令も読み込まれて縦積み命令かどうかの判定を行うことになりますから、あまり多くの命令を縦積みしてしまうと遅くなりがちです。あまりに多くの場合分けがある場合、表を引いた方が結局はコードも短く高速になります。しかし、この例の程度の規模だと、縦積みとスキップの規則を知っていればコンパクトでそれほど読みにくくもないことがわかるでしょう。
具体的にどのように縦積み命令の処理を行っているかというと、PSWにはMVI
A, byte命令でセットされ、この命令以外ではリセットされるL1フラグがあります。MVI
A, byte命令をプロセッサが読み込むと、L1フラグがセットされているかどうかをまず調べて、L1フラグがセットされていればAレジスタにデータを転送せず、ただ命令を読み飛ばしてL1フラグをセットします。L1フラグがリセットされていれば、Aレジスタにデータを転送して、L1フラグをセットします。このようにして、縦積み命令の処理を行います。ですから一連の縦積み命令の実行中に割り込みが発生しても、L1フラグを含むPSWが割り込み時に保存されますから、割り込み復帰後に正しく縦積み命令を処理できます。
L0フラグについてはMVI L, byte命令とLXI H, word命令についてL1フラグと同じように使われて、これらの命令の縦積み処理に使われます。
uCOM-87のメモリ空間は、すでにPCの幅などから想像できると思いますが、16
bitアドレス空間の64 KByteあります。IntelのMCS-48やMCS-51と異なり、プログラムもデータも同一のアドレス空間で、チップの内部にあるか外部にあるかでプログラムからのアクセス方式が変わることもありません。単一16
bitアドレス空間です。この点は、組み込み用シングルチップというよりは汎用プロセッサ的になっています。I/Oポートアドレス空間はありませんが、内蔵I/Oの制御に用いるレジスタは特殊レジスタ扱いで、専用のMOV命令などによってアクセスされるため、一種のI/Oアドレス空間とみなすこともできます。ただし、そのI/Oアドレス空間に別のポートを増設することはできません。Z80
CPUにおけるRレジスタやIレジスタと同様の形で内蔵I/Oポート制御レジスタ類が扱われていると思ってください。一部の特殊レジスタには、ビット操作命令や演算命令も適用可能です。
64 KByteのメモリ空間のうち、1000H未満には命令やハードウェアにとって特別な役割が与えられています。uPD7807は内蔵ROMを持ちませんが、uPD7808で0000Hから0FFFHまで、uPD7809で0000Hから1FFFHまでの間に内蔵ROMが割り当てられていましたから、そこに特別な役割を持たせるのは当然でしょうね。
まず、uCOM-87はリセット時にPCが0クリアされアドレス0000Hからプログラムの実行が始まります。したがって、アドレス0000Hがコールドスタート地点という意味を持ちます。さらに割り込みが発生すると、PCに特定の値がセットされ、そこから割り込みサービスルーチンが始まります。そのエントリポイントが、割り込みの種類に従って0004H,
0008H, 0010H, 0018H, 0020H, 0028H, 0060Hにあります。
次に0080Hから00BFHの64 Byteはコールアドレステーブルとしても使用できます。uCOM-87には16
bitアドレスをオペランドに持つ一般的な3 Byte長のサブルーチン呼び出し命令のCALL命令の他に、1
Byteサブルーチン呼び出し命令のCALT命令もあります。CALT命令では5 bit分のベクタ番号を命令に含み、最大32種類のサブルーチンを呼び出すことができるようになっています。それで、その32種類のサブルーチンの開始アドレスをどこに定義しておくかというのが、このコールアドレステーブルで、2
Byteで1エントリのアドレスを登録しておきます。たとえばCALT 0なら0080Hと0081Hからサブルーチンアドレスを読み出し、そこを呼び出します。CALT
1なら0082Hと0083Hという具合です。CALT命令とCALL命令の実行クロック数は等しいため、純粋にプログラムコードサイズを減らすのに役立ちます。上手にCALT命令を使えば、CALL命令を用いた場合に比べて200
Byteくらいはすぐに節約できるでしょう。4 KByteとか8 KByteのROMしか使えない時代ですからコードの節約は大事ですし、プログラムカウンタ相対の分岐命令のあるuCOM-87ではコードが短くなった方が相対分岐命令のアドレス範囲外エラーになる可能性も減りますからね。
そうして、最後の0800Hから0FFFHまでの範囲もサブルーチン呼び出しに関係しています。この2
KByteの範囲にあるサブルーチンは、2 Byteサブルーチン呼び出し命令であるCALF命令で呼び出せることになっています。CALF命令は11
bit分のアドレスフィールドを持ち、上位5 bitに00001Bを補ったアドレスへのサブルーチン呼び出しを行います。内蔵ROMが4
KByteしかなかった頃には、そのROMの半分の領域に納まったサブルーチンを呼び出す場合に1
Byte得をするのですから、それなりに役立ったのでしょう。
メモリ空間の0FF00Hから0FFFFHまでの256 Byteには内蔵RWMが配置されていて、プログラムから自由に使えます。さらに、そのRWMの内の0FFE0Hから0FFFFHまでの32
Byteはバッテリバックアップ可能ということになっていますが、uPD7807はn-MOSプロセスで製造されてCMOSでないわけでして、1
mA程度のバックアップ電流が必要なため、瞬停対策用でしょうね。uCOM-87ファミリの中でもCMOS化されたものでは使いやすくなりましたが。内蔵RWMは特殊レジスタへの設定で、アクセスを禁止できます。
命令体系は、8080のIntelニーモニック表記に近いので、レジスタセットと同じように8080風かなと思えますが、意外に違いがあります。スキップ命令と数の多い複合機能命令もありますし、B,
C, D, E, H, Lレジスタ間で自由にMOVできないとか、独自の命令セットと考えるべきでしょう。
NECの資料によると命令の種類は165命令となっていますが、命令表の項目数を単純に数えると168項目となっていますが、どうやらビット操作命令として追加されたMOV,
SK, SKN命令のニーモニックが、レジスタ間データ転送命令のMOV、スキップ命令のSK,
SKN命令のニーモニックと等しいので、165命令という数になっているようです。
これまで見てきた範囲では分岐命令やサブルーチン呼び出しに1 Byte命令が割り当てられているなど、コードを短くする工夫が凝らされているように思えますが、レジスタレジスタ間演算命令もほとんど2
Byte命令になっていて、平均的には1命令あたり2 Byteくらい消費されます。なお1
Byte命令から4 Byte命令まで存在します。
uPD7807は最大12 MHzクロックで動作し、3クロックで1ステートという内部処理単位が構成されます。つまり1ステート時間は250
nsです。最短の命令は4ステートで実行されますから、1 usが最短命令実行時間です。乗除算以外の一番長い命令が20ステートですから5
us、8 bitデータ同士の乗算で32ステートの8 us、16 bit割る8 bitの除算命令で59ステートの14.75
usです。なお、これはメモリウエイトステートのない場合で、リセット時には外部メモリアクセスに1ウエイトステートが挿入されるようになっているため、条件によっては実行時間も少し遅くなります。
これから命令の詳細について見ていくことにします。命令の機能でグループ化して順番に紹介します。
8 bitデータ転送命令には以下のものがあります。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
MOV r1, A
00011rrr
4 r1 <- A
MOV A, r1
00001rrr
4 A <- r1
MOV sr, A
01001101 11ssssss
10* sr <- A
MOV A, sr1 01001100
11ssssss 10*
A <- sr1
MOV r, addr 01110000
01101rrr al ah 17
A <- (addr)
MOV addr, r 01110000
01111rrr al ah 17
(addr) <- A
MVI r, byte 01101rrr
dddddddd 7*
r <- byte
MVI sr2, byte 01100100 s0000sss
dd 14
sr2 <- byte
MVIW wa, byte 01110001 wwwwwwww
dd 13*
(V.wa) <- byte
MVIX rpa1, byte 010010aa dddddddd
10* (rpa1) <- byte
STAW wa
01100011 wwwwwwww
10* (V.wa) <- A
LDAW wa
00000001 wwwwwwww
10* A <- (V.wa)
STAX rpa2
a0111aaa dddddddd(*1) 7/13*
(rpa2) <- A
LDAX rpa2
a0101aaa dddddddd(*1) 7/13*
A <- (rpa2)
EXR
01001000 10101101
8 VA BC DE HL EA入れ替え
EXX
01001000 10101111
8 BC DE HL入れ替え
EXA
01001000 10101100
8 VA EA入れ替え
EXH
01001000 10101110
8 HL入れ替え
BLOCK D+
00010000
13(C+1) (DE)+ <- (HL)+, C <- C - 1, until CY
BLOCK D-
00010001
13(C+1) (DE)- <- (HL)-, C <- C - 1, until CY
uPD7807には最大4 Byte命令があります。ここでは第1バイトと第2バイトは2進数表記、第3バイトと第4バイトは16進数的2桁表記で示します。state欄は命令実行時のステート数で、1ステートが3クロックに相当します。たとえば12
MHzクロックで動作しているとき、1ステートは250 nsですからMOV r1, A命令の場合には1
usの実行時間となります。state欄の数値の後についている'*'マークの意味は命令表の末尾に説明します。skipはスキップ条件を表しますが、8
bitデータ転送命令にはスキップ条件付きの命令はありませんので、空欄になっています。命令オペランドのr1,
sr, sr1などは命令表の後にあるオペランドの表を参照してください。ここで使われているオペランドのうち、大文字はレジスタそのものを表します。addrは16
bitアドレス定数、byteはイミディエートデータ、waはVレジスタと併用される8
