
写真の上側は発表年と同じ1979年製です。しかもP6Fマスクで、このP6FマスクはG7F, T5A, T6Mマスクと共にMRDYの入力タイミングに問題がある(クロック信号との同期回路を外付けしないと誤動作する)ことが公表されている、きわめて初期の製品です。下はプラスチックパッケージで2 MHzクロック品。2 MHzクロック版は1980年発表ですが、これは1981年ものですね。
究極の8 bit CPUとして発表されたMC6809は、あの16 bit CPUであるMC68000と同じ1979年にMotorola社から発表されました。MC6800とはアセンブラレベルで(多少のマクロ定義を行えば)上位互換性があるようになっていますが、バイナリレベルでは互換性がありません。そのかわり、下手な16 bit CPUより豊富なアドレッシングモードを備え、複数のインデックスレジスタが使える上に強力な16 bit演算命令も加わり、確かに優れた8 bit CPUでした。
写真の上側は発表年と同じ1979年製です。しかもP6Fマスクで、このP6FマスクはG7F, T5A, T6Mマスクと共にMRDYの入力タイミングに問題がある(クロック信号との同期回路を外付けしないと誤動作する)ことが公表されている、きわめて初期の製品です。下はプラスチックパッケージで2 MHzクロック品。2 MHzクロック版は1980年発表ですが、これは1981年ものですね。
レジスタ構成はポインタレジスタを中心にMC6800よりも大幅に強化されています。
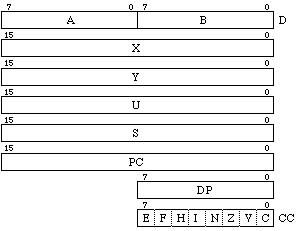
AccAとAccBはA, Bレジスタのままですが、A, Bをペアにして16 bit幅のレジスタとして扱うことができ、その場合はDレジスタと呼ばれます。Dレジスタに対しては加減算などが可能になっています。X, Y, U, Sがポインタレジスタ群で、SがMC6800のSPに相当して、ハードウェアスタックポインタと呼ばれます。XとYはMC6800のIXに相当するインデックスレジスタで、MC6800の欠点であった1本だけのインデックスレジスタの問題が解決されたわけですが、実はUもSもインデックスレジスタとして使えるようになっていて、まぁSはサブルーチンや割り込みの都合で自由に使えませんから、実質はインデックスレジスタが3本になったといえるわけです。しかも加算だけならLEA命令でポインタレジスタを16 bitアキュムレータとして使用できます。Z80では16 bitの加減算が可能でMC6800は少々面倒だったのが、これでずっと便利になりました。Uレジスタはユーザスタックポインタで、Sと同じようにレジスタのプッシュやポップが可能など、スタックポインタの機能が付いている他はXやYと変わりありません。ユーザが自由に使えるスタックポインタであり、インデックスレジスタにもなります。PCはプログラムカウンタで従来と変わりありません。DPはダイレクトページレジスタで、MC6800のゼロページの拡張を行います。MC6800ではゼロページアドレッシングといって、$00から$FFまでは1 Byteのアドレス部で直接アドレッシングできました。2 Byte必要なアドレス指定の上位1 Byteを0に固定することで、短いアドレス表現を可能にしていたわけです。MC6809では、そのアドレス上位8 bitを0に固定しないで、DPの内容が使われます。つまり、64 KByteのアドレス空間の任意のページを直接指定できるようになっています。そこで、ダイレクトページレジスタなわけです。フラグ類が納められたコンデションコードレジスタ(CC)は上位2 bitがMC6800より拡張されています。FはFIRQマスクビットで、新設された高速割り込み信号のマスクです。EはEntireフラグで割り込み時にスタックに退避されたCPU内コンテキストの内容が、NMI, IRQとFIRQとで異なるため、その識別に使われます。
アドレッシングモードには大きく分けると次の9種類となります。
インヘレント
イミディエート
エクステンド
エクステンド間接
ダイレクト
レジスタ
インデックス
インデックス間接
プログラムカウンタ相対
この中でもインデックスとインデックス間接アドレッシングには多数のバリエーションがあり、8 bitマイクロプロセッサとしては異常なほどの高機能となっています。ただし、そのためにインデックスアドレッシングや間接アドレッシング関係ではアドレッシングモードを指定するためにオペコードとは別にポストバイトと呼ばれる1 Byteのコードが命令に付加されます。その分、平均命令長が長くなったり、同じ命令でもアドレッシングモードによって命令実行クロック数が大幅に変化するなど、ありがたくないことも生じます。
このアドレッシングモードの中でインヘレント、イミディエート、エクステンドの3種類についてはMC6800と同様です。
エクステンド間接は最初にエクステンドアドレッシングと同じようにオペランドの16 bit絶対アドレスから2 Byteのデータを読み出して、そのデータで指されているアドレスのデータを操作対象にするアドレッシングモードです。インデックスアドレッシングと同様にポストバイトでアドレッシングモードを指定する仕組みになっています。
ダイレクトアドレッシングはMC6800ではゼロページアドレッシングでしたが、レジスタの項で説明したようにDPレジスタでアドレスの上位バイトを指定し、1 Byteのオペランドでアドレス下位バイトを指示するアドレッシングモードに改良されています。
レジスタアドレッシングは、レジスタがオペランドという点ではインヘレントアドレッシングの一部と似ていますが、複数のレジスタをオペランドに持ち、そのレジスタを指定する専用のポストバイトを持っているという点が異なります。PSHU, PSHS, PULU, PULS, EXG, TFR命令だけがこのモードを持ちます。