bitアドレス定数です。上位アドレスをVレジスタの内容、下位アドレスを8 bit定数でアクセスするアドレッシングモードをワーキングレジスタアドレッシングと呼び、メモリ上の任意の256
Byteページに設定できる256本のワーキングレジスタセットと考えているので、waと呼びます。
MOV命令は一般的な8 bitデータ転送命令です。ただ、8080系列のプロセッサと異なり、レジスタ・レジスタ間転送は自由に行えず、必ず片方がAレジスタになります。つまり、MOV
B, CのようなことはuPD7807では実行できません。ダイレクトアドレッシングでメモリとのデータ転送を行うのもMOV命令の機能のうちです。8080ならSTA命令やLDA命令の役割ですが、Aレジスタにしか転送できない8080と異なり、uPD7807では任意のスクラッチパッドレジスタに直接転送できるようになっているのでMOVのニーモニックが与えられているようです。ダイレクトアドレッシングでは16
bitアドレスを用いますが、下位バイト(al)の方が命令の第3バイトに、上位バイト(ah)が命令の第4バイトに配置されます。
MVI命令は普通のレジスタ以外に特殊レジスタの主だったものに直接定数をロードできます。アキュムレータを書き換えずに特殊レジスタの内容を変更できるので有益でしょう。
MVIW命令はワーキングレジスタに定数をロードする命令で、MVIX命令はポインタアドレッシングで指定されるアドレスに定数をロードする命令です。
STAWとLDAW命令はアキュムレータとワーキングレジスタとのデータ転送です。ニーモニック側にAレジスタの文字が入っているため、オペランド側にはAのレジスタ名を記入しませんが、MOV
r1, Aと書くのに比べて対称的でないようでちょっと嫌な感じもしますね。レジスタ・レジスタ間転送は必ず一方のオペランドがAレジスタなのだから、LDA
r1とかSTA r1というような命令表記の方が統一感があるような気もします。単なる決まりといえばそれだけのことなのですが。
STAXとLDAX命令はポインタアドレッシングやさまざまなインデックス修飾のできる命令です。定数オフセットを必要とするアドレッシングモードの場合にだけ、第2バイトが必要となります。つまり表の中で(*1)となっているddddddddはアドレッシングモードによって省略される場合もあります。命令ステート数は1
Byte命令のときに7ステート、2 Byte命令のときに13ステートという意味になります。
EXR, EXX, EXA, EXHの各命令はそれぞれ関係するレジスタのALT側とMAIN側を入れ替える命令です。
BLOCK D+命令とBLOCK D-命令はブロック転送命令です。HLでポイントされるアドレスからDEでポイントされるアドレスへと、それぞれのポインタをインクリメントないしデクリメントしながら、(C
+ 1) Byteだけ転送します。正確に転送継続条件を記述すれば、Cレジスタをデクリメントして、その結果桁借りが発生してCYがセットされる場合に転送を中断します。つまりCレジスタに0が入っていると1
Byteの転送が行われます。そこには少し注意が必要です。なお、uPD7810など、この時点で存在する他のuCOM-87アーキテクチャのプロセッサにはインクリメント転送を行うBLOCK命令だけが存在して、デクリメント転送するBLOCK
D-命令は存在しません。そのため、他のプロセッサではBLOCK命令にオペランドも記入する必要もありません。おまけに他のプロセッサとはアセンブリ言語命令でほぼ上位互換になっていますが、バイナリコードは異なりますので、ファミリ内でも汎用ルーチンを他のプロセッサに移植する場合はアセンブリしなおす必要があります。そのへん、ファミリとはいえ、注意が必要です。組み込み用途のプロセッサで、内蔵I/Oの種類が異なるので、アプリケーションプログラム全体をそのまま移植する場面は考えにくいですが、単純なメモリのブロック移動やクリアルーチンもオブジェクトコード互換にはならないというのは期待を裏切りがちですから。
16 bitデータ転送命令には以下のものがあります。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
DMOV rp3, EA 101101pp
4 rp3 <- EA
DMOV EA, rp3 101001pp
4 EA <- rp3
DMOV sr3, EA 01001000
1101001u 14
sr3 <- EA
DMOV EA, sr4 01001000
110000vv 14
EA <- sr4
SBCD addr
01110000 00011110 al ah 20
(addr) <- C, (addr + 1) <- B
SDED addr
01110000 00101110 al ah 20
(addr) <- E, (addr + 1) <- D
SHLD addr
01110000 00111110 al ah 20
(addr) <- L, (addr + 1) <- H
SSPD addr
01110000 00001110 al ah 20
(addr) <- SPl, (addr + 1) <- SPh
STEAX rpa3 01001000
1001aaaa dd(*2) 14/20 (rpa3) <- EA
LBCD addr
01110000 00011111 al ah 20
C <- (addr), B <- (addr + 1)
LDED addr
01110000 00101111 al ah 20
E <- (addr), D <- (addr + 1)
LHLD addr
01110000 00111111 al ah 20
L <- (addr), H <- (addr + 1)
LSPD addr
01110000 00001111 al ah 20
SPl <- (addr), SPh <- (addr + 1)
LDEAX rpa3 01001000
1000aaaa dd(*2) 14/20 EA <- (rpa3)
PUSH rp1
10110ppp
13 (SP - 1) <- rp1h, (SP - 2) <-
rp1l, SP <- SP - 2
POP rp1
10100ppp
10 rp1l <- (SP), rp1h <- (SP
+ 1), SP <- SP + 2
LXI rp2, word 0ppp0100 wwwwwwwl
wh 10* rp2
<- word
TABLE
01001000 10101000
17 C <- (PC + 3 + A), B <- (PC
+ 3 + A + 1)
DMOV命令は16 bit転送で対象がEAレジスタという点を除けばMOV命令と同じです。特殊レジスタに対するDMOV命令は、16
bitアクセスが必要なレジスタにのみ適用可能になっています。
SBCDからSSPDおよびLBCDからLSPD命令はダイレクトアドレッシングによるレジスタペア・メモリ間データ転送です。SBCD命令など、減算命令の一種かBCD演算命令の一種に誤解しそうなニーモニックになっていますが、Store
BC Directの略なのでしょう。
STEAX命令とLDEAX命令は8 bitデータ転送命令のSTAX命令およびLDAX命令と対応したものです。(*2)の付いている第3バイトは、やはり8
bit定数修飾のあるアドレッシングモードにだけ存在します。2 Byte命令か3 Byte命令かに応じて実行ステート数も14ステートと20ステートの差が生じます。なお、DMOV命令やSTEAX命令とLDEAX命令でメモリ上のデータ配置は、他のレジスタペアの場合と同じく、EAの下位バイトが小さなメモリアドレスに対応します。
PUSH命令とPOP命令は8080命令と同様にレジスタペア単位でスタックに出し入れします。スタック上のデータ配置も、小さなアドレスにレジスタの下位バイトが対応します。
LXI命令はレジスタペア用のMVI命令です。
TABLE命令は、なかなか特徴的な複合命令です。Aレジスタの内容と16 bitデータとのコード変換を行う命令で、プログラムコードの中に定数表を埋め込めるようになっています。普通は1
Byte相対分岐命令のJR命令と組み合わせて定数表を飛び越えます。C言語のswitch文的な多重分岐を行う場合は、TABLE命令で行き先の番地をBCレジスタペアにロードして、ただちに1
Byte命令のJB命令で分岐することも可能です。定数表をプログラムコードの途中に埋め込みたくなければ、LDEAX
H+A命令などで似たようなことができますけどね。
次はレジスタ用の8 bit演算命令の表です。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
ADD A, r
01100000 11000rrr
8 A <- A + r
ADD r, A
01100000 01000rrr
8 r <- r + A
ADC A, r
01100000 11010rrr
8 A <- A + r + CY
ADC r, A
01100000 01010rrr
8 r <- r + A + CY
ADDNC A, r 01100000
10100rrr 8
!CY A <- A + r
ADDNC r, A 01100000
00100rrr 8
!CY r <- r + A
SUB A, r
01100000 11100rrr
8 A <- A - r
SUB r, A
01100000 01100rrr
8 r <- r - A
SBB A, r
01100000 11110rrr
8 A <- A - r - CY
SBB r, A
01100000 01110rrr
8 r <- r - A - CY
SUBNB A, r 01100000
10110rrr 8
!CY A <- A - r
SUBNB r, A 01100000
00110rrr 8
!CY r <- r - A
ANA A, r
01100000 10001rrr
8 A <- A & r
ANA r, A
01100000 00001rrr
8 r <- r & A
ORA A, r
01100000 10011rrr
8 A <- A | r
ORA r, A
01100000 00011rrr
8 r <- r | A
XRA A, r
01100000 10010rrr
8 A <- A ^ r
XRA r, A
01100000 00010rrr
8 r <- r ^ A
GTA A, r
01100000 10101rrr
8 !CY A - r - 1
GTA r, A
01100000 00101rrr
8 !CY r - A - 1
LTA A, r
01100000 10111rrr