次はインデックスアドレッシングとインデックス間接アドレッシングの番ですが、先にプログラムカウンタ相対を扱っておきます。このプログラムカウンタ相対アドレッシングには、MC6800と同様に分岐命令として相対アドレッシング専用の命令群が用意されています。このほかに、インデックスアドレッシングでインデックスレジスタの代わりにプログラムカウンタを使用する、インデックスアドレッシングの変種としてのプログラムカウンタ相対アドレッシングモードも存在していて、インデックスアドレッシング可能な命令なら自由に使えるようになっています。相対アドレッシング専用の分岐命令についてもMC6800と比べて強化されています。MC6800の相対アドレッシングは8 bitオフセットで、比較的近距離の分岐にしか使えませんでした。MC6809の分岐命令の相対アドレッシングは8 bitオフセットのほか16 bitオフセットも可能になっていて、16 bitの全アドレス空間をカバーできるようになっています。
さて、残されたインデックスアドレッシングやその間接アドレッシングの詳細については、ポストバイトとの対応表として説明します。
アドレッシングモード |
直接アドレッシング Post Byte Asm. ~ # |
間接アドレッシング Post Byte Asm. ~ # |
| Rインデックス オフセットなし |
1RR00100 ,R 0 0 |
1RR10100 [,R] 3 0 |
| Rインデックス 5 bitオフセット |
0RRnnnnn n,R 1 0 |
-- |
| Rインデックス 8 bitオフセット |
1RR01000 n,R 1 1 |
1RR11000 [n,R] 4 1 |
| Rインデックス 16 bitオフセット |
1RR01001 n,R 4 2 |
1RR11001 [n,R] 7 2 |
| Rインデックス Aレジスタオフセット |
1RR00110 A,R 1 0 |
1RR10110 [A,R] 4 0 |
| Rインデックス Bレジスタオフセット |
1RR00101 B,R 1 0 |
1RR10101 [B,R] 4 0 |
| Rインデックス Dレジスタオフセット |
1RR01011 D,R 4 0 |
1RR11011 [D,R] 7 0 |
| Rインデックス オートインクリメント +1 |
1RR00000 ,R+ 2 0 |
-- |
| Rインデックス オートインクリメント +2 |
1RR00001 ,R++ 3 0 |
1RR10001 [,R++] 6 0 |
| Rインデックス オートデクリメント -1 |
1RR00010 ,-R 2 0 |
-- |
| Rインデックス オートデクリメント -2 |
1RR00011 ,--R 3 0 |
1RR10011 [,--R] 6 0 |
| PC相対 8 bitオフセット |
1xx01100 n,PCR 1 1 |
1xx11100 [n,PCR] 4 1 |
| PC相対 16 bitオフセット |
1xx01101 n,PCR 5 2 |
1xx11101 [n,PCR] 8 2 |
| エクステンド間接 |
-- |
10011111 [n] 5 2 |
この表は各アドレッシングモードの、直接アドレッシングと間接アドレッシングのそれぞれについて、ポストバイト、アセンブリ言語における表記法(Asm.)、命令の実行サイクルに加算されるべきアドレッシング処理に必要なクロック数(~)、同じくオペコードとポストバイト以外に必要なバイト数(#)を並べたものです。"--"とだけ書き込まれている欄は、そこに対応するアドレッシングモードが存在しないことを意味します。
この表でアドレッシングモードとアセンブリ言語表記の欄で使われているRとはX, Y, U, Sのいずれかを意味します。アセンブリ言語表記でnとあるのは数値ですが、エクステンド間接以外のnは符号付き整数を意味します。エクステンド間接だけは無符号16 bit整数です。
ポストバイトの中のRRはインデックスレジスタを表す2 bitコードで、次のようになっています。
| レジスタ | RR |
| X | 00 |
| Y | 01 |
| U | 10 |
| S | 11 |
Rインデックス 5 bitオフセットのポストバイトに含まれるnnnnnは符号付き5 bitオフセットを表します。xxは任意のビットです。
普通の意味でのインデックス直接アドレッシングは、0オフセット固定のオフセットなしと、5 bitオフセット、8 bitオフセット、16 bitオフセットの4種類があります。0オフセットと5 bit以内で表現されるオフセットの場合は、ポストバイト以外にオフセット値を指定するコードを必要としません。命令サイズへの影響からするとオフセットなしも5 bitオフセットも同じなので、特別なオフセットなしのモードを用意する理由はなさそうですが、オフセットなしならオフセットを加算してアドレス計算する時間を省略できる点に違いがあります。
インデックス間接アドレッシングには5 bitオフセットのモードがありませんが、直接アドレッシングより使用頻度が少ないでしょうから、正しい判断でしょう。
インデックスアドレッシングのアキュムレータオフセットモードは、オフセットとしてA, B, Dレジスタのいずれかを利用できます。このモードの場合、新しめのプロセッサのように同時に定数を加算してアドレスを決めることはできません。直接アドレッシングも間接アドレッシングも同様に利用できます。
オートインクリメントモードとオートデクリメントモードはインデックスレジスタをポインタとして用いるついでにインクリメントやデクリメントを行うモードです。オフセットを与えることはできません。インクリメントはデータアクセス後に行うポストインクリメントで、デクリメントはデータアクセス前に行うプリデクリメントのため、ポストインクリメントとプリデクリメントを組み合わせてスタックデータ構造をX, Yインデックスレジスタでアクセスすることも簡単に行えます。もちろん、キューの操作にも使えますし、配列的なデータ構造の操作にも向いています。1 Byteデータアクセス用の1インクリメント・デクリメントのモードも、2 Byteデータアクセス用の2インクリメント・デクリメントのモードもあります。ただし、間接アドレッシングにおいては必ず2 Byte分のアドレスデータにアクセスしなくてはならないため、1インクリメント・デクリメントモードはありません。