8 CY A - r
LTA r, A
01100000 00111rrr
8 CY r - A
NEA A, r
01100000 11101rrr
8 !Z A - r
NEA r, A
01100000 01101rrr
8 !Z r - A
EQA A, r
01100000 11111rrr
8 Z A - r
EQA r, A
01100000 01111rrr
8 Z r - A
ONA A, r
01100000 11001rrr
8 !Z A & r
OFFA A, r
01100000 11011rrr
8 Z A & r
アキュムレータとレジスタの間を組み合わせて演算を行いますが、アキュムレータに結果が入るものとレジスタに結果が入るものの2種類が用意されています。このグループの命令は、普通の組み込み用マイクロプロセッサなら1
Byte命令が普通でしょうが、すべて2 Byte命令となっています。これもuCOM-87アーキテクチャの特徴といえるでしょう。実際、他の命令まで調べるとわかるように、1
Byte命令の方が珍しいのです。普通の考え方なら、命令を短く符号化してメモリ効率を高める設計方針をとることでしょう。そのかわり、どうやらuCOM-87の考え方では、多種類の命令を用意しておけば同じ機能のプログラムでも少ない命令数で記述することができ、その結果、個々の命令長が多少長くなってもプログラム全体のサイズが大きくはならないだろうとしているようです。
ADD, ADC, SUB, SBB, ANA, ORA, XRAの各命令は、Aレジスタがディスティネーションとなるかソースになるかの違いによって、2種類の命令パターンがあります。その点以外は、ごく一般的な演算命令です。
ADDNC命令とSUBNB命令は、スキップ条件付きの加減算命令です。表のskipの欄に!CYとあるのは、条件にNOTが含まれていることを表す'!'マークとスキップ対象のCYフラグを組み合わせたものです。つまり桁上がりがなければスキップということです。演算と一種の条件分岐が組み合わされた複合命令です。
GTA, LTA, NEA, EQA命令は比較命令で、演算結果は残らずにフラグだけが変化して、それに合わせてスキップが生じます。NEA命令とEQA命令ではディスティネーションとソースを入れ替える必要はないように思えるかもしれませんが、CYフラグの変化が異なります。たとえばNEA命令でふたつのオペランドが等しいかテストしてから、ただちにSK命令で大小判定を行うこともありますから、2種類用意されている意味はきちんと存在します。
ONA命令とOFFA命令は、論理積演算でマスクした後のビットがすべて0かどうかをテストする命令で、Aとrの順序を入れ替えても同じ意味となるので、一方の命令パターンしか存在しません。
さて、次はメモリ用の8 bit演算命令です。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
ADDX rpa
01110000 11000aaa
11 A <- A + (rpa)
ADCX rpa
01110000 11010aaa
11 A <- A + (rpa) + CY
ADDNCX rpa 01110000
10100aaa 11
!CY A <- A + (rpa)
SUBX rpa
01110000 11100aaa
11 A <- A - (rpa)
SBBX rpa
01110000 11110aaa
11 A <- A - (rpa) - CY
SUBNBX rpa 01110000
10110aaa 11
!CY A <- A - (rpa)
ANAX rpa
01110000 10001aaa
11 A <- A & (rpa)
ORAX rpa
01110000 10011aaa
11 A <- A | (rpa)
XRAX rpa
01110000 10010aaa
11 A <- A ^ (rpa)
GTAX rpa
01110000 10101aaa
11 !CY A - (rpa) - 1
LTAX rpa
01110000 10111aaa
11 CY A - (rpa)
NEAX rpa
01110000 11101aaa
11 !Z A - (rpa)
EQAX rpa
01110000 11111aaa
11 Z A - (rpa)
ONAX rpa
01110000 11001aaa
11 !Z A & (rpa)
OFFAX rpa
01110000 11011aaa
11 Z A & (rpa)
レジスタ用の8 bit演算命令と同じことを、ソースをメモリ上のデータとして実行します。ディスティネーションはAレジスタに限定されています。オペランドがrpaで表されている通り、BC,
DE, HLをポインタレジスタとして使えるほか、DEとHLのオートインクリメントやオートデクリメントアドレッシングも利用可能で、複数バイトデータの加減算などが容易になっています。
イミディエートデータ用演算命令は、このようになっています。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
ADI A, byte 01000110
dddddddd 7*
A <- A + byte
ADI r, byte 01110100
01000rrr dd 11
r <- r + byte
ADI sr2, byte 01100100 s1000sss
dd 20
sr2 <- sr2 + byte
ACI A, byte 01010110
dddddddd 7*
A <- A + byte + CY
ACI r, byte 01110100
01010rrr dd 11
r <- r + byte + CY
ACI sr2, byte 01100100 s1010sss
dd 20
sr2 <- sr2 + byte + CY
ADINC A, byte 00100110 dddddddd
7* !CY A <- A + byte
ADINC r, byte 01110100 00100rrr
dd 11 !CY r <- r + byte
ADINC sr2, byte 01100100 s0100sss
dd 20 !CY sr2 <- sr2 + byte
SUI A, byte 01100110
dddddddd 7*
A <- A - byte
SUI r, byte 01110100
01100rrr dd 11
r <- r - byte
SUI sr2, byte 01100100 s1100sss
dd 20
sr2 <- sr2 - byte
SBI A, byte 01110110
dddddddd 7*
A <- A - byte - CY
SBI r, byte 01110100
01110rrr dd 11
r <- r - byte - CY
SBI sr2, byte 01100100 s1110sss
dd 20
sr2 <- sr2 - byte - CY
SUINB A, byte 00110110 dddddddd
7* !CY A <- A - byte
SUINB r, byte 01110100 00110rrr
dd 11 !CY r <- r - byte
SUINB sr2, byte 01100100 s0110sss
dd 20 !CY sr2 <- sr2 - byte
ANI A, byte 00000111
dddddddd 7*
A <- A & byte
ANI r, byte 01110100
00001rrr dd 11
r <- r & byte
ANI sr2, byte 01100100 s0001sss
dd 20
sr2 <- sr2 & byte
ORI A, byte 00010111
dddddddd 7*
A <- A | byte
ORI r, byte 01110100
00011rrr dd 11
r <- r | byte
ORI sr2, byte 01100100 s0011sss
dd 20
sr2 <- sr2 | byte
XRI A, byte 00010110
dddddddd 7*
A <- A ^ byte
XRI r, byte 01110100
00010rrr dd 11
r <- r ^ byte
XRI sr2, byte 01100100 s0010sss
dd 20
sr2 <- sr2 ^ byte
GTI A, byte 00100111
dddddddd 7*
!CY A - byte - 1
GTI r, byte 01110100
00101rrr dd 11 !CY r -
byte - 1
GTI sr5, byte 01100100 s0101sss
dd 14 !CY sr5 - byte - 1
LTI A, byte 00110111
dddddddd 7*
CY A - byte
LTI r, byte 01110100
00111rrr dd 11 CY
r - byte
LTI sr5, byte 01100100 s0111sss
dd 14 CY sr5 - byte
NEI A, byte 01100111
dddddddd 7*
!Z A - byte
NEI r, byte 01110100
01101rrr dd 11 !Z
r - byte
NEI sr5, byte 01100100 s1101sss
dd 14 !Z sr5 - byte
EQI A, byte 01110111
dddddddd 7*
Z A - byte
EQI r, byte 01110100
01111rrr dd 11 Z
r - byte
EQI sr5, byte 01100100 s1111sss
dd 14 Z sr5 - byte
ONI A, byte 01000111
dddddddd 7*
!Z A & byte
ONI r, byte 01110100
01001rrr dd 11 !Z
r & byte
ONI sr5, byte 01100100 s1001sss
dd 14 !Z sr5 & byte
OFFI A, byte 01010111
dddddddd 7*
Z A & byte
OFFI r, byte 01110100
01011rrr dd 11 Z
r & byte
OFFI sr5, byte 01100100 s1011sss
dd 14 Z sr5 &
byte
イミディエートデータ演算命令は数が多いように見えますが、同一ニーモニックに3種類の命令パターンが属しているだけです。それはディスティネーションの違いで、Aレジスタになっているものと一般の8
bitレジスタになっているものと特殊レジスタの3パターンです。一般の8 bitレジスタの中にはAレジスタも含まれますが、Aレジスタがディスティネーションとなる頻度は高いだろうということで他のパターンより短い2
Byte命令のコードが割り当てられていますね。一般のレジスタおよび特殊レジスタがディスティネーションの場合には3
Byte命令になります。命令長が長くなりがちで使いにくいかといえばそんなことはなくて、Aレジスタに影響を与えずにレジスタ計算を行ったり比較を行ったりできるわけですから、結構便利です。しかも、I/Oポートの複数ビットを同時に変化させたり、あるいはテストもできるわけで、一度Aレジスタに持ってきてから演算を行って出力し直すような手間を考えると、わずか3
Byteでスクラッチパッドレジスタにも影響を与えずにI/O操作ができるのは、頻繁にI/O操作を行う組み込み用マイクロプロセッサの実際の応用にはとても有利です。
次はワーキングレジスタ用演算命令です。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
ADDW wa
01110100 11000000 ww 14
A <- A + (V.wa)
ADCW wa
01110100 11010000 ww 14
A <- A + (V.wa) + CY
ADDNCW wa
01110100 10100000 ww 14
!CY A <- A + (V.wa)
SUBW wa
01110100 11100000 ww 14
A <- A - (V.wa)
SBBW wa
01110100 11110000 ww 14
A <- A - (V.wa) - CY
SUBNBW wa
01110100 10110000 ww 14
!CY A <- A - (V.wa)
ANAW wa
01110100 10001000 ww 14
A <- A & (V.wa)
ORAW wa
01110100 10011000 ww 14
A <- A | (V.wa)
XRAW wa
01110100 10010000 ww 14
A <- A ^ (V.wa)
GTAW wa
01110100 10101000 ww 14
!CY A - (V.wa) - 1
LTAW wa
01110100 10111000 ww 14
CY A - (V.wa)
NEAW wa
01110100 11101000 ww 14
!Z A - (V.wa)
EQAW wa
01110100 11111000 ww 14
Z A - (V.wa)
ONAW wa
01110100 11001000 ww 14
!Z A & (V.wa)
OFFAW wa
01110100 11011000 ww 14
Z A & (V.wa)
ANIW wa, byte 00000101 wwwwwwww
dd 19* (V.wa)
<- (V.wa) & byte
ORIW wa, byte 00010101 wwwwwwww
dd 19* (V.wa)
<- (V.wa) | byte
GTIW wa, byte 00100101 wwwwwwww
dd 13* !CY (V.wa) - byte - 1
LTIW wa, byte 00110101 wwwwwwww
dd 13* CY (V.wa) - byte
NEIW wa, byte 01100101 wwwwwwww
dd 13* !Z (V.wa) - byte
EQIW wa, byte 01110101 wwwwwwww
dd 13* Z (V.wa) - byte
ONIW wa, byte 01000101 wwwwwwww
dd 13* !Z (V.wa) & byte
OFFIW wa, byte 01010101 wwwwwwww
dd 13* Z (V.wa) & byte
Aレジスタとワーキングレジスタ間の演算は、Aレジスタがディスティネーションとなっています。標準的な15種類の演算が用意されています。
イミディエート演算の場合には、当然ながらワーキングレジスタがディスティネーションになります。こちらはビット演算2種類と比較6種類の合計8命令だけが使えるようになっています。イミディエートでも3
Byte命令にするために、オペコードを1 Byteに限定したので15種類を割り当てることができなかったのかもしれません。
uCOM-87アーキテクチャでは、8 bitデータの記憶場所の階層をCPUにもっとも近い方から並べてみると、Aレジスタ、その他のスクラッチパッドレジスタ、ワーキングレジスタ、一般のメモリという順になります。先に出てきた方が演算に便利でしかも高速に扱える傾向があります。つまり、ワーキングレジスタはスクラッチパッドレジスタにも納めきれなかったデータの置き場なわけで、それを考えると適切な演算命令が選択されて、それらしい命令長になっているようにも思われます。なお、ワーキングレジスタは後述の増減命令のオペランドとなることもできて、ループカウンタをスクラッチパッドレジスタに納めきれない場面でも、その代わりに使えるように配慮されています。
次は16 bit演算命令と乗除算命令をまとめて紹介します。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
EADD EA, r2 01110000
110000rr 11
EA <- EA + r2
DADD EA, rp3 01110100
110001pp 11
EA <- EA + rp3
DADC EA, rp3 01110100
110101pp 11
EA <- EA + rp3 + CY
DADDNC EA, rp3 01110100 101001pp
11 !CY EA <- EA + rp3
ESUB EA, r2 01110000
011000rr 11
EA <- EA - r2
DSUB EA, rp3 01110100
111001pp 11
EA <- EA - rp3
DSBB EA, rp3 01110100
111101pp 11
EA <- EA - rp3 - CY
DSUBNB EA, rp3 01110100 101101pp
11 !CY EA <- EA - rp3
DAN EA, rp3 01110100
100011pp 11
EA <- EA & rp3
DOR EA, rp3 01110100
100111pp 11
EA <- EA | rp3
DXR EA, rp3 01110100
100101pp 11
EA <- EA ^ rp3
DGT EA, rp3 01110100
101011pp 11
!CY EA - rp3 - 1
DLT EA, rp3 01110100
101111pp 11
CY EA - rp3
DNE EA, rp3 01110100
111011pp 11
!Z EA - rp3
DEQ EA, rp3 01110100
111111pp 11
Z EA - rp3
DON EA, rp3 01110100
110011pp 11
!Z EA & rp3
DOFF EA, rp3 01110100
110111pp 11
Z EA & rp3
MUL r2
01001000 001011rr
32 EA <- A * r2
DIV r2
01001000 001111rr
59 EA <- EA / r2, r2 <- EA %
r2
以上の命令のディスティネーションはすべてEAレジスタに固定されています。
EADD命令とESUB命令はソースが8 bitレジスタになっています。16 bitと8
bitの加減算が必要な場面というのは案外多くて、まぁ8 bit同士の加減算のあとにキャリーの分だけ上位バイトをインクリメントないしデクリメントすればいいんで、それほど手間ではないのも確かですが、最初から用意されている分にはありがたいですね。ただし、80系の命令体系だと16
bitと8 bitの加減算を表操作のようなアドレス計算に使うことが多かったのですが、そのようなものについてはuPD7807では専用命令やアドレッシングモードとして用意されていますから、案外と使用頻度は低いかもしれません。
それ以外の、Dで始まる命令が16 bit演算で、8 bit演算に許されている15種類と同じ演算や比較操作が可能になっています。やはりディスティネーションがEAレジスタで、ソースの方はBC,
DE, HLのレジスタペアです。さすがにEAがソース側になる命令とか、イミディエート演算が可能な16
bit演算命令は用意されていませんが、レジスタレジスタ間演算に限られていても8
bit演算と同じ15種類の命令が用意されているのは強力です。すぐ後に出てきますが、このほかに16
bit演算の一種としてレジスタペアに対するインクリメントとデクリメントが用意されています。したがって、EAに上限(下限)を設定しておいて、レジスタペアをインクリメント(デクリメント)しながらEAと比較するパターンで16
bitのループカウンタも簡単に扱えます。
MUL命令とDIV命令が乗除算命令で、8 bit×8 bitの演算と、16 bit/8 bitの演算が許されています。さすがに他の命令とは別格の時間が必要となっていますね。
次は増減命令です。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
INR r2
010000rr
4 CY r2 <- r2 + 1
INRW wa
00100000 wwwwwwww
16* CY (V.wa) <- (V.wa) + 1
INX rp
00pp0010
7 rp <- rp + 1
INX EA
10101000
7 EA <- EA + 1
DCR r2
010100rr
4 CY r2 <- r2 - 1
DCRW wa
00110000 wwwwwwww
16* CY (V.wa) <- (V.wa) - 1
DCX rp
00pp0011
7 rp <- rp - 1
DCX EA
10101001
7 EA <- EA - 1
ここで特徴的なのが、8 bitの増減命令であるINR, INRW, DCR, DCRW命令がスキップ条件付きということと、その中でもレジスタオペランドのINR,
DCR命令がオペランドにr2をとるということです。
オペランドがr2であることから、A, B, Cレジスタしかインクリメント・デクリメントできません。D,
E, H, Lレジスタは1 Byte命令でインクリメントなどを行えないのです。ずいぶんと思いきった命令体系にしたものです。考えてみれば、uCOM-87アーキテクチャではD,
E, H, LレジスタはそれぞれDE, HLレジスタペアとして使われる場合が多くて、その際のループカウンタにはB,
Cレジスタのどちらかというのがほとんどでしょう。しかもループカウンタとして用いるのなら、ついでにスキップ動作も可能な方が便利という判断なのでしょう。