PC相対アドレッシングはPCをインデックスレジスタの代わりに使用するモードで、8 bitオフセットモードと16 bitオフセットモードが存在します。アセンブラ表記では上の表でPCRを使用していますが、Motorolaのアセンブリ言語表記などではPCRとPCの2通りの書き方がありますので、少し注意が必要です。この違いは、オフセットのnの指定方法にあります。アセンブリ言語で普通はnとして数値を直接書くことはなくて、別に定義されたラベルやEQUで定義された記号名を使うと思います。SYMBOL,PCRと書くと、SYMBOLはラベル定義されたアドレスだと解釈して、アセンブル中の命令のアドレスを基準にオフセット値を自動的に求めてくれます。SYMBOL,PCと書くと、SYMBOLはPCに加算すべきオフセット値そのものと解釈されます。つまりLABEL,PCRはLABEL-*-n,PCと等しいことになります。ただし、ここで*はアセンブル中の命令の先頭アドレス、nはアセンブル中の命令のバイト数です。
エクステンド間接アドレッシングは先に書いた通りのアドレッシングモードです。
8 bitアキュムレータ関係の命令でメモリとの2項演算、あるいは8 bitのメモリ上のデータ操作に関する命令を最初に紹介します。ただしアキュムレータに対する単項演算はインヘレントアドレッシングモードに分類されて少数ですから、別の表にまとめます。
Mne. Imm. Direct Indexed Extended HNZVC 動作 ADCA 89 2 2 99 4 2 A9 4+ 2+ B9 5 3 ***** A + M + C -> A ADCB C9 2 2 D9 4 2 E9 4+ 2+ F9 5 3 ***** B + M + C -> B ADDA 8B 2 2 9B 4 2 AB 4+ 2+ BB 5 3 ***** A + M -> A ADDB CB 2 2 DB 4 2 EB 4+ 2+ FB 5 3 ***** B + M -> B ANDA 84 2 2 94 4 2 A4 4+ 2+ B4 5 3 **0 A & M -> A ANDB C4 2 2 D4 4 2 E4 4+ 2+ F4 5 3 **0 B & M -> B ASL 08 6 2 68 6+ 2+ 78 7 3 ?**** ASL(M) ASR 07 6 2 67 6+ 2+ 77 7 3 ?** * ASR(M) BITA 85 2 2 95 4 2 A5 4+ 2+ B5 7 3 **0 A & M BITB C5 2 2 D5 4 2 E5 4+ 2+ F5 5 3 **0 B & M CLR 0F 6 2 6F 6+ 2+ 7F 7 3 0100 0 -> M CMPA 81 2 2 91 4 2 A1 4+ 2+ B1 5 3 ?**** A - M CMPB C1 2 2 D1 4 2 E1 4+ 2+ F1 5 3 ?**** B - M COM 03 6 2 63 6+ 2+ 73 7 3 **01 ~M -> M DEC 0A 6 2 6A 6+ 2+ 7A 7 3 *** M - 1 -> M EORA 88 2 2 98 4 2 A8 4+ 2+ B8 5 3 **0 A ^ M -> A EORB C8 2 2 D8 4 2 E8 4+ 2+ F8 5 3 **0 B ^ M -> B INC 0C 6 2 6C 6+ 2+ 7C 7 3 *** M + 1 -> M LDA 86 2 2 96 4 2 A6 4+ 2+ B6 5 3 **0 M -> A LDB C6 2 2 D6 4 2 E6 4+ 2+ F6 5 3 **0 M -> B LSL 08 6 2 68 6+ 2+ 78 7 3 **** LSL(M) LSR 04 6 2 64 6+ 2+ 74 7 3 0* * LSR(M) NEG 00 6 2 60 6+ 2+ 70 7 3 ?**** -M -> M ORA 8A 2 2 9A 4 2 AA 4+ 2+ BA 5 3 **0 A | M -> A ORB CA 2 2 DA 4 2 EA 4+ 2+ FA 5 3 **0 B | M -> B ROL 09 6 2 69 6+ 2+ 79 7 3 **** ROL(M) ROR 06 6 2 66 6+ 2+ 76 7 3 **** ROR(M) SBCA 82 2 2 92 4 2 A2 4+ 2+ B2 5 3 ?**** A - M - C -> A SBCB C2 2 2 D2 4 2 E2 4+ 2+ F2 5 3 ?**** B - M - C -> B STA 97 4 2 A7 4+ 2+ B7 5 3 **0 A -> M STB D7 4 2 E7 4+ 2+ F7 5 3 **0 B -> M SUBA 80 2 2 90 4 2 A0 4+ 2+ B0 5 3 ?**** A - M -> A SUBB C0 2 2 D0 4 2 E0 4+ 2+ F0 5 3 ?**** B - M -> B TST 0D 6 2 6D 6+ 2+ 7D 7 3 **0 M - 0
この表は、ニーモニックと4種類のアドレッシングモードに関するオペコード、クロック数、バイト数の組、フラグ変化、命令動作の項目を、1行に順番に並べたものです。オペコードは16進数で表示しています。インデックスアドレッシングの欄のクロック数とバイト数は、先に示したアドレッシングモードの表に記入されていたクロック数とバイト数が加算されることになるため+の記号を付け足してあります。フラグは変化のないものについては空白が、演算結果によって0か1のどちらかが決まるものには*が、必ず0になるものには0、同様に必ず1になるものには1が、未定義のものには?が書き込まれています。
ここに示した命令は、一部アドレッシングモードに例外がありますが、ほとんどMC6800に対応する命令が存在して、オペコード自身も互換性があったりします。このことからもMC6800の流れを受け継ぐプロセッサであるとはっきりと思えます。もちろんインデックスアドレッシングのポストバイトなんか全然異なる機構ですけど。
あとMC6800の命令表と比較すると、ダイレクトアドレッシングやエクステンドアドレッシングの命令実行時間が1クロックずつ増えていたり、ちょっと意外な点が見つかります。もちろんインデックス操作が格段に容易になっているために、意味のあるコード全体の実行クロック数は少なくなるはずですが、個々の命令で遅くなっているものがあるなんて。