仮にスキップ動作が邪魔な場合、スキップされるかもしれない命令にNOPを指定すれば良いわけですが、対象がAレジスタの場合にはADI
A, 1などの命令の方が1ステート分だけ高速です。B, Cレジスタの場合には、ADI
B, 1などよりINR B; NOPという形式の方が命令長も短く高速になります。
16 bitの増減命令のINX命令とDCX命令はオペランドにSP, BC, DE, HL, EAの16
bitレジスタをとります。こちらはスキップ動作を行いません。16 bit分の計数を行うようなことを考えているのでしょうか。あるいは組み込み用のシングルチップであるuPD7807だと内蔵RWMが256
Byteですから、RWM上のデータをスキャンしながら何かの操作を行うようなループでも、8
bitのループカウンタで間に合って16 bitのループカウンタが必要となる場面がほとんどないと想定されているのかもしれません。なお、メモリ上に並べられたデータの操作の場合には、INX,
DCX命令を使ってポインタのインクリメントやデクリメントを行うより、オートインクリメントやオートデクリメントのアドレッシングモードを活用した方が便利です。
uPD7807系列に特有のビット操作命令には次のようなものがあります。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
MOV CY, bit 01011111
bbbbbbbb 10*
CY <- (bit)
MOV bit, CY 01011010
bbbbbbbb 13*
(bit) <- CY
AND CY, bit 01010001
bbbbbbbb 10*
CY <- CY & (bit)
OR CY, bit 01011100
bbbbbbbb 10*
CY <- CY | (bit)
XOR CY, bit 01011110
bbbbbbbb 10*
CY <- CY ^ (bit)
SETB bit
01011000 bbbbbbbb
13* (bit) <- 1
CLR bit
01011011 bbbbbbbb
13* (bit) <- 0
NOT bit
01011001 bbbbbbbb
13* (bit) <- !(bit)
SK bit
01011101 bbbbbbbb
10* (b) skip if (bit) = 1
SKN bit
01010000 bbbbbbbb
10* !(b) skip if (bit) = 0
CYをアキュムレータ代わりにしたロード、セーブと論理演算を行えるほか、メモリ上のビットに対する単項演算も実行できます。また、メモリ上の特定のビットに応じて条件分岐を行うことも可能になっています。CYに対する単項演算が不足しているように見えますが、それはこの直後に出てくるその他の演算命令のグループに納められています。CY操作はビット操作命令を持たないuCOM-87にも必要な命令ですから。
これらの命令のオペランドに必要なbitというのは、ビットアドレスを表します。ビットアドレスは8
bitの整数で表現され、そのMSBによってメモリビットアドレスとハードウェアビットアドレスの2種類にわかれます。メモリビットアドレスはワーキングレジスタの先頭16
Byteに含まれる128 bitの特定のビットを表します。ハードウェアビットアドレスはsr5に含まれる特殊レジスタのビットを表します。
具体的に、まずメモリビットアドレスの場合を考えます。対象メモリアドレス範囲はワーキングレジスタの先頭16
Byteですから、上位アドレスがVレジスタの内容、下位アドレス8 bitの内の上位4
bitが0、下位4 bitが0から0FHとなります。この下位4 bitの部分を3 bit左にシフトして、シフトした後にできた下位3
bitの空き部分にビット番号を格納したものがビットアドレスとなります。ビット番号はLSBを0、MSBを7とした番号です。ビットアドレスのMSBは0になります。たとえば、(V.03H)のMSBのビットアドレスは、1FHとなります。
ハードウェアビットアドレスは次の表のように定義されています。
| レジスタ名 | bit 7 | bit 6 | bit 5 | bit 4 | bit 3 | bit 2 | bit 1 | bit 0 |
| PA | 087H | 086H | 085H | 084H | 083H | 082H | 081H | 080H |
| PB | 08FH | 08EH | 08DH | 08CH | 08BH | 08AH | 089H | 088H |
| PC | 097H | 096H | 095H | 094H | 093H | 092H | 091H | 090H |
| PD | 09FH | 09EH | 09DH | 09CH | 09BH | 09AH | 099H | 098H |
| -- | - | - | - | - | - | - | - | - |
| PF | 0AFH | 0AEH | 0ADH | 0ACH | 0ABH | 0AAH | 0A9H | 0A8H |
| MKH | 0B7H | 0B6H | 0B5H | 0B4H | 0B3H | 0B2H | 0B1H | 0B0H |
| MKL | 0BFH | 0BEH | 0BDH | 0BCH | 0BBH | 0BAH | 0B9H | 0B8H |
| -- | - | - | - | - | - | - | - | - |
| SMH | 0CFH | 0CEH | 0CDH | 0CCH | 0CBH | 0CAH | 0C9H | 0C8H |
| -- | - | - | - | - | - | - | - | - |
| EOM | 0DFH | 0DEH | 0DDH | 0DCH | 0DBH | 0DAH | 0D9H | 0D8H |
| -- | - | - | - | - | - | - | - | - |
| TMM | 0EFH | 0EEH | 0EDH | 0ECH | 0EBH | 0EAH | 0E9H | 0E8H |
| PT | 0F7H | 0F6H | 0F5H | 0F4H | 0F3H | 0F2H | 0F1H | 0F0H |
| -- | - | - | - | - | - | - | - | - |
次はその他の演算命令です。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
DAA
01100001
4 BCD補正
STC
01001000 00101011
8 CY <- 1
CLC
01001000 00101010
8 CY <- 0
CMC
01001000 10101010
8 CY <- !CY
NEGA
01001000 00111010
8 A <- !A + 1
DAA命令は加算命令の後でAレジスタの内容をBCD補正するものです。STC, CLC,
CMC命令はCYフラグの操作を行います。サブルーチンから返すエラーフラグの処理とか、ビット操作命令の補助として使うことができます。NEGA命令はAレジスタの内容を符号付き2進数とした場合の符号反転命令です。
ローテーション・シフト命令には次のようなものがあります。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
RLD
01001000 00111000
17 Rotate Left Digit
RRD
01001000 00111001
17 Rotate Right Digit
RLL r2
01001000 001101rr
8 r2.(n+1) <- r2.n, r2.0 <- CY,
CY <- r2.7
RLR r2
01001000 001100rr
8 r2.(n-1) <- r2.n, r2.7 <- CY,
CY <- r2.0
SLL r2
01001000 001001rr
8 r2.(n+1) <- r2.n, r2.0 <- 0,
CY <- r2.7
SLR r2
01001000 001000rr
8 r2.(n+1) <- r2.n, r2.0 <- 0,
CY <- r2.7
SLLC r2
01001000 000001rr
8 CY r2.(n+1) <- r2.n, r2.0 <- 0, CY <- r2.7
SLRC r2
01001000 000000rr
8 CY r2.(n+1) <- r2.n, r2.0 <- 0, CY <- r2.7
DRLL EA
01001000 10110100
8 EA.(n+1) <- EA.n, EA.0 <- CY,
CY <- EA.7
DRLR EA
01001000 10110000
8 EA.(n-1) <- EA.n, EA.7 <- CY,
CY <- EA.0
DSLL EA
01001000 10100100
8 EA.(n+1) <- EA.n, EA.0 <- 0,
CY <- EA.7
DSLR EA
01001000 10100000
8 EA.(n+1) <- EA.n, EA.0 <- 0,
CY <- EA.7
RLD, RRD命令はZ80 CPUでおなじみのBCD一桁分、4 bitをAレジスタの下位4
bitと(HL)の間でローテートさせる命令です。
RLL, RLR, SLL, SLRは、ごく一般的なローテート、シフト命令です。SLL命令とSLR命令にスキップ条件を付けたのがSLLC命令とSLRC命令で、RLL,
RLR, SLL, SLR命令を16 bitに拡張したのがDRLL, DRLR, DSLL, DSLR命令です。8
bitオペランドの命令はr2が対象ですが、16 bitオペランドの場合にはEAレジスタに固定されています。EAだけでなくレジスタペアを指定できたらと思うこともありますが、加減算などの他の16
bit演算命令もディスティネーションがEAレジスタに限られていますから、これだけ拡張してもしかたないかもしれません。
ジャンプ、コール、リターン命令をまとめて表にしました。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
JMP addr
01010100 aaaaaaal ah 10*
PC <- addr
JB
00100001
4 PC <- BC
JR addr
11jjjjjj
10 PC <- PC + 1 + jjjjjj
JRE addr
0100111j jjjjjjjj
10* PC <- PC + 2 + jjjjjjjjj
JEA
01001000 00101001
8 PC <- EA
CALL addr
01000000 aaaaaaal ah 16*
push PC + 3, PC <- addr
CALB
01001000 00101001
17 push PC + 2, PC <- BC
CALF addr
01111jjj jjjjjjjj
13* push PC + 2, PC <- 00001jjjjjjjjjjjB
CALT addr
100ttttt
16 push PC + 1, PC <- (80H + 2*ttttt)
SOFTI
01110010
16 push PSW, push PC + 1, PC <-
0060H
RET
10111000
10 pop PC
RETS
10111001
10 1 pop PC, skip
RETI
01100010
13 pop PC, pop PSW
JMP命令は16 bit絶対アドレスをオペランドに持ち任意のアドレスにジャンプ可能な3
Byte命令です。JB命令はBCレジスタペアで示されるアドレスにジャンプする高速な1
Byte命令です。
JR命令は1 Byteの相対ジャンプ命令です。そのため、オフセットはjjjjjjで表されているように6
bitしかありません。ジャンプ範囲は限られていても、入力ポートの状態が変換するのを待つようなタイトなループでは有用です。しかし、このJR命令のために命令の第1バイトで使用可能な256パターンのうちの64パターンを消費しているため、他の演算命令が2
Byte長中心になってしまうことにもなっています。
JRE命令が標準的な2 Byteの相対ジャンプ命令ですが、オフセットが9 bit許されるようになっています。他の標準的な8
bitマイクロプロセッサより1 bit分だけお得なオフセットですね。JR, JRE命令の両者とも、命令コードのバイト数に関係なくJMP命令と同じ10ステートの実行時間を必要とします。
JEA命令はJB命令のEAレジスタ版で、EAレジスタの新設とともに追加された命令です。
CALL命令は標準的な3 Byte長のサブルーチン呼び出し命令で、CALB命令はJB命令と同様のBCレジスタペアによる呼び出し命令です。しかしCALB命令のほうがCALL命令より実行時間が長くかかるのが気になりますが。
CALF命令は少々変わっていて、2 Byte命令ですが下位11 bitのアドレスを命令コード中に持っていて、上位5
bitが00001に固定されています。つまり0800Hから0FFFHの間の2 KByteの範囲のサブルーチンを呼びだすことができる命令です。この範囲内に配置されたサブルーチンなら、CALL命令より1
Byteだけ短いコードで、しかも3ステート短い時間で呼び出せます。
もっと短いバイト数でサブルーチン呼び出しを行うのがCALT命令で、5 bitのベクタ番号を使用します。0080Hから始まる2
Byte単位でサブルーチンアドレスを登録したベクタテーブルのインデックスがベクタ番号となります。したがって、32種類のサブルーチンに限っては1
Byte長のコードで呼びだすことが可能です。
SOFTI命令はソフトウェア割り込みを発生させるもので、普通のサブルーチン呼び出しとはPSWがスタックに保存される点が異なります。スキップ条件に関してはSOFTI命令は特殊で、絶対にスキップされません。SOFTI命令の次に配置された命令がスキップされます。
RET命令はCALL, CALB, CALF, CALT命令で呼び出されたサブルーチンから戻るための命令です。
RETS命令は少々変わったRET命令で、戻った直後の命令をスキップします。つまり、たとえばCALL命令であるサブルーチンを呼び出したとき、そのサブルーチンからRETS命令で戻ると、CALL命令の次の命令がスキップされます。RET命令とRETS命令をうまく使うと、たとえばサブルーチンが正常終了したときにはRETS命令で戻り、エラーが生じたときにはRET命令で戻るようにすれば、CALL命令の直後にエラー処理用の命令(普通はエラー対処ルーチンへのジャンプ命令でしょう)を配置することで、エラー処理がスマートになるかもしれません。その他にも、たとえば文字コードがアルファベットならスキップするサブルーチンなど、なにかを判定するサブルーチンを書きやすくなります。
RETI命令は割り込みサービスルーチンからの復帰用の命令で、PSWも復帰するほか、割り込みマスクや割込み制御回路の操作も同時に行います。
スキップ命令には次の4種類が含まれます。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
SK f
01001000 00001fff
8 f skip if f = 1
SKN f
01001000 00011fff
8 !f skip if f = 0
SKIT irf
01001000 010fffff
8 irf skip if irf = 1, then reset irf
SKNIT irf
01001000 011fffff
8 !irf skip if irf = 0, or reset irf
これらの命令は指定されたフラグの状態によってスキップを行うものです。SK命令とSKN命令はプロセッサ内部の演算に関係したCY,
HC, Zフラグの判定を行います。HCフラグの判定ができるのは珍しい機能ですね。減算のBCD補正を比較的短いコードで実現できそうです。
SKIT命令とSKNIT命令は割り込みや特定のI/O機能に関係したフラグについて判定するものです。条件判定とともに、その対象フラグが1にセットされている場合には、リセットも同時に行います。SK,
SKN命令はSKフラグに影響を与えますが、CY, HC, Zフラグの状態を変更することはありません。
最後にCPU制御命令を示します。
命令
第1バイト 第2バイト 第3 第4 state skip 動作
NOP
00000000
4 no operation
EI
10101010
4 enable interrupt
DI
10111010
4 disable interrupt
HLT
01001000 00111011
11 halt
NOP命令は単にプログラムカウンタを1進めるだけの命令ですが、すべて0のビットパターンが割り当てられています。
EIとDIは割り込み許可と禁止を行う命令で、HLT命令はプログラム実行を停止する命令です。
これまでの命令表のstateの項目に*印が記入されている命令がありました。これは命令がスキップされる場合の例外規定を意味しています。一般に、命令がスキップされる場合には命令のデコードまでは行われますが、実際の処理は行われません。そのため、表に記入したステート数と同じか短いステート数を消費することになります。で、実際のスキップ時に必要となるステート数を表にして示します。
| 命令種別 | ステート数 |
| 1 Byte命令 | 4 |
| 2 Byte命令*付き | 7 |
| 2 Byte命令 | 8 |
| 3 Byte命令*付き | 10 |
| 3 Byte命令 | 11 |
| 4 Byte命令 | 14 |
以上の命令表に含まれる命令コードの中に埋め込まれているレジスタやオペランド指定ビットを表にして説明します。
8 bit幅のレジスタオペランドにはr, r1, r2の3種類のグループがあります。それぞれ、表の右半分の3列に対応するレジスタ名が記入されています。r2には3種類のレジスタしか含まれません。
| R2 | R1 | R0 | r | r1 | r2 |
| 0 | 0 | 0 | V | EAH | - |
| 0 | 0 | 1 | A | EAL | A |
| 0 | 1 | 0 | B | B | B |
| 0 | 1 | 1 | C | C | C |
| 1 | 0 | 0 | D | D | - |
| 1 | 0 | 1 | E | E | - |
| 1 | 1 | 0 | H | H | - |
| 1 | 1 | 1 | L | L | - |
I/Oポート用レジスタなどを含む特殊レジスタオペランドについてはsr, sr1, sr2, sr3, sr4, sr5の6種類のグループがあります。そのうちのsr, sr1, sr2, sr5については、次の表に示すレジスタを含み、S5 - S0のビットパターンで命令に表現されます。指定されているレジスタが書き込み専用か読み出し専用かなどによって異なる扱いを受けているわけです。
| S5 | S4 | S3 | S2 | S1 | S0 | sr | sr1 | sr2 | sr5 | レジスタの役割 |
| 0 | 0 | 0 | 0 | 0 | 0 | PA | PA | PA | PA | port A, ポートAデータ |
| 0 | 0 | 0 | 0 | 0 | 1 | PB | PB | PB | PB | port B, ポートBデータ |
| 0 | 0 | 0 | 0 | 1 | 0 | PC | PC | PC | PC | port C, ポートCデータ |
| 0 | 0 | 0 | 0 | 1 | 1 | PD | PD | PD | PD | port D, ポートDデータ |
| 0 | 0 | 0 | 1 | 0 | 1 | PF | PF | PF | PF | port F, ポートEデータ |
| 0 | 0 | 0 | 1 | 1 | 0 | MKH | MKH | MKH | MKH | mask high, 割り込みマスクレジスタ上位 |
| 0 | 0 | 0 | 1 | 1 | 1 | MKL | MKL | MKL | MKL | mask low, 割り込みマスクレジスタ下位 |
| 0 | 0 | 1 | 0 | 0 | 1 | SMH | SMH | SMH | SMH | serial mode high, シリアルモードレジスタ上位 |
| 0 | 0 | 1 | 0 | 1 | 0 | SML | - | - | - | serial mode low, シリアルモードレジスタ下位 |
| 0 | 0 | 1 | 0 | 1 | 1 | EOM | EOM | EOM | EOM | timer/event counter output mode,
タイマ・イベントカウンタ出力モードレジスタ |
| 0 | 0 | 1 | 1 | 0 | 0 | ETMM | - | - | - | timer/event counter mode,
タイマ・イベントカウンタモードレジスタ |
| 0 | 0 | 1 | 1 | 0 | 1 | TMM | TMM | TMM | TMM | timer mode, タイマモードレジスタ |
| 0 | 0 | 1 | 1 | 1 | 0 | - | PT | - | PT | port T, コンパレータ入力ポートTデータ |
| 0 | 1 | 0 | 0 | 0 | 0 | MM | - | - | - | memory mapping, メモリ割り付けレジスタ |