アキュムレータ関係の命令のうちインヘレントアドレッシングのものを以下にまとめました。
Mne. Inher. HNZVC 動作 ASLA 48 2 1 ?**** ASL(A) ASLB 58 2 1 ?**** ASL(B) ASRA 47 2 1 ?** * ASR(A) ASRB 57 2 1 ?** * ASR(B) CLRA 4F 2 1 0100 0 -> A CLRB 5F 2 1 0100 0 -> B COMA 43 2 1 **0* ~A -> A COMB 53 2 1 **0* ~B -> B DAA 19 2 1 **u* AのBCD補正 DECA 4A 2 1 *** A - 1 -> A DECB 5A 2 1 *** B - 1 -> B INCA 4C 2 1 *** A + 1 -> A INCB 5C 2 1 *** B + 1 -> B LSLA 48 2 1 ?**** LSL(A) LSLB 58 2 1 ?**** LSL(B) LSRA 44 2 1 ?**** LSR(A) LSRB 54 2 1 ?**** LSR(B) MUL 3D 11 1 * b A * B -> D NEGA 40 2 1 ?**** -A -> A NEGB 50 2 1 ?**** -B -> B ROLA 49 2 1 **** ROL(A) ROLB 59 2 1 **** ROL(B) RORA 46 2 1 ** * ROR(A) RORB 56 2 1 ** * ROR(B) TSTA 4D 2 1 **0 A - 0 TSTB 5D 2 1 **0 B - 0
フラグ変化でDAA命令のVフラグの項にはuとありますが、これは不定を意味します。また、MUL命令のCフラグの項にはbとありますが、このフラグは演算結果のうちのアキュムレータBのMSBと同一の値になります。
これらの命令もオペコードまでほとんどMC6800と同一です。目新しい命令といえば、MUL命令くらいでしょうか。MUL命令はAとBの内容の無符号乗算を行い、Dレジスタ、つまり同じAとBのペアに結果を格納します。
16 bitアキュムレータであるDレジスタ関係の命令を次に示します。
Mne. Imm. Direct Indexed Extended HNZVC 動作 ADDD C3 4 3 D3 6 2 E3 6+ 2+ F3 7 3 **** D + M -> D CMPD 1083 5 4 1093 7 3 10A3 7+ 3+ 10B3 8 4 **** D - M LDD CC 3 3 DC 5 2 EC 5+ 2+ FC 6 3 **0 M -> D STD DD 5 2 ED 5+ 2+ FD 6 3 **0 D -> M SUBD 83 4 3 93 6 2 A3 6+ 2+ B3 7 3 **** D - M -> D
Dレジスタはロード・ストアのほか加減算と比較が可能ですが、キャリー付きの演算はできません。多バイト長の演算は8 bit単位でオートインクリメントモードのアドレッシングを利用した方が応用しやすいってことでしょうか。
特徴的なオペコードがCMPD命令に見られます。たとえばCMPD命令のイミディエートアドレッシングのオペコードは1083と書かれていますが、これは$10という16進数の後に$83が続く2 Byteのオペコードを意味します。MC6809では命令やレジスタセットが増えたため、1 Byteのオペコードでは足りなくなって、一部に2 Byteオペコードの命令が存在します。この辺はZ80 CPUと似たようなものですね。$10の部分をプリバイトと呼ぶこともあります。よく比較してみると、CMPD命令のオペコードは、SUBD命令のオペコードに$10というプリバイトを付けたものであることがわかります。このようにして、命令を増やしているわけですね。
8 bitデータ操作命令と同じくインヘレントアドレッシングのものだけは別にしてありますが、実は1命令しかありません。
Mne. Inher. HNZVC 動作 SEX 1D 2 1 **0 Sign Extend B to A
BレジスタのMSBをAレジスタの全ビットにコピーする符号拡張命令です。つまりBレジスタの8 bit符号付き整数をDレジスタの符号付き整数に変換する命令です。
インデックスレジスタ関係の命令を以下に示します。
Mne. Imm. Direct Indexed Extended HNZVC 動作 CMPS 118C 5 4 119C 7 3 11AC 7+ 3+ 11BC 8 4 **** S - M CMPU 1183 5 4 1193 7 3 11A3 7+ 3+ 11B3 8 4 **** U - M CMPX 8C 4 3 9C 6 2 AC 6+ 2+ BC 7 3 **** X - M CMPY 108C 5 3 109C 7 3 10AC 7+ 3+ 10BC 8 4 **** Y - M LDS 10CE 4 4 10DE 6 3 10EE 6+ 3+ 10FE 7 4 **0 M -> S LDU CE 3 3 DE 5 2 EE 5+ 2+ FE 6 3 **0 M -> U LDX 8E 3 3 9E 5 2 AE 5+ 2+ BE 6 3 **0 M -> X LDY 108E 4 4 109E 6 3 10AE 6+ 3+ 10BE 7 4 **0 M -> Y LEAS 32 4+ 2+ EA -> S LEAU 33 4+ 2+ EA -> U LEAX 30 4+ 2+ * EA -> X LEAY 31 4+ 2+ * EA -> Y STS 10DF 6 3 10EF 6+ 3+ 10FF 7 4 **0 S -> M STU DF 5 2 EF 5+ 2+ FF 6 3 **0 U -> M STX 9F 5 2 AF 5+ 2+ BF 6 3 **0 X -> M STY 109F 6 3 10AF 6+ 3+ 10BF 7 4 **0 Y -> M