| 0 | 1 | 0 | 0 | 0 | 1 | MCC | - | - | - | mode control C, モードコントロールC |
| 0 | 1 | 0 | 0 | 1 | 0 | MA | - | - | - | mode A, ポートAモード |
| 0 | 1 | 0 | 0 | 1 | 1 | MB | - | - | - | mode B, ポートBモード |
| 0 | 1 | 0 | 1 | 0 | 0 | MC | - | - | - | mode C, ポートCモード |
| 0 | 1 | 0 | 1 | 1 | 1 | MF | - | - | - | mode F, ポートFモード |
| 0 | 1 | 1 | 0 | 0 | 0 | TXB | - | - | - | Tx buffer, シリアル送信バッファ |
| 0 | 1 | 1 | 0 | 0 | 1 | - | RXB | - | - | Rx buffer, シリアル受信バッファ |
| 0 | 1 | 1 | 0 | 1 | 0 | TM0 | - | - | - | timer register 0, タイマレジスタ0 |
| 0 | 1 | 1 | 0 | 1 | 1 | TM1 | - | - | - | timer register 1, タイマレジスタ1 |
| 1 | 0 | 0 | 1 | 0 | 0 | WDM | WDM | - | - | watchdog timer mode,
ウォッチドッグタイマモードレジスタ |
| 1 | 0 | 0 | 1 | 0 | 1 | MT | - | - | - | mode T, ポートTモード |
| U | sr3 | レジスタの役割 |
| 0 | ETM0 | timer/event counter register 0, タイマ・イベントカウンタレジスタ0 |
| 1 | ETM1 | timer/event counter register 1, タイマ・イベントカウンタレジスタ1 |
| V1 | V0 | sr4 | レジスタの役割 |
| 0 | 0 | ECNT | timer/event counter upcounter, タイマ・イベントカウンタのアップカウンタ |
| 0 | 1 | ECPT0 | timer/event counter capture 0, タイマ・イベントカウンタのキャプチャレジスタ0 |
| 1 | 0 | ECPT1 | timer/event counter capture 1, タイマ・イベントカウンタのキャプチャレジスタ1 |
レジスタペアの指定には、rp, rp1, rp2, rp3の4種類のグループがあり、それぞれ次の表に記入されているレジスタペアを含みます。この表でSP / SPと記載されている欄は、前の方がアセンブリ言語表記で後の方が実際のレジスタペアを表します。つまりB / BCの項はアセンブリ言語でBと書くことになっていて、実際の操作対象がBCレジスタペアであることを示します。
| P2 | P1 | P0 | rp | rp1 | rp2 | rp3 |
| 0 | 0 | 0 | SP / SP | V / VA | SP / SP | - |
| 0 | 0 | 1 | B / BC | B / BC | B / BC | B / BC |
| 0 | 1 | 0 | D / DE | D / DE | D / DE | D / DE |
| 0 | 1 | 1 | H / HL | H / HL | H / HL | H / HL |
| 1 | 0 | 0 | - | EA / EA | EA / EA | - |
アドレッシングモードの指定にはrpa, rpa1, rpa2, rpa3の3種類があります。rpa3は16 bitオペランド用のアドレッシングモードで、それ以外は8 bitオペランド用のアドレッシングモードです。ここでも/の左がアセンブリ言語表記で、/の右が実際の動作を意味します。ZilogのZ80 CPU的表記に慣れると省略し過ぎで変な表記と感じるかもしれませんが、Intel式の8080アセンブリ言語表記はこのようなものでしたから。
| A3 | A2 | A1 | A0 | rpa | rpa1 | rpa2 | rpa3 | 動作 |
| 0 | 0 | 0 | 0 | - | - | - | - | - |
| 0 | 0 | 0 | 1 | B / (BC) | B / (BC) | B / (BC) | - | BCポインタ |
| 0 | 0 | 1 | 0 | D / (DE) | D / (DE) | D / (DE) | D / (DE) | DEポインタ |
| 0 | 0 | 1 | 1 | H / (HL) | H / (HL) | H / (HL) | H / (HL) | HLポインタ |
| 0 | 1 | 0 | 0 | D+ / (DE)+ | - | D+ / (DE)+ | D++ / (DE)++ | DEオートインクリメント |
| 0 | 1 | 0 | 1 | H+ / (HL)+ | - | H+ / (HL)+ | H++ / (HL)++ | HLオートインクリメント |
| 0 | 1 | 1 | 0 | D- / (DE)- | - | D- / (DE-) | - | DEオートデクリメント |
| 0 | 1 | 1 | 1 | H- / (HL)- | - | H- / (HL)- | - | HLオートデクリメント |
| 1 | 0 | 1 | 1 | - | - | D+byte / (DE+byte) | D+byte / (DE+byte) | DEベース定数オフセット |
| 1 | 1 | 0 | 0 | - | - | H+A / (HL+A) | H+A / (HL+A) | HLベースAオフセット |
| 1 | 1 | 0 | 1 | - | - | H+B / (HL+B) | H+B / (HL+B) | HLベースBオフセット |
| 1 | 1 | 1 | 0 | - | - | H+EA / (HL+EA) | H+EA / (HL+EA) | HLベースEAオフセット |
| 1 | 1 | 1 | 1 | - | - | H+byte / (HL+byte) | H+byte / (HL+byte) | HLベース定数オフセット |
SK命令とSKN命令で使われるフラグオペランドfにはPSW中に含まれる次の3種類があります。
| F2 | F1 | F0 | f |
| 0 | 0 | 0 | - |
| 0 | 1 | 0 | CY |
| 0 | 1 | 1 | HC |
| 1 | 0 | 0 | Z |
| F4 | F3 | F2 | F1 | F0 | irf | ビット略称 | フラグの役割 |
| 0 | 0 | 0 | 0 | 0 | FNMI | INTFNMI | NMI*端子の状態を表す |
| 0 | 0 | 0 | 0 | 1 | FT0 | INTFT0 | タイマ0のコンパレータ一致信号でセット |
| 0 | 0 | 0 | 1 | 0 | FT1 | INTFT1 | タイマ1のコンパレータ一致信号でセット |
| 0 | 0 | 0 | 1 | 1 | F1 | INTF1 | INT1端子への立ち上がりエッジ入力でセット |
| 0 | 0 | 1 | 0 | 0 | F2 | INTF2 | INT2*端子への立ち下がりエッジ入力でセット |
| 0 | 0 | 1 | 0 | 1 | FE0 | INTFE0 | タイマ・イベントカウンタのECNTとETM0レジスタ一致でセット |
| 0 | 0 | 1 | 1 | 0 | FE1 | INTFE1 | タイマ・イベントカウンタのECNTとETM1レジスタ一致でセット |
| 0 | 0 | 1 | 1 | 1 | FEIN | INTFEIN | タイマ・イベントカウンタのCI入力かTOの立ち下がりエッジでセット |
| 0 | 1 | 0 | 0 | 1 | FSR | INTFSR | シリアルの受信バッファフルでセット |
| 0 | 1 | 0 | 1 | 0 | FST | INTFST | シリアルの送信バッファエンプティでセット |
| 0 | 1 | 0 | 1 | 1 | ER | ER | シリアルのパリティ、フレーム、オーバーラン受信エラーでセット |
| 0 | 1 | 1 | 0 | 0 | OV | OV | タイマ・イベントカウンタのECNTオーバーフローでセット |
| 0 | 1 | 1 | 1 | 1 | IEF2 | IEF2 | NMI受付時に割り込み許可状態ならセット |
| 1 | 0 | 1 | 0 | 0 | SB | SB | Vdd端子の立ち上がり入力でセット |
I/O機能の手がかりとして、まずピン配置を次に示します。
PA0 1 64 Vcc
PA1 2 63 Vdd
PA2 3 62 PD7/AD7
PA3 4 61 PD6/AD6
PA4 5 60 PD5/AD5
PA5 6 59 PD4/AD4
PA6 7 58 PD3/AD3
PA7 8 57 PD2/AD2
PB0 9 56 PD1/AD1
PB1 10 55 PD0/AD0
PB2 11 54 PF7/AB15
PB3 12 53 PF6/AB14
PB4 13 52 PF5/AB13
PB5 14 51 PF4/AB12
PB6 15 50 PF3/AB11
PB7 16 49 PF2/AB10
PC0 17 48 PF1/AB9
PC1 18 47 PF0/AB8
PC2 19 46 ALE
PC3 20 45 WR*
PC4 21 44 RD*
PC5 22 43 HLDA
PC6 23 42 HOLD
PC7 24 41 PT7
NMI* 25 40 PT6
INT1 26 39 PT5
MODE1 27 38 PT4
RESET* 28 37 PT3
MODE0 29 36 PT2
X2 30 35 PT1
X1 31 34 PT0
Vss 32 33 Vth
PA, PB, BC, PD, PFはuPD7808などROM内蔵型では双方向のI/Oポートであり、PTはコンパレータ入力ポートです。ただしuPD7807はPDポートをデータ入出力と下位アドレス出力端子として使用し、PFポートの一部あるいは全部を上位アドレス出力端子として使用します。
NMI*はノンマスカブル割り込みでネガティブエッジトリガの入力信号です。
INT1はポジティブエッジトリガの割り込み入力です。さらにACゼロクロス入力や16
bitタイマ・カウンタのトリガ源としても使えるようになっています。