やはりプリバイトを使って命令を拡張しています。プリバイトが付いていれば、命令長が長くなりますし、プリバイトを読み込む分だけ命令実行クロック数も増加します。つまり効率的なプログラムを書くには、プリバイトのない命令を優先して利用すべきということがわかります。そのような観点から命令を観察すると、インデックスレジスタ類はできるだけXレジスタを使うことにすべきだということがわかります。順位を付けるとしたらX, U, Y, Sの順でしょうか。UはPSHU/PULU命令を利用できる点がX, Yと異なりますが、特にその必要がなければインデックスレジスタの一種でしかありませんから。
インデックスレジスタのインクリメントやデクリメントを行う命令が見当たりませんが、これはオートインクリメントモードがあるためでしょう。それにインデックスレジスタと定数との加減算はLEA命令で実行できます。
LEA命令はインデックスアドレッシングと同じポストバイトを取り、まずインデックスアドレッシングと同じアドレス計算を行います。一般の命令ならその計算されたアドレスをアクセスして何か実行するのですが、LEA命令ではメモリアクセスを行わずに計算したアドレスを指定したレジスタに入れてしまいます。たとえばLEAX 4,Xという命令なら、目的アドレスはX + 4となり、それをXに入れるわけですから、Xに4を加算する命令になります。もちろんインデックスアドレッシングのポストバイトならなんでも使えますから、LEAX D,YでXにD + Yの値をロードすることだってできるわけです。そういうわけで、LEA命令だけがあれば、インデックスレジスタとの加減算系の命令は不要です。LEAS, LEAU命令とLEAX, LEAY命令ではフラグ変化が異なるのに注意してください。後者ではZフラグだけは変化します。そのため、XとYレジスタはループカウンタなどとして利用することも可能です。
インヘレントアドレッシングのインデックスレジスタ関連命令はABX命令だけです。
Mne. Inher. HNZVC 動作 ABX 3A 3 1 B + X -> X
ABX命令はXにBを加算します。Bの内容は無符号整数として扱われます。符号拡張を行ってから加算するわけではありません。
レジスタアドレッシング関係の命令は、次の6命令が含まれます。これらの命令ではフラグが変化することはありません。
Mne. Register 動作 EXG 1E 8 2 R1 <-> R2 PSHS 34 5+ 2 Push registers on S stack PSHU 36 5+ 2 Push registers on U stack PULS 35 5+ 2 Pull registers from S stack PULU 37 5+ 2 Pull registers from U stack TFR 1F 6 2 R1 -> R2
EXG命令はふたつのレジスタの内容を入れ換える命令で、TFR命令はレジスタ間の転送命令です。LD命令やST命令はメモリとレジスタの転送命令で、レジスタ間のデータ転送はできません。MC6800ではアキュムレータがAとBだけ、インデックスレジスタはXだけでしたから、8 bitのレジスタ間データ転送はA, B間の転送であるTAB命令とTBA命令しか必要ではありませんでした。おっとCCRに対してTAP命令とTPA命令もありましたか。16 bitのレジスタはXの他にSPしかありませんから、16 bitの転送命令はTXS命令とTSX命令だけですね。MC6809では16 bitレジスタを中心に内部レジスタ数が大幅に増えましたから、レジスタ対固有の専用命令でなく、汎用の転送命令と、さらに交換命令を用意してあります。
PSHS, PSHU, PULS, PULUはSスタックとUスタックに対するプッシュ・プル命令です。MC6800では明示的にスタックに格納できるレジスタがAとBしかありませんでした。JSR命令でPCも格納されるしSWIではCCRもIXも確かに保存されるのですが、プログラム中でちょっとIXを待避させたいと思っても、スタックを利用するわけには行きませんでした。MC6809では、PSHS命令などを使わなくても、単独のレジスタをスタックに待避させるだけならSに対するプリデクリメントアドレッシングを用いたST命令で同じことができます。では、PSHS命令などの命令の存在意義はどこにあるのかというと、任意の複数の内部レジスタをいっぺんに待避させたり復帰させたりできることにあります。
これらの命令はポストバイトを必要とします。EXG命令とTFR命令はふたつのレジスタを指定するためのポストバイト、PSHS, PSHU, PULS, PULU命令は対象のレジスタ群を指定するためのポストバイトが必要です。では、まず前者のポストバイトから見ていきましょう。
EXG命令とTFR命令のポストバイトは上下4 bitずつに分割されています。上位4 bitが命令表の動作の項のR1を指定するもので、下位4 bitがR2を指定する部分にあたります。EXG命令ではR1とR2は同等ですが、TFR命令は転送元がR1で上位4 bit、転送先がR2で下位4 bitで指定されるレジスタです。では、各4 bitがどのレジスタを表すかというと、次の表のようになります。
| ビットパターン | 対応レジスタ |
| 0000 | D |
| 0001 | X |
| 0010 | Y |
| 0011 | U |
| 0100 | S |
| 0101 | PC |
| 1000 | A |
| 1001 | B |
| 1010 | CC |
| 1011 | DP |
ビットパターンは4 bitの二進数表記です。ビットパターンの最上位ビットが0なら16 bitレジスタ、1なら8 bitレジスタとなっています。EXG命令やTFR命令は、本来の命令の性質から、16 bitレジスタ同士、あるいは8 bitレジスタ同士での操作しか認めていません。上記以外のビットパターンや同時に8 bitと16 bitのレジスタを指定した場合には、動作は定義されていません。
TFR命令の対象レジスタにPCが含まれていますから、たとえばTFR D, PCとすることでDレジスタの内容で示されるアドレスへジャンプすることができます。これはインデックスアドレッシングを用いたJMP命令でも代替できない分岐命令です。このほか、DPに対して値を直接セットするLD命令は存在しませんから、一度Aレジスタなどに値を入れて、TFR A, DPなどとして値をセットするのにもTFR命令は使われます。
PSH, PUL系の命令に使われるポストバイトは各ビットごとにレジスタが割り当てられていて、あるビットが1なら対応するレジスタに対してのプッシュ・プル動作が行われ、0なら対応するレジスタには何もおきません。ポストバイトとレジスタの対応表は次のようになります。
| ビット | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| レジスタ | PC | U/S | Y | X | DP | B | A | CC |
表の中のビット6だけは説明が必要でしょう。このビットはPSHS, PULS命令ではUレジスタを、PSHU, PULU命令ではSレジスタを意味します。SスタックにSを格納するというのは無意味ですから、その場合にはUを意味し、Uスタックには逆のSレジスタというわけです。
このポストバイトから明らかなように、2 Byte命令のPSH命令ひとつだけで全レジスタを待避することも可能です。命令表の命令実行クロック数には5+とありますが、実際に必要なクロック数は[5 + (待避されるデータの総バイト数)]となります。
さらにスタックにプッシュされる順は次のようになっています。
| アドレス | データ |
| SP + 0 (下位アドレス) | CC |
| SP + 1 | A |
| SP + 2 | B |
| SP + 3 | DP |
| SP + 4 | X上位 |
| SP + 5 | X下位 |
| SP + 6 | Y上位 |
| SP + 7 | Y下位 |
| SP + 8 | U/S上位 |
| SP + 9 | U/S下位 |
| SP + 10 | PC上位 |
| SP + 11 | PC下位 |
| SP + 12 (上位アドレス) PSH命令直前のポインタ位置 |
-- |
この表は、全レジスタをスタックにプッシュした後のスタックの状態を表しています。MC6809のスタックポインタはプリデクリメント・ポストインクリメントの規則でメモリを指していますから、直前に保存したデータを指しています。スタックは利用できるメモリ領域の最上位アドレスから割り当てるのが普通ですから、スタックポインタの初期値は(利用できるメモリ領域の最上位アドレス + 1)になることにも注意してください。全レジスタをスタックにプッシュしない場合はプッシュされないレジスタが上の表から消えるだけで、順序が入れ替わるようなことはありません。これを見ると、ポストバイトのMSBから順に調べていってプッシュしているような順序ですね。
さて、PSH, PUL命令で待避・復元できるレジスタの中にPCが入っていて、特にPULされるときは最後にスタックから取り出されるという特徴から、一風変わったコードが良く使われることになりました。といっても、直接PCをプッシュするわけではありません。サブルーチンが呼び出されると、サブルーチンの中で使用するレジスタをスタックに待避させ、サブルーチンから戻る直前に復旧するということが良く行われます。このような場合、PUL命令でレジスタを復元したら、即座にRTS命令で呼び出した側に戻ることになります。ところでRTS命令というのはSスタックからのPCのプルですから、PULS PCという命令でも同じことができます。ただ単にRTS命令を置き換えるのでは、RTS命令は1 Byte命令なのにPULS PC命令は2 Byte命令になって効率的ではありません。しかし、サブルーチンの先頭で、たとえばPSHS A, B, X, Yなどとしていれば、RTS命令の直前にPULS A, B, X, Yが必要になります。このPULS命令のオペランドにさらにPCを付け加えて、PULS A, B, X, Y, PCという形にしてしまえば、RTS命令を省略できる分、1 Byteだけコードが短くなります。しかもPULS命令にPCを付け加えて増加する命令実行クロック数は2クロックであるのに対し、RTS命令には5クロック必要ですから、この点でも得をします。そんなわけで、RTS命令を省略したサブルーチンはMC6809では普通のテクニックとしてさかんに使われていました。
相対アドレッシングの命令を以下に示します。ほとんどが条件分岐命令です。
Mne. Relative 条件 BCC 24 3 2 C = 0 LBCC 1024 5/6 4 C = 0 BCS 25 3 2 C = 1 LBCS 1025 5/6 4 C = 1 BEQ 27 3 2 Z = 1 LBEQ 1027 5/6 4 Z = 1 BGE 2C 3 2 N ^ V = 0 LBGE 102C 5/6 4 N ^ V = 0 BGT 2E 3 2 Z | (N ^ V) = 0 LBGT 102E 5/6 4 Z | (N ^ V) = 0 BHI 22 3 2 C | Z = 0 LBHI 1022 5/6 4 C | Z = 0 BHS 24 3 2 C = 0 LBHS 1024 5/6 4 C = 0 BLE 2F 3 2 Z | (N ^ Z) = 1 LBLE 102F 5/6 4 Z | (N ^ Z) = 1 BLO 25 3 2 C = 1 LBLO 1025 5/6 4 C = 1 BLS 23 3 2 C | Z = 1 LBLS 1023 5/6 4 C | Z = 1 BLT 2D 3 2 N ^ V = 1 LBLT 102D 5/6 4 N ^ V = 1 BMI 2B 3 2 N = 1 LBMI 102B 5/6 4 N = 1 BNE 26 3 2 Z = 0 LBNE 1026 5/6 4 Z = 0 BPL 2A 3 2 N = 0 LBPL 102A 5/6 4 N = 0 BRA 20 3 2 Always LBRA 16 5 3 Alawys BRN 21 3 2 Never LBRN 1021 5 4 Never BSR 8D 7 2 (Branch to Subroutine) LBSR 17 9 3 (Branch to Subroutine) BVC 28 3 2 V = 0 LBVC 1028 5/6 4 V = 0 BVS 29 3 2 V = 1 LBVS 1029 5/6 4 V = 1
これらの命令でフラグは変化しません。命令実行クロック数に5/6とあるのは分岐しない場合に5クロック、分岐する場合に6クロックを消費するという意味です。