MODE1とMODE0はuPD7807の外付けメモリ容量を決定する入力端子で、設定によって4
KByte, 16 KByte, 64 KByteのモードになります。それに従って上位アドレス出力端子として使用されるPFポートの信号本数が決まります。つまり4
KByteモードのときにはPF0からPF3までがアドレス出力端子、PF4からPF7までが入出力ポートとして使用され、16
KByteモードのときにはPF0からPF5までがアドレス出力端子でPF6, PF7が入出力ポートになり、64
KByteモードのときにはPF0からPF7まですべてがアドレス出力端子となります。MODE1とMODE0はリセット時に1が入力されていると出力端子としても使われるようですが、詳細はわかりません。設定時には電源に直接接続するのではなく、抵抗を介してプルアップすべきでしょう。uPD7809の場合にはMODE0をLに、MODE1をHに設定します。
RESET*はシステムリセット入力端子で、X1とX2は水晶振動子とコンデンサを接続する端子でクロック信号発生を行います。
VthはPTポート用のスレッショルド電圧設定端子で、PT0 - PT7が各コンパレータの+入力に接続されているのに対し、VthはPT0
- PT7の8個のコンパレータすべての-入力に供給される電圧の設定端子です。ただし、Vthの電圧が直接コンパレータに接続されているわけではなく、16段階のプログラマブルな分圧回路を介して-入力に接続されています。
HOLDとHLDAはDMA用の端子で、RD*, WR*, ALEがIntelの8085と同じ形式のバスインターフェース信号です。ただし、8085と異なりI/Oアドレス空間が存在しませんから、IO/M*信号は存在しません。RD*,
WR*, ALEだけで外部メモリの読み書きを行います。
VccとVssが主電源で5 V単一電源、Vddが32 Byte分の内蔵RWMバックアップ用電源です。
概してピン配置は比較的規則正しく端子が並べられています。
では個別にポートを見ていきます。
PAとPBはビットごとに入出力方向を決められる比較的単純なI/Oポートです。それぞれMODE
Aレジスタ(MA)とMODE Bレジスタ(MB)という制御レジスタを持ち、そのレジスタの1になっているビットが入力端子に、0になっているビットが出力端子に設定されます。リセット時にはすべて1に初期設定されて強制的に入力となります。実際のデータの入出力に用いるレジスタは、それぞれPA,
PBレジスタです。PA, PBレジスタの読み込みで得られるデータのうち、端子が出力に設定されているビットに関しては、前もって各レジスタに書き込まれていた値となり、出力端子の状態を反映しない回路となっています。出力しているはずの状態が得られると言い換えても良いでしょう。
さて、PA, PB, MA, MBといったレジスタは、最初から存在しないI/Oポート空間に割り当てられているわけではなく、特殊レジスタ扱いになっています。そうして、特別な命令でアクセスされます。ただし、PAとMAが同じ種類の命令で操作されるのではなく、MAはMOV
MA, A命令でしか使用できないのに対し、PAはAレジスタと双方向のデータ転送を行えるほか、ビット操作命令でCYフラグとの演算や操作、さらにイミーディアトデータ演算命令でAレジスタに影響を与えずに各ビットのセットやリセット、テストも可能となっています。つまり、普通の使い方ならMA,
MBレジスタはリセット後の初期設定を行うだけか、せいぜい双方向データ通信のために設定しなおすだけなので、Aレジスタからのデータ書き込みだけしかできず、読み込みも含めたそれ以外の操作を省略してしまっています。逆にPAやPBレジスタは入出力のために頻繁にアクセスする必要があるため、広範な演算操作が可能です。慣れるまではどの命令が適用可能かたいへんですが、コード効率は良くなります。特にuCOM-87アーキテクチャではAレジスタの役割が大きいため、Aレジスタに影響を与えずに入出力を効率的に行えるのは便利です。たとえばORI
PA, DATAで、PAと8 bit定数データのDATAのORを行ってPAに書き込むことができ、PAの任意のビットをセットできます。また、ONI
PA, DATAでPAと8 bit定数データDATAのANDを行って、その結果が0でなければスキップを行うという形で、I/Oポートのテストが行えます。どちらの命令も、Aレジスタをはじめとする汎用レジスタは変化しません。何かの機器に組み込まれるコンピュータは、モータや何かの回路のオンオフのためとかセンサの状態確認のため、ビットごとに頻繁に入出力する場面が数多くあります。そんなとき、I/Oへの直接操作がこれだけ簡単に行える命令体系というのは、実用上は便利です。
PCもPAやPBと同じようにビットごとに入出力方向を決められるI/Oポートですが、他の内蔵回路との端子の共用が行われて、少し複雑になっています。MODE
Cレジスタ(MC)とMODE CONTROL Cレジスタ(MCC)の設定により、次のように機能が割り振られます。
| 端子 | MCC = 1, MC = X | MCC = 0, MC = 0 | MCC = 0, MC = 1 |
| PC0 | TxD出力 | 出力 | 入力 |
| PC1 | RxD入力 | 出力 | 入力 |
| PC2 | SCK*入出力 | 出力 | 入力 |
| PC3 | INT2*/TI入力 | 出力 | 入力 |
| PC4 | TO出力 | 出力 | 入力 |
| PC5 | CI入力 | 出力 | 入力 |
| PC6 | CO0出力 | 出力 | 入力 |
| PC7 | CO1出力 | 出力 | 入力 |
つまりMCCのあるビットが1になっていると、それに対応するPCの端子がタイマ、カウンタ、シリアル入出力インターフェースなどの内蔵回路の入出力端子になり、0なら一般のポート入出力端子となってPAなどと同じようにMCレジスタとPCレジスタで操作できます。リセット時にはMCCはすべて0クリアされ、MCはすべて1にセットされて、各信号端子は入力ポートモードに初期化されます。例によってPCレジスタだけはデータ転送や演算などで特別扱いされて多くの命令で操作できます。
PDはuPD7807ではデータやアドレスの入出力端子専用に使われていて、I/Oポートとしては使用できません。uPD7809でシングルチップモードで動作させる場合には、MMレジスタの設定によってバイト単位で入出力方向を決められます。PFに関しては、外付けするメモリのサイズに応じて、一部をI/Oポートとして使用することができます。そのような端子に限り、MODE
Fレジスタ(MF)とPFレジスタでPAと同様の入出力操作を行えます。
最後に残ったのがPTで、入力専用のポートです。PT0からPT7までの入力端子のほか、基準電圧設定用の入力端子Vthがあります。PT入力には個別にアナログコンパレータとラッチが用意されていて、アナログコンパレータの+入力にPT端子が接続されています。すべてのアナログコンパレータの-入力には、Vthを分圧したものが接続されています。分圧レベルはMODE
Tレジスタ(MT)の下位4 bitでプログラムでき(MTの上位4 bitは未使用)、Vthの16/16から1/16までの16段階の電圧を与えられるようになっています。アナログコンパレータの出力にはラッチ回路が接続されていて、読み込み時のばたつきによる誤動作を回避しているようです。1回の比較には48ステート必要としますから、端子の新しい状態を読み込めるまで最悪96ステートかかります。12
MHzクロックで24 usですね。基準電圧が8本の入力について共通というところが扱いにくいかもしれませんが、うまく使えば簡易A/Dコンバータ代わりに使えるかもしれません。そのほか、TTLレベルでないロジック信号的なもの、たとえばある種のセンサからの信号を入力する場合なんかには便利です。もちろん基準電圧を1.4
V程度に設定すれば、少々遅いけれども普通のTTLレベル入力としても使えるでしょう。PTレジスタも各ビットのテストなどさまざまな命令を利用できます。
パラレル入出力以外の内蔵I/Oとして、8 bitタイマ2回路、16 bitのタイマ・イベントカウンタ1回路、シリアルインターフェース1回路、あとI/Oではありませんがウオッチドッグタイマ回路が内蔵されています。レジスタの詳細にまで踏み込むと煩雑すぎるし、図を書かなくてはいけないので、簡単に済ませます。
8 bitタイマ回路はアップカウンタで、設定値と一致したらリセットして0からカウントを再び開始するようなプログラマブルなタイマです。設定値と一致したときには割込みを発生させることもできるし、出力フリップフロップを反転させることもでき、そのフリップフロップの出力をPC4/TO出力に出力したり、タイマ・イベントカウンタやウオッチドッグタイマのクロック入力に接続したり、シリアルインターフェースのビットレートクロックとして使用することもできます。ただし、出力フリップフロップはふたつのタイマに共通のものがひとつあるだけで、どちらかのタイマ出力として使用する場合、もう一方のタイマは割り込み発生源にしか使えません。タイマのクロック入力は内部クロック周波数2種類とPC3/TI入力の切り替えですが、一方のタイマだけ、もう一方の一致出力をクロック入力として使用でき、1本の16
bitタイマとして使用できるようにもなっています。
16 bitのタイマ・イベントカウンタ回路は、インターバルタイマ、外部イベントカウンタ、周波数測定、パルス幅測定、プログラマブル矩形波出力、ワンパルス出力の6種類の機能を持つ多目的カウンタです。関係する端子はPC5/CI入力、PC6/CO0出力、PC7/CO1出力の3種類で、CI入力がHになっている時間を測定したり、CO0とCO1に位相差付きのタイミング信号を出力したりできます。
シリアルインターフェースは、調歩同期モード、同期モード、I/Oインターフェースモードの3種類の動作モードがあります。共にビットレートは内部固定クロックを使用することもタイマ出力を使用することも外部から供給することも可能です。調歩同期モードでは、7
bit/8 bitデータの切り替え、パリティの有無と偶奇の設定、1/2ストップビットの設定が可能で、それなりの機能をもっています。同期モードでは、さすがに同期キャラクタの判定までは行ってくれませんが、同期キャラクタを見つけるための1
bit受信単位での割り込みモードも持っていて、ソフトウェア併用で同期確立を行えるようになっています。I/OインターフェースモードはMotorolaでいうSPIのようなインターフェースで、シフトレジスタのようなものをI/Oとして利用できるモードです。同期モードとはビットを送りだす順序がLSBからではなくてMSBからであるところが特に異なります。
Return to IC Collection