BCC命令とLBCC命令のように、先頭にLが追加されたニーモニックが存在しますが、16 bitオフセットを持つ命令を意味します。Lのない分岐命令は8 bitオフセットで、比較的近距離にしか分岐できませんが、L付きの16 bitオフセットなら全アドレス範囲に自由に分岐できます。この点もMC6800から強化されたところです。しかしL付きの命令は$10のプリバイトが付加されているものが多く、4 Byte命令で遅くなっています。もっとも条件分岐命令の場合には近距離への分岐がほとんどですから、それほど不便はありません。遠距離への分岐の可能性の比較的高い無条件分岐命令のLBRA命令やサブルーチン呼び出しのLBSR命令は3 Byte長になるように配慮されています。
よく見ると、BCS命令とBLO命令のように、条件やオペコードが同一なのに別のニーモニックが与えられている命令も存在します。これは、人が覚えやすい条件名になるようにニーモニックを決めたからというわけです。命令の意味を理解するため、メモリオペランドMをもつCMPA命令で数値を比較した場合を考えて、分岐命令ニーモニックを整理してみました。16 bitオフセットの命令は省略して、8 bitオフセットの命令ニーモニックだけ使っています。
| 条件 | 符号付き演算 | 符号なし演算 |
| A > M | BGT | BHI |
| A >= M | BGE | BHS |
| A == M | BEQ | BEQ |
| A != M | BNE | BNE |
| A <= M | BLE | BLS |
| A < M | BLT | BLO |
| OVF | BVS | -- |
| ! OVF | BVC | -- |
最後のふたつはオーバーフローの有無です。符号なしのデータに関してはオーバーフローは関係ありませんので、該当する命令はありません。符号付きの数の比較と符号なしの数の比較が異なるというのは、最近の高級言語ばかり利用する人にはわかりにくいかもしれませんが、たとえば$FCと$10を比較する場合を考えてみて下さい($は16進数を表す)。符号なしの数値なら、これらは252と16ですから、$FC > $10です。しかし2の補数で表される符号付き数値として解釈すると、それぞれ-4と16とを表していますから、$FC < $10となります。符号付き数値の比較はちょっと面倒なフラグ判定をしなくてはなりません。
この他に特定のフラグと結びついた単純分岐命令というものも存在します。それを表にしてみました。
| フラグ | F = 0 | F = 1 |
| Z | BNE | BEQ |
| N | BPL | BMI |
| C | BCC | BCS |
| V | BVC | BVS |
以上でMC6809の条件分岐命令をすべて網羅したことになります。
さらに無条件分岐命令というのがあります。BRA, LBRAはBranch Alwaysで、常に分岐する命令です。逆にBRN, LBRNはBranch Neverで、分岐しない分岐命令です。なんか矛盾している名前ですが、条件分岐命令で常に成立しない条件が選ばれたような意味になります。なんの役に立つのかというと普通は役に立たないのですが、多バイト長のNOP命令として利用されることもあるでしょう。このほか、BSR, LBSR命令はサブルーチン呼び出し用の無条件分岐命令です。
最後に残った命令をまとめて紹介します。もっとも表のサイズの関係でインヘレント命令だけは例によって別枠の表にまとめました。
Mne. Imm. Direct Indexed Extended HNZVC 動作 ANDCC 1C 3 2 ##### CC & imm -> CC CWAI 3C 20+ 2 ##### CC & imm -> CC, wait for interrupt ORCC 1A 3 2 ##### CC | imm -> CC JMP 0E 6 2 6E 3+ 2+ 7E 4 3 EA -> PC JSR 9D 7 2 AD 7+ 2+ BD 8 3 Jump to subroutine
ANDCC命令とORCC命令はフラグ類をまとめて操作するための命令です。フラグの欄に#とあるのは、演算結果の影響で変化するのではなく、命令の直接の結果で書き換わってしまうのを表しています。特にANDCC命令やORCC命令で変化させたいのは、おそらくF, I, Cフラグになるでしょう。割り込みマスク関係の操作とキャリフラグのセットやクリアですね。
CWAI命令はANDCC命令と同じことを行ったうえでSを除く全レジスタをスタックに待避させた後、割り込みを待ちます。先に割り込み時と同じようにスタックにレジスタを待避しておくため、この命令で待っているときの割り込み応答時間は短くてすみます。割り込みがくるまで、ずっと待ち続けるため、この命令の実行クロック数は20クロック以上の任意のクロック数ということになってしまうため、表では20+と表現されています。
JMP命令とJSR命令は一般のアドレッシングモードを利用できる分岐命令とサブルーチン呼び出し命令です。
本当の最後になったインヘレントモードの命令は以下の7種です。
Mne. Inher. HNZVC 動作 NOP 12 2 1 No operation RTI 3B 6/15 1 ##### Return from interrupt RTS 39 5 1 Return from subroutine SWI 3F 19 1 Software interrupt 1 SWI2 103F 20 2 Software interrupt 2 SWI3 113F 20 2 Software interrupt 3 SYNC 13 4+ 1 Synchronize to interrupt
NOP命令は何もしない命令ですが、この仲間として先に触れたようにBRN命令とLBRN命令が追加されています。
RTI命令は割り込みから復帰する命令で、スタックに待避されたレジスタを元に戻します。FIRQ割り込みとIRQ/NMI割り込みではスタックに待避されるレジスタ数が異なりますから、それに対応して命令実行クロック数が変化します。
RTS命令はサブルーチンから戻る命令です。
SWI, SWI2, SWI3命令はソフトウェア割り込みで、MC6800のSWI命令とほぼ同じものですが、さらに2命令が加わっています。これらの3命令は割り込みベクタが異なることと、割り込みマスクの操作が異なる点だけ差があります。特に割り込みマスクについては注意が必要かもしれません。SWI命令では自動的にFIRQもIRQも禁止した状態になります。SWI2, SWI3命令ではどちらのマスクも操作しません。したがって、SWI2, SWI3命令を実行する際のマスクの状態によっては、これらのサービスルーチン内部でFIRQ/IRQ割り込みが発生する可能性があります。
SYNC命令は割り込み待ちの命令ですが、少々ややこしい制御を行います。割り込み信号が3クロックサイクル以上アサートされていると、その割り込みがマスクされていなければ一般の割り込み処理に入ります。マスクされていれば、SYNC命令の次の命令からプログラムの実行を再開します。割り込み信号が3クロックサイクル未満のときには、やはりSYNC命令の次の命令から実行を再開します。この命令の応用ですが、SYNC命令をうまく使うと、周辺装置との高速のデータ転送を行えたりします。たとえば周辺機器からデータ転送要求が発生したときに短いパルス状の割り込み信号を発生させ、データ転送終了時にはプログラムでクリアされるまで割り込み信号を発生するような回路を用意しておきます。この周辺機器とのデータ転送ループ内でSYNC命令で待ち合わせを行えば、データ転送要求時には次の命令からループを繰り返し、データ転送時には割り込み処理によって転送終了処理を行えるようになります。小さなループでハードウェアの転送フラグをチェックする必要もなく、高速の転送に対応できるようになります。
以上でMC6809の全命令の解説を終わります。
次にMC6809とMC6809Eの違いを調べるついでにハードウェアの特徴を見ていきます。といっても、こちらはあまりMC6800と異なるわけではありません。
これがMC6809のピン配置です。
VSS 1 40 HALT* NMI* 2 39 XTAL IRQ* 3 38 EXTAL FIRQ* 4 37 RESET* BS 5 36 MRDY BA 6 35 Q VCC 7 34 E A0 8 33 DMA*/BREQ* A1 9 32 R/W* A2 10 31 D0 A3 11 30 D1 A4 12 29 D2 A5 13 28 D3 A6 14 27 D4 A7 15 26 D5 A8 16 25 D6 A9 17 24 D7 A10 18 23 A15 A11 19 22 A14 A12 20 21 A13
さすがにMC6800やMC6802とは異なる点が多くなっていて、アドレス信号やデータ信号も微妙にずれていますけど、大まかな傾向は一緒ですね。特筆すべきはFIRQ割り込み信号の追加、クロックジェネレータ内蔵でEクロックの他にQクロックを作成して外部回路とのタイミングが取りやすくなっていること、MRDYでクロックの延長を行える他、DMA*/BREQ*で高速でバスを明け渡してDMAを行いやすくなっているという3点ですかね。あ、BSとBA信号でバスの状態を判定できるのも少しはありがたいかな。
MC6809は水晶発振子を接続すれば必要なクロック信号を作成するようになっていましたが、クロック信号生成回路をなくして、外部からクロック信号を供給するようにしたのがMC6809Eです。一見、改悪のように思えますが、大規模な回路構成のコンピュータを作ろうとすると、CPUの生成する信号とわずかにタイミングのずれたクロック信号が必要となることがあり、それがCPUのクロック信号より少し遅れた信号なら遅延回路で生成することもできますが、わずかに早く変化する信号の場合には、CPUがクロックを生成する限りは正確につくることはできません。いっそそれくらいなら、各種のタイミングのずれたクロック信号を作るついでにCPU用のクロック信号も作成するような回路を作成して、そこからCPUにクロック信号を供給した方が、単純になります。言い換えると、MC6809ではプロセッサの出力するクロック信号に同期してシステムのタイミングを決定しているのに対し、MC6809Eではシステムの生成するクロック信号に同期してプロセッサも動作するのです。その結果、MC6809Eは複雑なタイミング関係を維持する必要のある大規模な応用に適しています。他にも、バスサイクル使用予告信号などが追加されて、外部回路でさまざまな細工ができるようになっています。具体的にピン配置を示しましょう。
VSS 1 40 HALT* NMI* 2 39 TSC# IRQ* 3 38 LIC# FIRQ* 4 37 RESET* BS 5 36 AVMA# BA 6 35 Q# VCC 7 34 E# A0 8 33 BUSY# A1 9 32 R/W* A2 10 31 D0 A3 11 30 D1 A4 12 29 D2 A5 13 28 D3 A6 14 27 D4 A7 15 26 D5 A8 16 25 D6 A9 17 24 D7 A10 18 23 A15 A11 19 22 A14 A12 20 21 A13
MC6809と異なる信号に#を付けておきました。EとQのクロックは名称が同じですが入力端子になっているので、注意してください。EとQは外部回路でストレッチできますので、MRDY信号が不要になっています。また水晶発振子の外付けも当然不要なので、BUSY, AVMA, LIC, TSCの4信号が新設されていますね。BUSYはリードモデファイライトバスサイクルの排他制御用の信号でマルチプロセッサ用。AVMAはバスサイクルの使用予告信号。LICはLast Instruction Cycleで多バイト命令の区切りがわかり、TSCでアドレスやデータ端子をスリーステート状態にできます。

MC6809Eの発表は1980年、MC68B09Eの発表は1981年です。従って写真中央のMC68B09Eは発表年に製造されていることがわかります。また、写真上のMC6809EのマスクセットはT6Rであり、中央のMC68B09Eのマスクと同じであることがわかります。同じマスクセットで1 MHzクロック品と2 MHzクロック品があることから、このクロック周波数違いのMC6809Eは、選別によって区別されているらしいことがわかります。写真下は日立のセカンドソース品です。
Returnto IC Collection